L’apprentissage automatique (Machine learning)
Définition
Le principe de base du Machine Learning (apprentissage statistique ou automatique) repose sur le fait qu’entre nos données explicatives X et les données que l’on cherche à prédire Y, il existe une fonction f telle que:
Y = f(X) + Ɛ, avec Ɛ un bruit aléatoire
On peut décomposer l’erreur de prédiction pour x de la manière suivante :
Err(x)=Biais²+Variance+Erreur Irréductible
L’objectif du Machine Learning est de trouver une fonction g qui approxime au mieux la fonction f grâce aux différents algorithmes qui permettent de créer des familles de fonctions différentes.
Enjeu
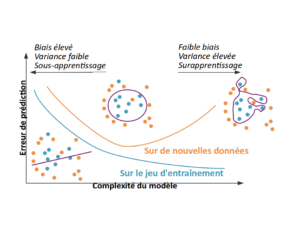
Le principale enjeu en apprentissage automatique est de résoudre le dilemme biais–variance.
Le dilemme biais–variance est le problème de minimiser simultanément deux sources d’erreurs qui empêchent les algorithmes d’apprentissage supervisé de généraliser au-delà de leur échantillon d’apprentissage:
- Le biais est l’erreur provenant d’hypothèses erronées dans l’algorithme d’apprentissage. Un biais élevé peut être lié à un algorithme qui manque de relations pertinentes entre les données en entrée et les sorties prévues (sous-apprentissage).
- La variance est l’erreur due à la sensibilité aux petites fluctuations de l’échantillon d’apprentissage. Une variance élevée peut entraîner un surapprentissage, c’est-à-dire modéliser le bruit aléatoire des données d’apprentissage plutôt que les sorties prévues.
Trouver le bon compromis
En utilisant un modèle comportant une trop grande complexité – dit « à haute variance » – on peut mal capturer le phénomène sous-jacent et devenir trop dépendant aux données d’entraînement et aux petites fluctuations aléatoires, non représentatives du phénomène. A contrario, il ne faut pas choisir un modèle trop « simple » qui biaise le résultat et ne parvient pas à capturer toute la complexité du phénomène.
Il s’agit de minimiser cette erreur en trouvant le juste équilibre entre biais et variance qui se trouve pile au minimum de l’erreur totale (combinaison du biais et de la variance).
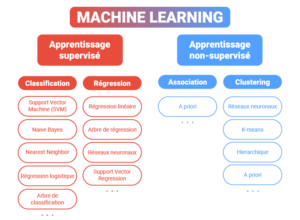
Typologie d’apprentissage automatique
Il existe 3 paradigmes d’apprentissage en Machine Learning :
- l’Apprentissage Supervisé (Supervised Learning)
- l’Apprentissage Non-Supervisé (Unsupervised Learning)
- l’Apprentissage par Renforcement ou semi-supervisé (Reinforcement Learning)
Dans le cas de l’apprentissage supervisé, il faut au préalable “guider” l’algorithme sur la voie de l’apprentissage en lui fournissant des exemples qu’il estime probants après les avoir préalablement étiquetés des résultats attendus.
Dans le cas de l’apprentissage non supervisé, l’apprentissage par la machine se fait de façon totalement autonome. Des données sont alors communiquées à la machine sans lui fournir les exemples de résultats attendus en sortie. Il n’y a donc pas de variable Y.
L’apprentissage par renforcement qui consiste à laisser la machine apprendre à faire une tâche (par exemple piloter un mini drone) en la laissant pratiquer seule. Quand la machine réussit ce qu’elle entreprend, elle reçoit un bonus. Quand elle échoue, elle reçoit un malus. On développe un programme qui force la machine à vouloir maximiser ses bonus, et la machine fait alors l’analyse de ses propres erreurs du passé afin de s’améliorer au fil du temps.
Algorithmes d’apprentissage automatique