
Citation
Les auteurs
Vincent Laurens
(vincentfr.laurens@gmail.com) - (Pas d'affiliation)juliadnt
(julia.denat@yahoo.fr) - (Pas d'affiliation)Mohamed AKHMOUCH
(mohamed.akhmouch@gmail.com) - (Pas d'affiliation)Nelson
(n_boda@stu-psbedu.paris) - (Pas d'affiliation)Oswald
(oswaldbenoit05@gmail.com) - (Pas d'affiliation)
Copyright
Déclaration d'intérêts
Financements
Aperçu
Contenu
Dans l’ère numérique en constante évolution, les données sont devenues le cœur battant de l’économie mondiale. Les entreprises, en particulier les marketplaces en ligne, dépendent de manière cruciale de ces précieux actifs numériques pour prospérer.
Les marketplaces en ligne représentent un environnement numérique dynamique où les données sont constamment générées, mises à jour et consommées. Cette dynamique exige une gestion de la qualité des données sans faille pour maintenir la confiance des clients, assurer une expérience utilisateur optimale et garantir le bon fonctionnement des opérations. Des informations inexactes, obsolètes ou incohérentes peuvent entraîner des problèmes tels que des commandes incorrectes, des retours clients mécontents et des opportunités de vente perdues.
L’importance de la gestion de la qualité des données ne se limite pas à la satisfaction des clients. Elle peut également constituer un avantage concurrentiel significatif.
En fin de compte, la qualité des données est un investissement stratégique qui peut conduire à une croissance durable et à une position dominante sur le marché.
Au cours de cet article, nous explorerons en détail la manière dont une gestion efficace de la qualité des données peut être mise en œuvre au sein d’une marketplace. De la mission et des objectifs à la démarche, aux outils et aux méthodes spécifiques, nous vous guiderons à travers les étapes essentielles pour organiser la qualité des données au sein de votre entreprise. Parallèlement, nous aborderons les défis rencontrés, les apports de la méthode agile et les perspectives futures.
Objectifs
La première étape essentielle pour organiser la qualité des données consiste à effectuer une analyse approfondie des données disponibles. Cela implique de comprendre les types de données, leur origine, leur structure et leur qualité actuelle. Cette analyse permettra d’identifier les problèmes et les lacunes existantes.
La création d’une base de données relationnelle est une étape fondamentale pour stocker, organiser et gérer les données de manière efficace. Une base de données bien conçue permettra de garantir la cohérence des données et de faciliter leur accès et leur traitement ultérieur.
L’intégration des données de la marketplace à une solution de gestion de métadonnées telle qu’Openmetadata offre de multiples avantages. Elle permet de documenter les métadonnées, de suivre les transformations des données et de maintenir un contrôle de la qualité plus rigoureux.
La gestion de la qualité des données implique la définition de normes de qualité, l’identification des règles de validation, la surveillance continue et la correction des erreurs. Cette étape garantit que les données sont fiables, précises et conformes aux attentes de l’entreprise.
Démarche
La réalisation de ces objectifs nécessite une démarche méthodique et une équipe bien coordonnée. Au sein d’une équipe multidisciplinaire composée d’un Scrum Master, d’un Product Owner, d’un Data Steward et de plusieurs Data Analystes, la méthode Agile sera le moteur de notre succès. Voici comment chaque rôle contribuera à la réalisation de nos objectifs :
- Scrum Master : Le Scrum Master joue un rôle essentiel dans la gestion de projet agile. Il facilite les réunions, élimine les obstacles, et s’assure que l’équipe reste concentrée sur les objectifs.
- Product Owner : Il définit les priorités, valide les livrables et s’assure que les besoins de l’entreprise sont satisfaits. Il veille à ce que l’analyse des données, la création de la base de données, l’intégration d’Openmetadata et la gestion de la qualité de la donnée soient alignées sur la vision globale.
- Data Steward : Le Data Steward est chargé de garantir la qualité et la gouvernance des données. Il veille à ce que les normes de qualité soient respectées, surveille les problèmes de qualité et prend des mesures pour les résoudre.
