Le web scraping
Présentation
HTTP
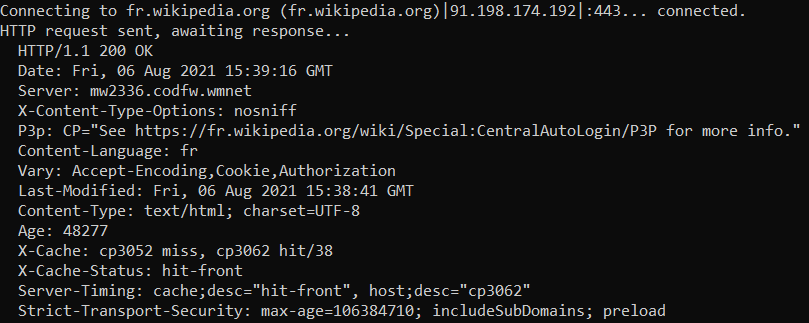
Sur le Web, les clients, comme votre navigateur, communiquent avec les serveurs Web en envoyant des requêtes HTTP. Ce protocole HTTP contrôle la façon dont le client formule ses demandes et la façon dont le serveur y répond. Une réponse HTTP est un ensemble de lignes envoyées au navigateur par le serveur qui se compose généralement d’un en-tête et d’un corps.
Voici l’en-tête de la réponse obtenue si on tape Wikipédia dans Wikipédia :
Le web scraping est une technique qui permet de récupérer des données contenues sur le web de façon automatisée et de stocker ces informations dans des formats plus exploitables comme Excel ou csv.
La question est de savoir quelles données scraper et comment les scraper ?
Il existe beaucoup trop de données à scraper pour les expliquer ici (vous vous en doutez). Avant de récupérer tous les contenus de tous les sites présents sur le web, il est essentiel de comprendre quelles informations nous voulons récupérer et d’identifier les sources des données.
Dans ce cours nous nous focaliserons sur le web scraping avec Python via une requête HTTP afin d’automatiser le téléchargement de fichiers csv. Nous prendrons comme exemple une page web du site « data.gouv.fr » qui contient différents types d’informations et les liens téléchargeables qui nous intéressent.