Description des données
Lecture du fichier csv
- Commençons par définir les chemins des fichiers csv à lire et créons notre dataframe :
– path.abspath() : renvoie le chemin abolu.
– path.join() : concatène plusieurs chemins.
BASE = os.path.abspath("<chemin du répertoire où lire les fichiers>")
air_quality_path = os.path.join(BASE,"air_quality_Nov2017.csv")
#source : https://www.kaggle.com/xvivancos/barcelona-data-sets?select=air_quality_Nov2017.csv
NB : pd.read_csv() : lit un fichier csv (comma-separated values) dans un dataframe.
air_quality = pd.read_csv(air_quality_path)
Description
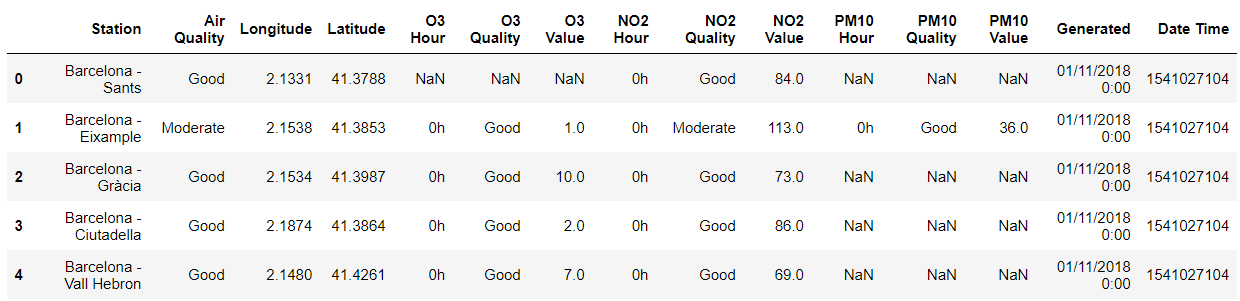
- Il est important pour nous, humains, de visualiser le dataframe. Je vous conseille donc de temps en temps (avant et après chaque modification du dataframe) de visualiser les premières lignes.
NB : pd.DataFrame.head(n) : sort les n premières lignes du dataframe. Par défaut, 5 lignes.
air_quality.head()
- Colonnes
Lister les colonnes avec pd.DataFrame.columns.
air_quality.columns

- Dimensionnalité du dataframe
pd.DataFrame.shape : renvoie un tuple des dimensions du dataframe (rows, columns).
air_quality.shape
![]()
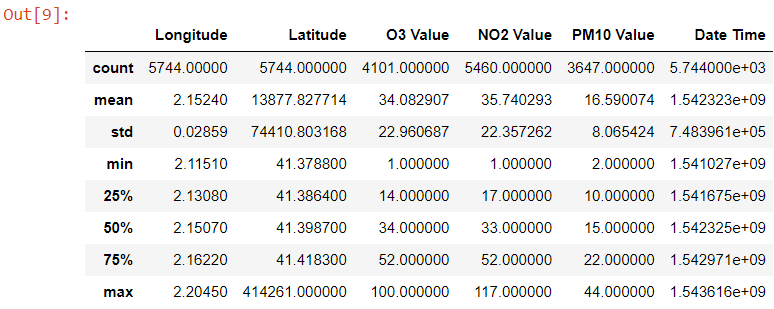
- Statistiques descriptives
pd.DataFrame.describe() : génère des statistiques descriptives du dataframe avec les colonnes numériques.
air_quality.describe()
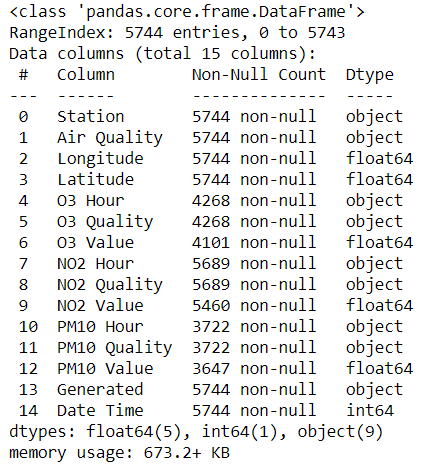
- Informations et types des colonnes
pd.DataFrame.info() : renvoie les informations concises du dataframe (colonnes, valeurs non-nulles, types, utilisation de la mémoire).
air_quality.info()
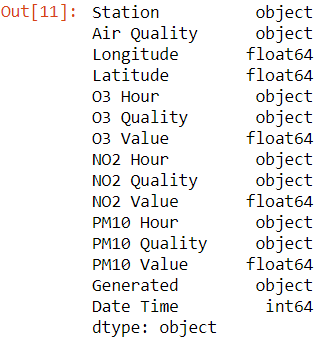
- Types
pd.DataFrame.dtypes : renvoie uniquement les types des colonnes.
- Valeurs manquantes
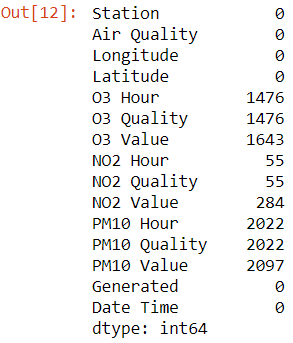
pd.DataFrame.isna().sum() : renvoie la somme des valeurs manquantes du dataframe par colonne.
– DataFrame.isna() : renvoie le dataframe avec les valeurs manquantes sous forme de booléen (True, False).
– DataFrame.sum() : renvoie la somme des valeurs demandées.
air_quality.isna().sum()
- Valeurs manquantes en pourcentage
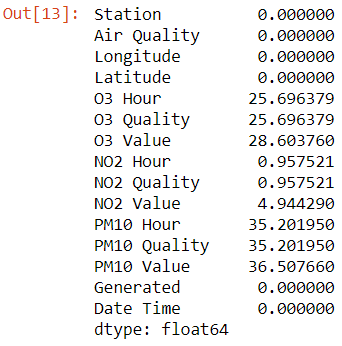
pd.DataFrame.isna().mean() : renvoie la part des valeurs manquantes du dataframe par colonne.
air_quality.isna().mean()*100
- Compter les valeurs par colonne
pd.Series.value_counts() : renvoie le nombre de valeur par catégorie.
air_quality['Air Quality'].value_counts()

NB : Une colonne d’un dataframe peut être considéré comme une Serie (matrice à une dimension).
- Le mode ou la valeur la plus fréquente
pd.Series.mode() : renvoie le mode, ou la valeur la plus fréquente de la série.
air_quality['Air Quality'].mode()
![]()
print("La valeur la plus fréquente est {}".format(air_qual ity['AirQuality'].mode().values))
![]()