Évaluer un modèle
Démarche
Vous devez toujours évaluer un modèle pour déterminer s’il contribuera à prédire correctement la cible dans le cadre de nouvelles données à venir. Comme les instances futures ont des valeurs cibles inconnues, vous devez vérifier la métrique de précision du modèle d’apprentissage-machine sur des données dont vous connaissez déjà la réponse cible, puis utiliser cette évaluation comme indicateur de la précision prédictive des données futures.
Pour évaluer correctement un modèle, vous disposez d’un échantillon des données qui ont été étiquetées avec la cible (vérité du terrain) à partir de la source de données de formation. L’évaluation de la précision prédictive d’un modèle d’apprentissage-machine avec les mêmes données qui ont été utilisées pour la formation n’est pas utile. En effet, elle récompense les modèles qui peuvent « mémoriser » les données de formation, par opposition à une généralisation à partir de celles-ci. Une fois que vous avez terminé la formation du modèle d’apprentissage-machine, vous envoyez à ce modèle les observations mises de côté dont vous connaissez les valeurs cibles. Vous comparez alors les prédictions renvoyées par le modèle d’apprentissage-machine aux valeurs cibles connues. Enfin, vous calculez une métrique récapitulative indiquant la qualité de correspondance entre les valeurs prévues et les valeurs réelles.
Quelques métriques d’évaluation en apprentissage supervisé
Évaluation d’un modèle de régression
Le coefficient de détermination, également désigné sous le terme « R au carré », constitue également une méthode standard de mesure de l’adéquation entre le modèle et les données observées. Ce coefficient peut être considéré comme la proportion de la variance expliquée par le modèle. Dans ce cas précis, plus la proportion est élevée, meilleur est le résultat, la valeur 1 indiquant une adéquation parfaite.
l’erreur quadratique moyenne RMSE : En statistiques, l’erreur quadratique moyenne d’un estimateur, d’un paramètre, d’une dimension (mean squared error en anglais) est une mesure caractérisant la « précision » de cet estimateur. Pour calculer l’erreur quadratique moyenne RMS, les erreurs individuelles sont tout d’abord élevées au carré, puis additionnées les unes aux autres. On divise ensuite le résultat obtenu par le nombre total d’erreurs individuelles, puis on en prend la racine carrée. Cette erreur nous donne une mesure synthétique de l’erreur globale dans une seule valeur.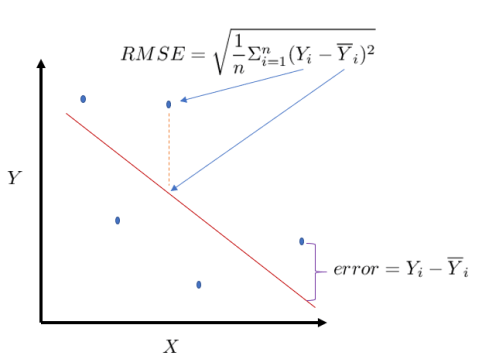
Évaluation d’un modèle de classification
La matrice de confusion : La matrice de confusion est un outil servant à mesurer la qualité d’un système de classification. Chaque colonne de la matrice représente le nombre d’occurrences d’une classe estimée, tandis que chaque ligne représente le nombre d’occurrences d’une classe réelle (ou de référence). Les occurrences utilisées pour chacune de ces 2 classes doivent être différentes. Un des intérêts de la matrice de confusion est qu’elle montre rapidement si un système de classification parvient à classifier correctement.
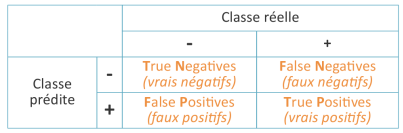
L’exactitude ou accuracy: C’est une mesure qui permet de valider (ou d’infirmer) un bon processus de classification en estimant le nombre d’erreur du modèle sur un échantillon test.
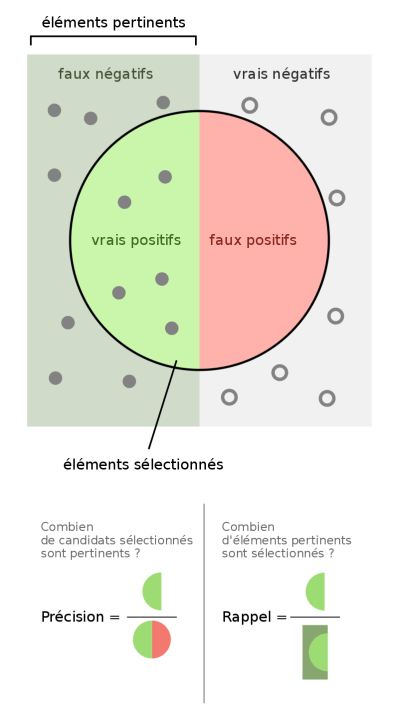
La précision : La précision est le nombre de documents pertinents retrouvés rapporté au nombre de documents total proposé par le moteur de recherche pour une requête donnée. Le principe est le suivant : quand un utilisateur interroge une base de données, il souhaite que les documents proposés en réponse à son interrogation correspondent à son attente. Tous les documents retournés superflus ou non pertinents constituent du bruit. La précision s’oppose à ce bruit documentaire. Si elle est élevée, cela signifie que peu de documents inutiles sont proposés par le système et que ce dernier peut être considéré comme “précis”.
Le rappel (ou sensibilité): Le rappel (recall en anglais) est défini par le nombre de documents pertinents retrouvés au regard du nombre de documents pertinents que possède la base de données. Cela signifie que lorsque l’utilisateur interroge la base, il souhaite voir apparaître tous les documents qui pourraient répondre à son besoin d’information. Si cette adéquation entre le questionnement de l’utilisateur et le nombre de documents présentés est importante alors le taux de rappel est élevé.
F mesure: C’est une mesure qui combine la précision et le rappel est leur moyenne harmonique, nommée F-mesure ou F-score.