Scraping des URLs sur le web
Scraping des URLs sur le web
Dans ce module, nous allons scraper des fichiers csv contenant des informations sur les entreprises françaises directement sur le site data.gouv.fr.
Nous allons créer une fonction get() qui permet de stocker les urls scrapés dans une liste python.
- Dans un premier temps, importons les modules nécessaires comme ceci :
import requests
import pandas as pd
import numpy as np
import zipfile, io
import urllib.request
import os
from bs4 import BeautifulSoup
- Créons les variables URL et BASE contenant respectivement l’url du site web dans lequel nous allons récupérer des données et le chemin absolu dans lequel nous allons stocker les données scrapées.
URL = 'https://www.data.gouv.fr/fr/datasets/base-sirene-des-entreprises-et-de-leurs-etablissements-siren-siret/'
BASE = os.path.abspath("<chemin du répertoire où enregistrer les fichiers>")
NB :
– os.path.abspath() : renvoie le chemin abolu.
– os.path.join() : concatène plusieurs chemins.
- Définissons une fonction ‘get’ avec comme paramètre l’url de la page web. Ajoutons une description à la suite à l’aide de trois guillemets.
def get(url=URL):
"""
Cette fonction stock les urls dans une liste
"""
- Ensuite créons la variable ‘response’ renvoyée par le serveur contenant les données de la page web via la fonction get de requests. La fonction get() du module « Requests » permet d’effectuer une requête GET (HTTP) qui demande des informations au serveur web. Si la requête est réussie, le code du statut de la réponse est ‘200 OK’. Si le code est 200 (ou OK), procédons à la suite du programme.
response = requests.get(URL)
if response.ok :
- Créons plusieurs objets ‘dwls’, ‘soup’, ‘title’ et ‘articles’ qui contiennent :
– Dwls : une liste vide qui va contenir les urls des fichiers à télécharger.
– Soup : un objet qui contient le code HTML de la page web.
– Title : un objet qui contient le titre de la page web.
– Articles : un objet qui contient les liens hypertextes de la page web qui permettent de télécharger les fichiers.
Pour créer l’objet ‘articles’, il faut inspecter le code HTML de la page web (voir vidéo ci-dessous) :
- Cliquer droit sur la page web, inspecter
- Dérouler le code HTML
dwls = []
soup = BeautifulSoup(response.text, 'lxml') # .text sort le code html de la page web / 'lxml' : parseur (format)
title = soup.find('title')
print(title.text, '\n') # .text sort le titre sans les balises <>
articles = soup.findAll('a', {'aria-label' : 'Télécharger la ressource'})
print('Il y a : {} liens'.format(len(articles)), '\n')
NB :
– BeautifulSoup.find(args) : renvoie les balises contenant les arguments spécifiés sous forme de liste. findAll renvoie toutes les balises.
- Une fois l’objet ‘articles’ créé, qui est une liste python contenant toutes les informations sur les liens hypertextes de la page web, il convient de parcourir la liste afin de récupérer les liens hypertextes contenus dans les balises <a>. Les balises <a> contiennent des informations sur les liens hypertextes. Cependant, ce qui nous intéresse est le paramètre ‘href’ qui contient l’URL du fichier à télécharger.
for a in articles:
link = a.get('href')
NB :
– BeautifulSoup.find(args).get(args) : renvoie les informations contenues dans le paramètre spécifié de la balise HTML spécifiée avec la méthode ‘.find’.
- Enfin, nous renvoyons la liste des urls des fichiers à télécharger.
dwls.append(link)
dwls = [i for i in dwls if i != None]
return dwls
Voilà, vous savez maintenant scraper des données sur internet. Bien entendu, chaque page web est différente, possède un code différent et donc les programmes python que vous coderez seront différents. Afin de simplifier ce cours, nous ne sommes pas rentrés dans les détails des modules utilisés, mais encore une fois, je vous invite à lire la documentation sur internet afin d’approfondir vos compréhensions.
Code complet
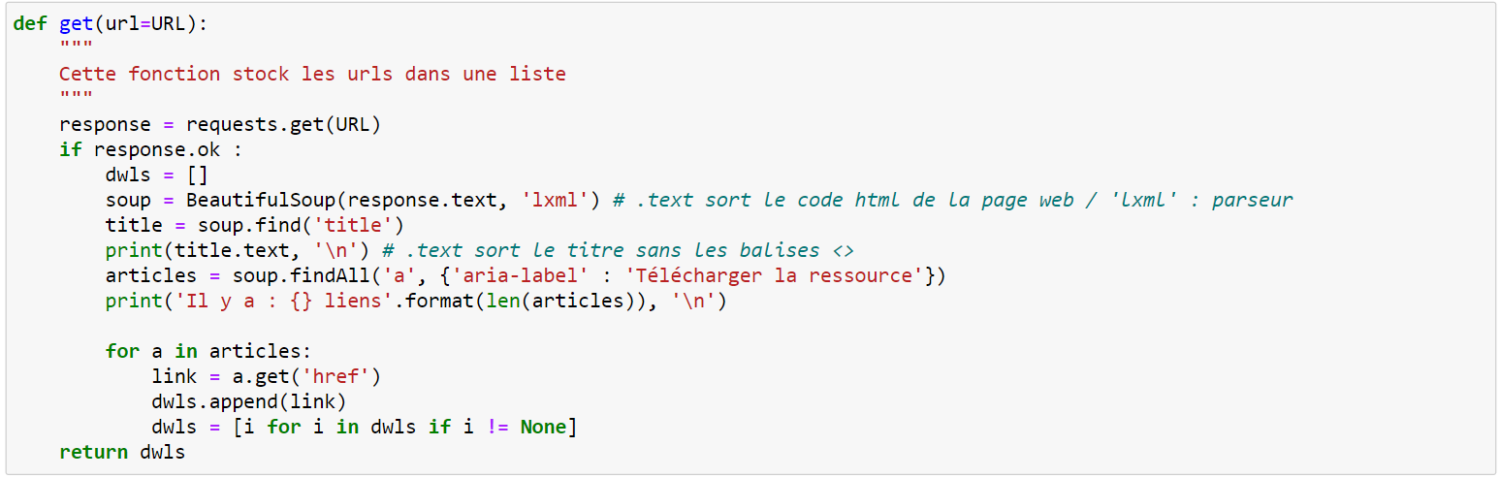
def get(url=URL):
"""
Cette fonction stock les urls dans une liste
"""
response = requests.get(URL)
if response.ok :
dwls = []
soup = BeautifulSoup(response.text, 'lxml') # .text sort le code html de la page web / 'lxml' : parseur
title = soup.find('title')
print(title.text, '\n') # .text sort le titre sans les balises <>
articles = soup.findAll('a', {'aria-label' : 'Télécharger la ressource'})
print('Il y a : {} liens'.format(len(articles)), '\n')
for a in articles:
link = a.get('href')
dwls.append(link)
dwls = [i for i in dwls if i != None]
return dwls