Utiliser le clustering pour le traitement du langage naturel (NLP)
Principes
Le traitement naturel du langage, (Natural Language Processing ou NLP en anglais), est une technologie permettant aux machines de comprendre le langage humain. Les algorithmes ont pour rôle d’identifier et d’extraire les règles du langage naturel, afin de convertir les données de langage non structuré sous une forme exploitable par les machines.
Les deux principales techniques utilisées pour le traitement naturel du langage sont l’analyse syntaxique et l’analyse sémantique. L’analyse syntaxique consiste à identifier de mots ou des chaînes de mots (expressions) appartenant à des listes prédéfinis. L’analyse sémantique consiste à identifier les règles grammaticales dans une phrase afin d’en déchiffrer le sens.
Utilisation du clustering
La plupart des techniques de traitement naturel du langage reposent sur le Deep Learning ou apprentissage profond. Mais ces algorithmes nécessite une grande quantité de données correctement annoté. Le clustering permet d’assister l’humain en matière d’annotation.
Pour cela, il faut convertir une suite de mots avec leur contexte (la phrase) en une représentation mathématique (un vecteur) qu’un algorithme pourra manipuler. Une fois cette étape réalisée, on pourra, alors, associer des phrases par similarité syntaxique et de procéder au clustering.
Le clustering consiste à répartir des phrases, images, etc.(que l’on représente sous forme de points)en différents groupes selon leur distance sémantique. Chaque cluster (ou groupe de points) regroupe donc des données (phrases, images…) ayant le même sens. Cette méthode étant non-supervisée, l’algorithme va devoir déterminer par lui même la meilleure façon de regrouper les points en différentes catégories.
Détecter des sujets dans un corpus
Pour découvrir les sujets sous-jacents à une collection de documents, la modélisation de sujets permet de trouver des termes significatifs liés par thème ( «sujets» ) dans les données textuelles non structurées.
La modélisation de sujet est une technique d’apprentissage automatique non supervisée capable de numériser un ensemble de documents, de détecter des modèles de mots et de phrases qu’ils contiennent et de regrouper automatiquement des groupes de terme (mots) et des expressions similaires qui caractérisent le mieux un ensemble de documents.
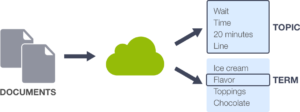
Avec la modélisation de sujets, vous pouvez attribuer à une instance donnée un score pour chaque sujet, qui indique la pertinence de ce sujet pour l’instance. Vous pouvez ensuite utiliser ces scores de rubrique comme fonctionnalités d’entrée pour entraîner d’autres modèles, comme point de départ pour le filtrage collaboratif ou pour évaluer la similitude des documents, parmi de nombreuses autres utilisations.
Il existe deux méthodes de modélisation de sujets.
- L’analyse sémantique latente (LSA) est basée sur ce qu’on appelle l’ hypothèse distributionnelle qui stipule que la sémantique des mots peut être appréhendée en regardant les contextes dans lesquels les mots apparaissent. En d’autres termes, sous cette hypothèse, la sémantique de deux mots sera similaire s’ils tendent se produire dans des contextes similaires.
- L’allocation de dirichlet latente (LDA) reposent sur les mêmes hypothèses sous-jacentes: l’hypothèse distributionnelle, (c’est-à-dire que des sujets similaires utilisent des mots similaires) et l’hypothèse de mélange statistique (c’est-à-dire que les documents parlent de plusieurs sujets) pour lesquelles une distribution statistique peut être déterminé. Le but de LDA est de faire correspondre chaque document de notre corpus à un ensemble de sujets qui couvre une bonne partie des mots du document.
Modélisation de sujet avec BigML
La démarche de la modélisation de sujet avec BigML est la suivante :

Pour réaliser la modélisation de sujet, BigML utilise algorithme d’ allocation de dirichlet latent. L’allocation de dirichlet latente (LDA) est une méthode d’apprentissage non supervisée qui découvre différents sujets sous-jacents à une collection de documents, où chaque document est une collection de mots ou de termes . LDA suppose que tout document est une combinaison d’un ou plusieurs sujets et que chaque sujet est associé à certains termes à forte probabilité.