Organiser un projet de data science
Principales étapes d’un projet de data science
La mise en place d’un projet de data science comprend notamment :
- la récupération des données utiles à l’étude
- le nettoyage des données pour les rendre exploitables
- une longue phase d’exploration des données afin de comprendre en profondeur l’articulation des données la modélisation des données
- la modélisation
- l’évaluation et interprétation des résultats
- la prédiction
Au sein de ce cycle, le « machine learning » désigne l’ensemble des méthodes de modélisation statistique à partir des données, et se situe bien au cœur du travail de data scientist.
Intérêt de l’intelligence artificielle pour la data science
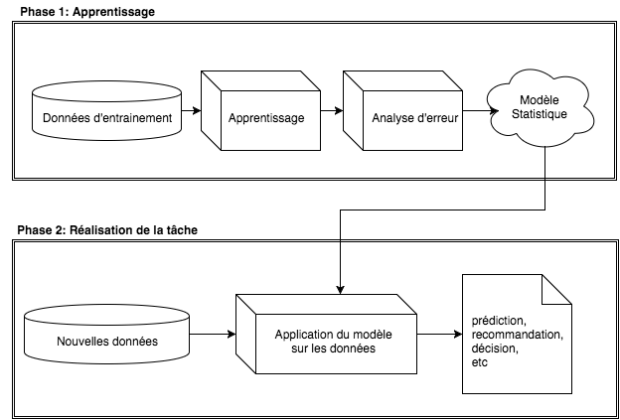
Le travail du data scientist qui utilise le machine learning consiste à sélectionner les bonnes données test, choisir et entraîner le bon algorithme en vérifiant grâce à l’analyse d’erreurs que le modèle devient de plus en plus performant et robuste. Si les performances s’améliorent lorsqu’on lui fournit les données d’entraînement, on dit alors que la machine “apprend“.
Une fois le modèle correctement parametré sur les données d’entraînement, le data scientist peut ensuite le déployer afin qu’il traite de nouvelles données, pour accomplir la tâche spécifique poursuivie (prédiction, recommandation, décision…).
