Importer des données
Il est possible d’importer des fichiers csv dans postgreSQL, heureusement. Pour cela, il est nécessaire de créer la structure des tables à importer au préalable. Il est important de bien respecter les colonnes, les types et les formats du fichier csv pour pouvoir l’importer convenablement.
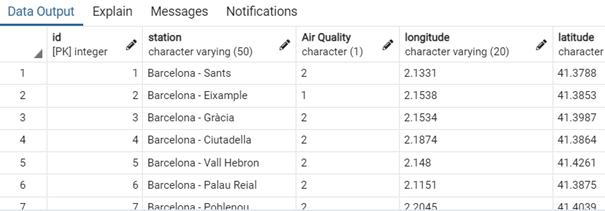
Vous souvenez-vous du dataset sur la qualité de l’air à Barcelone que nous avons exploré et retraité sur Jupyter ? Reprenons-le.
Créons la structure de la table
Reprenons la structure de notre dataset retraité et ajoutons une colonne ‘id’ qui sera notre clé primaire. Créons la table sous le nom de ‘air_quality’.
CREATE TABLE air_quality
(id SERIAL PRIMARY KEY,
Station VARCHAR(50),
"Air Quality" CHAR(1),
Longitude VARCHAR(20),
Latitude VARCHAR(20),
"O3 Hour" VARCHAR(10),
"O3 Quality" VARCHAR(10),
"O3 Value" NUMERIC,
"NO2 Hour" VARCHAR(10),
"NO2 Quality" VARCHAR(10),
"NO2 Value" NUMERIC,
"PM10 Hour" VARCHAR(10),
"PM10 Quality" VARCHAR(10),
"PM10 Value" NUMERIC,
"Generated" DATE,
"Date Time" DATE
);
Une fois le code exécuté, vous trouverez la table, vide en données.
NB : à chaque nouvelle création de table, rafraichir le menu déroulant ‘Tables’.
Importons les données du fichier csv
Une fois le squelette de notre table créé, nous pouvons importer les données simplement avec pgAdmin :
Cliquer droit sur la table et sélectionner ‘Import/Export…’.
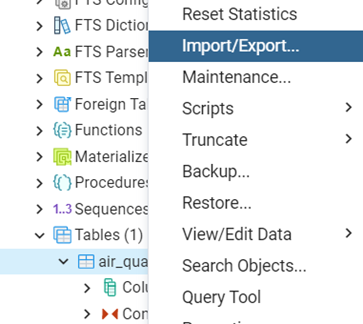
-Sélectionnez ‘Import’,
-Chargez le fichier csv,
-Cochez Header = Yes,
-Sélectionnez le séparateur ‘ , ’.
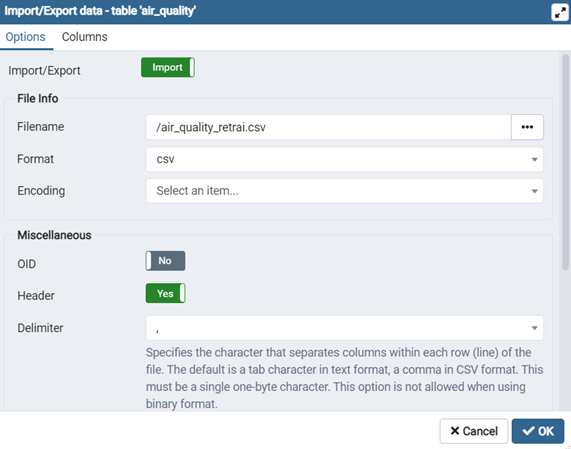
Dans l’onglet ‘Columns’, supprimez la première colonne ‘id’ qui est la clé primaire auto-incrémentée de postgreSQL. Cette colonne n’existe pas dans le fichier csv.
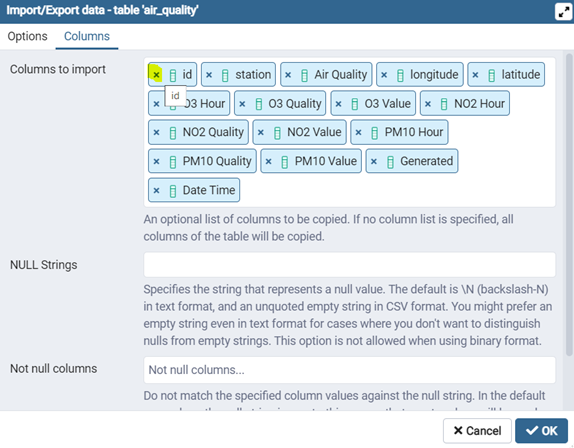
Cliquer sur OK et si tout se passe bien, le message suivant s’affichera.
NB : si vous obtenez une erreur, cliquez sur ‘More details…’ pour une description des erreurs.
Visualisons les données
Cliquer droit sur la table ‘View/Edit Data > All Rows’.