Analyser les données du Titanic avec BigML
Consulter le jeu de données
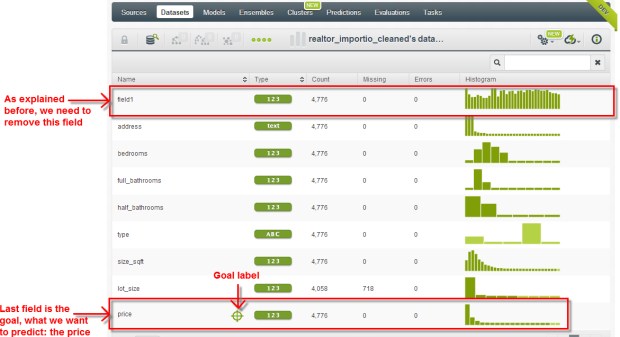
Vous pouvez consulter:
- le type de variables
- le nombre d’observations
- les valeurs manquantes
- la distribution
Consulter les statistiques descriptives des variables
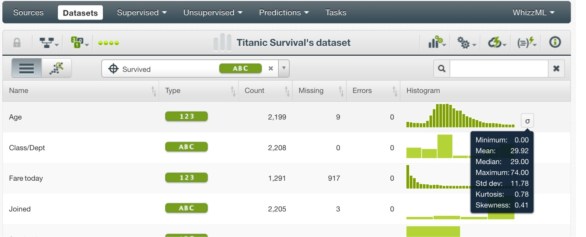
Vous pouvez consulter pour chaque variable:
- Min = valeur minimum
- Mean = Moyenne
- Mediane = autant en dessous qu’au dessus
- Max = valeur maximum
- STD DEV = Standard deviation : Ecart type.
- Kurtosis = « Applatissement »
- Skewness = « Asymetrie »
Configurer le jeu de données
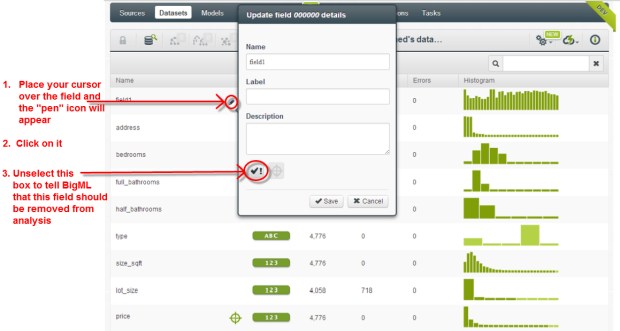
Vous pouvez définir la/les variables cibles à prédire. La dernière ligne est définie par défaut comme objectif (icône en forme de croix). Le but est ce que nous voulons prédire. BigML appelle cela le champ objectif. Si votre dernière ligne n’est pas l’objectif que vous souhaitez modifier, placez votre souris sur la ligne souhaitée. Une icône apparaîtra pour que vous puissiez apporter les modifications.
Visualiser les relations entre les variables
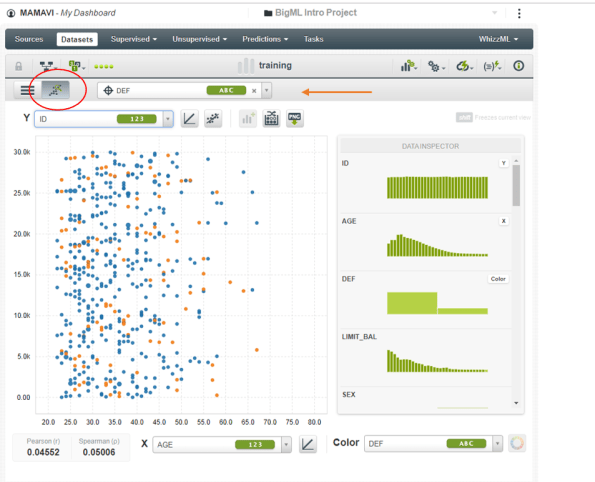
Vous pouvez faire des figures en définissant vos axes et vos ordonnées.
Configurer le modèle
Vous pouvez choisir de configurer votre modèle prédictif manuellement ou de laisser BigML faire le travail lui-même grâce à ses fonctionnalités “1 clic”.
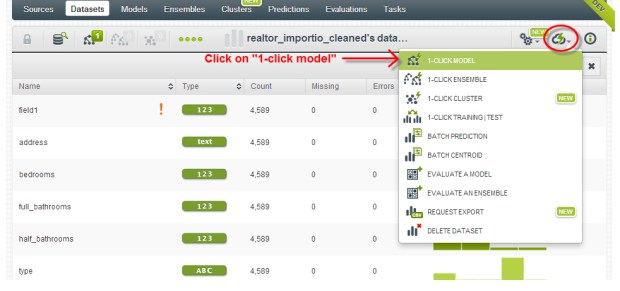
L’historique des requêtes réalisée sur un jeu de données apparaît ici:
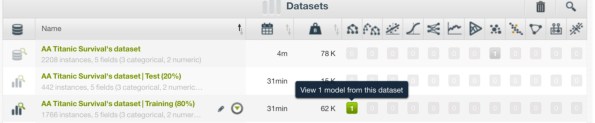
Apprentissage supervisé
Par défaut, BigML représente le modèle prédictif sous la forme d’un arbre de décision.
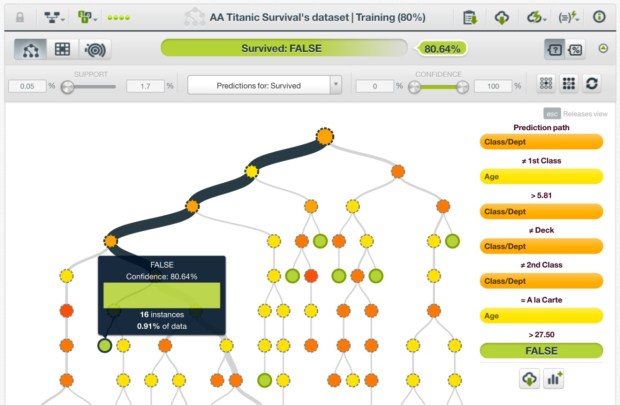
Vous pouvez également choisir une visualisation sunburst et interagir avec celle-ci (sunburst intégré ci-dessous). La seule différence avec l’arbre de décision est qu’il commence par le centre plutôt que par le haut.