Collecter les données du Titanic dans BigML
Source des données
Les données du challenge Titanic sont disponibles en ligne sur le site de Kaggle : https://www.kaggle.com/c/titanic
Présentation des données
Le challenge propose de télécharger deux fichiers CSV: train.csv et test.csv. Le fichier train.csv contient les données qui permettront la construction de l’algorithme d’apprentissage. Le fichier test.csv contient les données sur lesquelles l’algorithme sera testé. Chaque passager possède un identifiant unique allant de 1 à 891 pour le fichier train.csv et de 892 à 1309 pour le fichier test.csv. Ces fichiers ne contiennent pas de données sur les membres de l’équipage, ce qui explique l’écart avec le nombre de personnes présentes à bord.
Vous disposez donc de 3 jeux de données.
Un jeu de données d’entrainement de 891 lignes est fourni (train.csv), au format csv (comma separated values), il comporte 12 colonnes :
- PassengerId (identifiant passager)
- Survived (0 : décédé, 1 : a survécu)
- Pclass (classe, de 1 à 3)
- Name (Nom, prénom et titre)
- Sex (male/female)
- Age (en années)
- SibSp (nombre de frère, soeur, beau-frère, belle soeur, mari ou femme à bord)
- Parch (nombre de parents et d’enfants à bord)
- Ticket (numéro du ticket)
- Fare (prix du ticket. Le prix est indiqué en £ et pour un seul achat et peut correspondre à plusieurs tickets)
- Cabin (numéro de cabine)
- Embarked (port d’emarquement : C – Cherbourg, S – Southampton, Q = Queenstown)
Un jeu de test de 418 lignes est fourni (test.csv), il comporte 11 colonnes, les mêmes que pour le jeu d’entrainement sans la colonne « Survived » évidemment puisque c’est celle qu’il faut deviner.
Les données de soumission. Le résultat de la prédiction est à fournir au format csv aussi, comportant 418 lignes (pour les 418 passagers du jeu de test) et deux colonnes : PassengerId (identifiant passager) Survived (0 : décédé, 1 : a survécu)
Importer vos données dans BigML
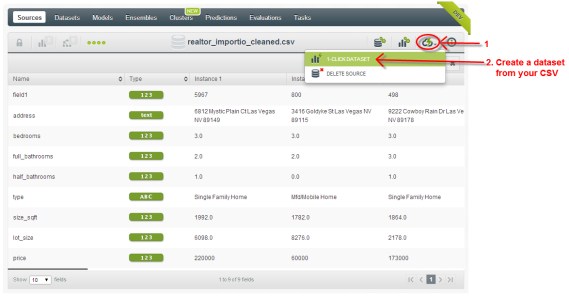
Créer une source de données en important le fichier de données depuis votre ordinateur.
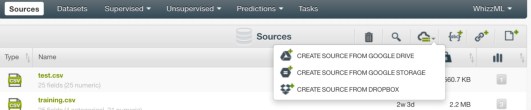
Créer une source de données en important le fichier de données depuis une autre source.
Créer un dataset
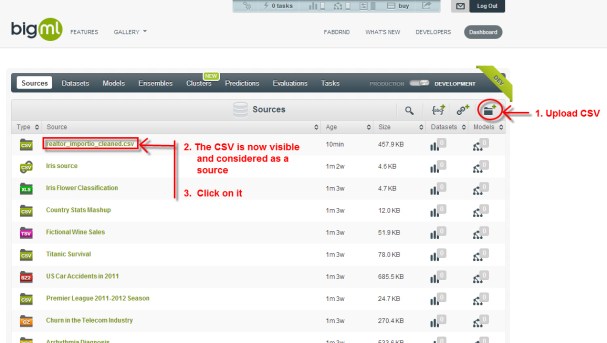
Maintenant, le CSV est répertorié en tant que source et peut être utilisé dans BigML. Cliquez dessus pour voir ce qui a été importé.
- Créer un nouveau projet et lui attribuer un nom
- Sélectionner les variables que vous souhaiter analyser
- Transformer la source en jeu de données (configure datasets)