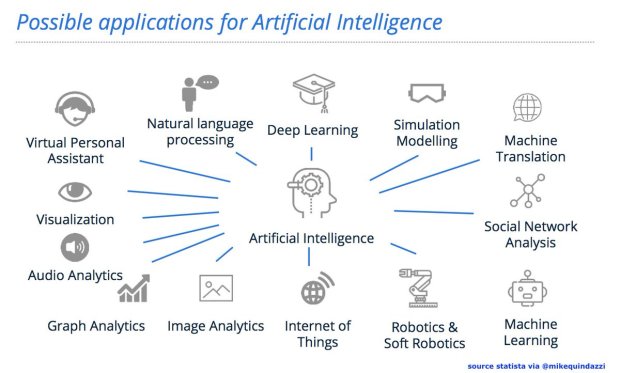
Le big data
Définition
Le big data est l’ensemble de technologies, d’architectures, d’outils et de procédures permettant à une organisation de très rapidement capter, traiter et analyser de larges quantités et contenus hétérogènes et changeants, pour en extraire des informations pertinentes à un coût accessible afin d’aider à la prise de décision.
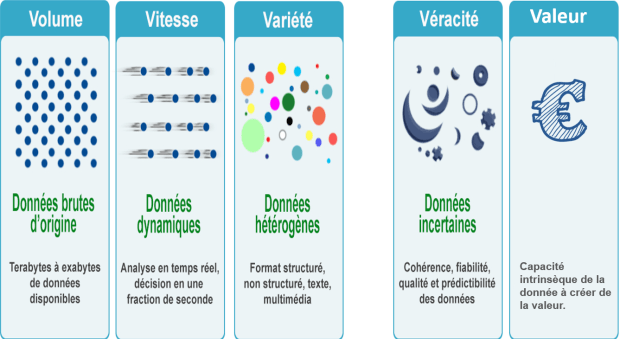
Caractéristiques
| Dimension | Caractéristique |
| Volume | Le volume est évidemment la première caractéristique qui vient à l’esprit quand on parle de Big Data.Suivant une courbe exponentielle, ce volume concerne non seulement les données produites chaque jour, mais aussi celui des capacités de stockage des supports informatiques. Il tend aujourd’hui vers l’infini et nécessite des unités de mesure vertigineuses comme le yottabyte qui équivaut à 1.000.000.000.000.000.000.000.000 de bytes, soit un trillion de terabytes. Il est évident que les bases des données et outils de gestion traditionnels ne sont pas capables de gérer de telles quantités de données. |
| Variété (Variety) | La montée en puissance des données non structurées va de pair avec un diversification des formats et des types de données.L’entreprise doit donner du sens aux avis et propositions émis sur Facebook, aux images, aux sons, aux vidéos, mais aussi aux informations émises par les terminaux mobiles ou issues des interactions M2M (Machine To Machine). Dans le domaine du commerce, des solutions Big Data permettront de relier les données non structurées émises par un client (comportement, intonations de la voix, …) aux données classiques enregistrées à son sujet (historique des achats, service après-vente, …) pour développer en temps réel une offre adaptée à ses besoins. |
| Vitesse (Velocity) | La vitesse du Big Data représente le temps nécessaire pour que les données soient collectées, traitées et activées par l’entreprise.Le monde digital est désormais « plus rapide que le temps réel » et les données n’échappent à cette tendance. Elles sont produites, capturées, traitées, et partagées à une vitesse inédite.
Une entreprise de services financiers doit ainsi traiter et analyser plusieurs millions de messages par seconde pour activer ou non des ordres sur les marchés. Le temps réel est donc la nouvelle unité de temps pour les entreprises et les systèmes classiques de traitement des informations (gestion, personnalisation, marketing, …) se révèlent là encore peu adaptés. |
| Véracité (Veracity) | La qualité et la fiabilité des données est clairement un paramètre essentiel.C’est d’autant plus vrai que les sources de données sont désormais majoritairement hors du périmètre de contrôle des organisations. Le concept de véracité traduit donc le besoin stratégique de disposer de données de qualité.
En principe, une plateforme Big Data permet à une entreprise d’analyser les données relatives à son environnement de manière quasi exhaustive et donc d’améliorer sa compréhension de l’ensemble des composants de son environnement (clients, partenaires, produits, concurrents, …). Mais paradoxalement, l’entreprise est confrontée au risque de se noyer dans cet océan de données et de n’être pas capable de faire le tri entre les informations pertinentes et le « bruit ». Une bonne illustration de ce problème est survenue lors de l’élection présidentielle de 2012 au Mexique, des tweets issus de robots spammeurs et des faux comptes « orientés » ont largement pollué débat politique et son analyse sur Twitter. |
| Visibilité | Les données ne servent à rien si elles ne sont pas visibles et accessibles pour ceux qui en ont besoin.Ce besoin de visibilité est souvent évoqué par les marketers qui souhaitent disposer de tableaux (dashboards) et visualisations intelligents, accessibles à la volée et facilement interprétables.
