Sélectionner le bon algorithme
L’apprentissage automatique (Machine Learning)
L’analyse des données massives consistent en grande partie à détecter des corrélations entre des variables plutôt que de trouver des relations de causes à effet. Le but des techniques d’apprentissage est de chercher la valeur d’un variable en fonction d’autres variables.
L’apprentissage automatique ou apprentissage statistique (machine learning en anglais), champ d’étude de l’intelligence artificielle, concerne la conception, l’analyse, le développement et l’implémentation de méthodes permettant à une machine (au sens large) d’évoluer par un processus systématique, et ainsi de remplir des tâches difficiles ou impossibles à remplir par des moyens algorithmiques plus classiques. L’analyse peut concerner des graphes, arbres, ou courbes au même titre que de simples nombres.
Le Machine Learning (ML) est un ensemble : d’outils statistiques, d’algorithmes informatiques et d’outils informatiques qui permettent d’automatiser la construction d’une fonction de prédiction à partir d’un ensemble d’observations (l’ensemble d’apprentissage).
L’objectif du Machine Learning est de trouver des corrélations. En fait, l’objectif n’est pas de trouver des causes en examinant une chronologie (comme dans une démarche scientifique), mais d’identifier des corrélations pertinentes entre les variables prédictives des observations et les variables cibles. En effet, rien n’impose qu’une variable prédictive soit la cause d’un phénomène décrit par une variable cible.
Le machine learning permet donc de trouver un modèle (stochastique ou déterministe) du phénomène à l’origine des données. C’est à dire qu’on considère que chaque donnée observée est l’expression d’une variable aléatoire générée par une distribution de probabilité.
En apprentissage automatique, on distingue 2 grandes familles d’algorithmes d’apprentissage : apprentissage supervisé vs. apprentissage non-supervisé.
- En apprentissage supervisé, vous allez récupérer des données dites annotées de leur sorties pour entraîner le modèle, c’est à dire que vous leur avez déjà associé un label ou une classe cible et vous voulez que l’algorithme devienne capable de la prédire sur de nouvelles données non annotées une fois entraîné.
- En apprentissage non-supervisé, les données d’entrées ne sont pas annotées. L’algorithme d’entraînement s’applique dans ce cas à trouver seul les similarités et distinctions au sein de ces données, et à regrouper ensemble celles qui partagent des caractéristiques communes.
Chaque famille d’algorithme correspond également à un type de données et de problèmes. Ainsi, on considère que les problèmes de prédiction d’une variable continue (un nombre) sont des problèmes de régression tandis que les problèmes de prédiction d’une variable discrète (une catégorie) sont des problèmes de classification.
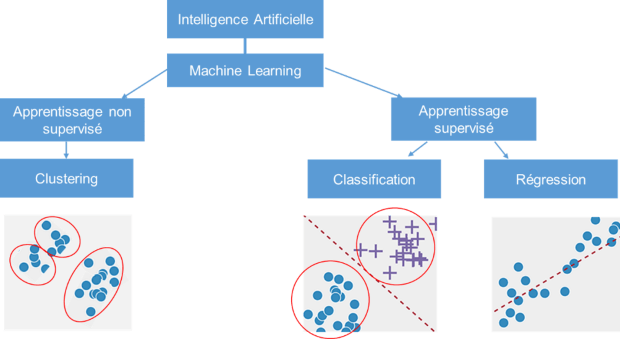
Typologie des algorithmes
Il existe plusieurs algorithme à utiliser en fonction des problèmes que l’on souhaite résoudre.
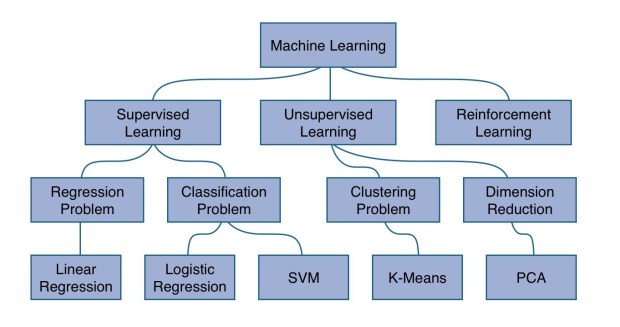
Critères pour sélectionner un algorithme d’apprentissage afin de faire une prédiction
Un bon modèle de machine learning, c’est un modèle qui généralise. La généralisation, c’est la capacité d’un modèle à faire des prédictions non seulement sur les données que vous avez utilisées pour le construire, mais surtout sur de nouvelles données : c’est bien pour ça que l’on parle d’apprentissage ! De bonnes performances sur le jeu d’entraînement ne garantissent pas que le modèle sera capable de généraliser. Alors, on cherche à développer un modèle qui soit suffisamment complexe pour bien capturer la nature des données (et éviter ainsi le sous-apprentissage), mais suffisamment simple pour éviter le sur-apprentissage.
Toutefois, voilà ci-dessous quelques critères qui permettent de sélectionner un algorithme d’apprentissage :
- la taille,
- la qualité et de la nature du jeu de données
- la nature des données à prédire
- la précision de la prédiction attendue
- la durée d’apprentissage
- le nombre de paramètres pour configurer l’algorithme
- la linéarité du modèle…