Eviter le problème de surapprentissage (Overfitting)
Le surapprentissage
En statistique, le surapprentissage, ou sur-ajustement, ou encore surinterprétation (en anglais « overfitting »), est une analyse statistique qui correspond trop étroitement ou exactement à un ensemble particulier de données. Ainsi, cette analyse peut ne pas correspondre à des données supplémentaires ou ne pas prévoir de manière fiable les observations futures. Un modèle surajusté est un modèle statistique qui contient plus de paramètres que ne peuvent le justifier les données.
Il est en général provoqué par un mauvais dimensionnement de la structure utilisée pour classifier ou faire une régression. De par sa trop grande capacité à capturer des informations, une structure dans une situation de surapprentissage aura de la peine à généraliser les caractéristiques des données. Elle se comporte alors comme une table contenant tous les échantillons utilisés lors de l’apprentissage et perd ses pouvoirs de prédiction sur de nouveaux échantillons.
La figure ci-dessous illustre ce phénomène dans le cas d’une régression. Les points verts sont correctement décrits par une régression linéaire.
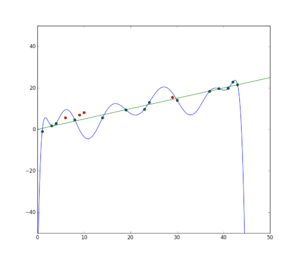
Si l’on autorise un ensemble de fonctions d’apprentissage plus grand, par exemple l’ensemble des fonctions polynomiales à coefficients réels, il est possible de trouver un modèle décrivant parfaitement les données d’apprentissage (erreur d’apprentissage nulle). C’est le cas du polynôme d’interpolation de Lagrange : il passe bien par tous les points verts mais n’a visiblement aucune capacité de généralisation.
En vert, les points de l’ensemble d’apprentissage et une régression linéaire sur ces points. En rouge, les points de l’ensemble de test. En bleu, le polynôme d’interpolation de Lagrange a une erreur d’apprentissage nulle mais est fortement affecté par le bruit de l’ensemble d’apprentissage et échoue à en dégager les caractéristiques.