C’est l’objectif de la solution proposée par CaptainDash qui permet de monitorer, comprendre et optimiser les processus sur base de données factuelles et visuelles. Toutes les informations nécessaires sont accessibles via une interface mobile et véritablement intuitive. |
| Valeur (Value) | En bout de course, la valeur du Big Data pour une entreprise se mesurera à l’avantage compétitif qu’elle en aura dégagé.Cela dépend notamment de la qualité des analytics et de la compétence des « data scientists » chargés de leur donner du sens. Créer des données pour le plaisir de la performance technique n’est pas viable sur le long terme. Cela implique donc également des outils de mesure du ROI. |
Small data vs Big data
Le terme de small data est principalement utilisé en réaction aux abus d’usages et au phénomène de mode liés au big data. L’évocation du small data fait généralement référence à la nécessité de devoir d’abord utiliser pleinement et efficacement le potentiel des données de base qui sont depuis longtemps disponibles avant de se lancer dans des projets parfois trop ambitieux de big data. Le Small data est la quantité de données que vous pouvez aisément stocker et utiliser sur une seule machine et plus précisément sur un seul ordinateur portable ou serveur de haute qualité.
En réalité, c’est la combinaison de l’analyse des données (même avec des volumes limités, avec des outils décisionnels et prédictifs), et de processus de jugement collaboratifs (et itératifs) qui détermine la bonne décision. On peut même avancer que c’est ce qui fera, à l’avenir, la différence entre les organisations, dans la mesure où il sera de plus en plus difficile d’intégrer des masses énormes d’informations dans les processus de décision – du moins sans disposer des outils adaptés.
Enjeux du Big data
Nouvelles sources de données massives
Il n’y a plus besoin d’autant de ressources pour organiser la phase de collecte des données. On peut se focaliser directement sur le traitement et la valorisation des données stockées. Seules les étapes de préparation des données, le data munging, qui précèdent l’analyse, deviennent fondamentales car elles permettent la transformation des variables dans un format facilitant l’analyse et impactant la qualité des résultats.
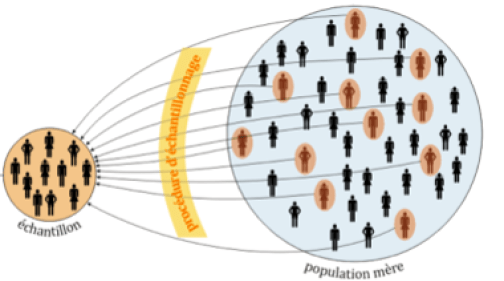
Analyse exhaustive d’une population
Ainsi, l’avènement des données massives rend accessible l’analyse exhaustive d’une population d’individus sans passer par une étape d’échantillonnage. Grâce aux évolutions technologiques, l’observation d’une population entière évite les biais dus aux techniques de sondages.
Changement de paradigme
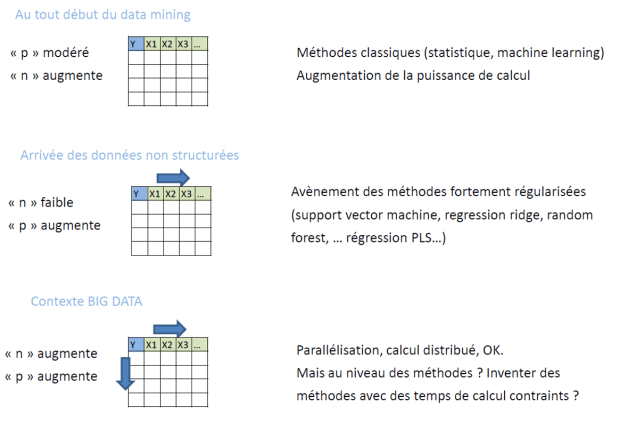
Il arrive que le nombre p d’informations disponibles (e.g. des variables caractérisant un individu ou son comportement) devienne largement plus grand que la taille n des échantillons étudiés (nombre d’individus étudiés). Ce phénomène implique d’adapter les méthodes statistiques car il y a plus d’indétermination que d’information.
Validité scientifique
Les critères de reproductibilité et de réplication d’une analyse de données sont la condition de validité scientifique et d’amélioration des connaissances. Cette condition permet de s’affranchir d’effets aléatoires venant fausser les résultats ainsi que des erreurs de jugement ou des manipulations de la part des scientifiques.

Nouveaux outils
Les caractéristiques des données massives (variété, vélocité, etc.), obligent à utiliser de nouveaux outils et méthodes mathématiques pour minimiser les erreurs de prévisions. On assiste à l’importance des algorithmes et au développement de l’usage des techniques d’apprentissage automatique (machine learning) ou des modèles à base de courbes, surfaces ou graphes.