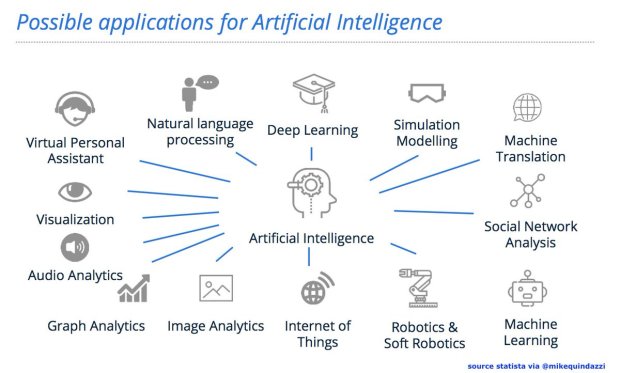
Enjeux du Big data
Nouvelles sources de données massives
Il n’y a plus besoin d’autant de ressources pour organiser la phase de collecte des données. On peut se focaliser directement sur le traitement et la valorisation des données stockées. Seules les étapes de préparation des données, le data munging, qui précèdent l’analyse, deviennent fondamentales car elles permettent la transformation des variables dans un format facilitant l’analyse et impactant la qualité des résultats.
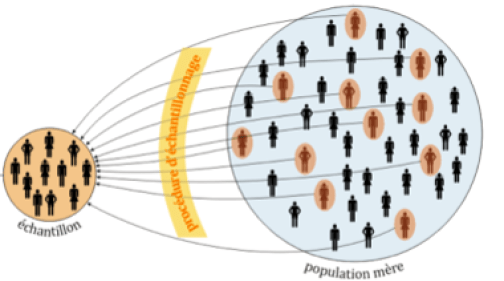
Analyse exhaustive d’une population
Ainsi, l’avènement des données massives rend accessible l’analyse exhaustive d’une population d’individus sans passer par une étape d’échantillonnage. Grâce aux évolutions technologiques, l’observation d’une population entière évite les biais dus aux techniques de sondages.
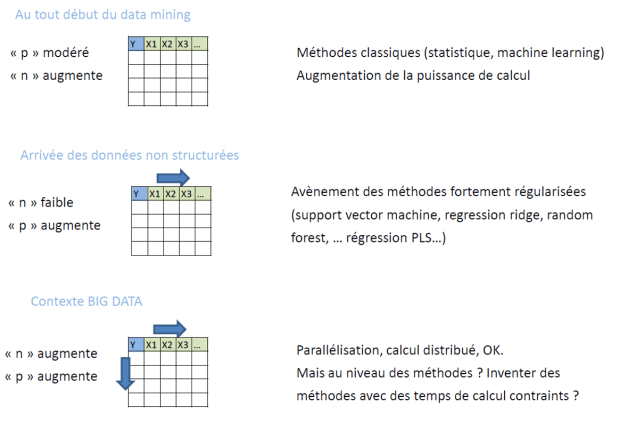
Changement de paradigme
Il arrive que le nombre p d’informations disponibles (e.g. des variables caractérisant un individu ou son comportement) devienne largement plus grand que la taille n des échantillons étudiés (nombre d’individus étudiés). Ce phénomène implique d’adapter les méthodes statistiques car il y a plus d’indétermination que d’information.
Validité scientifique
Les critères de reproductibilité et de réplication d’une analyse de données sont la condition de validité scientifique et d’amélioration des connaissances. Cette condition permet de s’affranchir d’effets aléatoires venant fausser les résultats ainsi que des erreurs de jugement ou des manipulations de la part des scientifiques.

Nouveaux outils
Les caractéristiques des données massives (variété, vélocité, etc.), obligent à utiliser de nouveaux outils et méthodes mathématiques pour minimiser les erreurs de prévisions. On assiste à l’importance des algorithmes et au développement de l’usage des techniques d’apprentissage automatique (machine learning) ou des modèles à base de courbes, surfaces ou graphes.