- Data Analyst : Les Data Analysts sont responsables de l’analyse des données, de la création de la base de données, de l’intégration d’Openmetadata et de la gestion de la qualité des données au quotidien. Ils utilisent leur expertise pour transformer les données brutes en informations exploitables.
En combinant la méthodologie Agile avec une équipe compétente, nous pourrons organiser la qualité des données d’une marketplace de manière efficace et rentable.
Etude du cas de la marketplace Olist
La marketplace Olist est une plateforme de commerce électronique qui opère au Brésil. Elle se distingue par son modèle commercial innovant, qui sert de pont entre des milliers de petits commerçants et les consommateurs finaux, tout en éliminant la nécessité pour Olist d’acheter, stocker ou expédier directement les produits. Au lieu de cela, Olist fournit un espace en ligne où les détaillants inscrits peuvent publier leurs produits et toucher un public beaucoup plus vaste.
Les activités
Olist offre une gamme diversifiée d’activités clés qui contribuent à son succès continu sur le marché brésilien :
- Connecter les Vendeurs aux Acheteurs : Olist agit comme une interface entre les vendeurs locaux et les acheteurs potentiels. Les détaillants inscrits peuvent utiliser la plateforme pour annoncer leurs produits, tandis que les acheteurs ont accès à une variété d’articles provenant de sources différentes.
- Faciliter les Transactions : Olist facilite les transactions en ligne en fournissant une infrastructure sécurisée pour les paiements en ligne. Les acheteurs peuvent effectuer leurs achats en toute confiance, sachant que leurs informations financières sont protégées.
- Fournir des Outils de Gestion : Pour les vendeurs, Olist offre des outils de gestion qui leur permettent de suivre leurs ventes, de gérer leur inventaire et de gérer les commandes en toute simplicité
- Optimiser la Logistique : Bien que Olist ne stocke pas physiquement les produits, elle optimise la logistique en intégrant les vendeurs à des prestataires de services de livraison réputés.
En résumé, Olist offre une solution complète pour les vendeurs et les acheteurs, en connectant efficacement les deux parties grâce à sa plateforme de marketplace. Grâce à son modèle commercial novateur et à ses activités bien définies, Olist a réussi à s’imposer comme un acteur majeur du commerce électronique au Brésil, offrant des avantages significatifs à tous les acteurs de son écosystème.
La base de données
Le modèle de données d’Olist est un modèle de données relationnel en étoile composé d’une table de fait et de plusieurs tables de dimensions. Le modèle sert à stocker et à gérer les informations liées à son activité de commerce électronique au Brésil.
Le modèle de données d’Olist est conçu pour prendre en charge la gestion des commandes, des clients, des vendeurs, des produits, des paiements, des évaluations de produits et d’autres aspects du commerce électronique.
Les données sont ainsi stockées dans 9 tables interconnectées:
- Table des commandes : Cette table est le noyau des transactions d’Olist, enregistrant chaque commande avec des détails tels que l’identifiant du client, le statut de la commande, les dates clés et le suivi de la livraison. Cette vue d’ensemble permet une analyse approfondie du parcours client et une optimisation logistique.
- Table de paiement : Elle capture les nuances des transactions financières, détaillant les types de paiement, les échéances et les montants.
- Table des articles de commande : Ici, chaque produit commandé est suivi, y compris son prix, le coût de l’expédition, et les informations des vendeurs. Cette table offre un aperçu précis du catalogue de produits et de la logistique de distribution.
- Table de revue : Elle recueille les retours des clients, offrant des insights précieux sur la satisfaction et les préférences, essentiels pour le maintien de la qualité du service et l’amélioration des produits.
- Table des clients : Cette table fournit des informations démographiques et géolocalisées des clients, cruciales pour le ciblage marketing et l’analyse des tendances de consommation.
- Table de géolocalisation : Elle enrichit les données avec des informations géographiques précises, facilitant ainsi une logistique plus efficace et une meilleure compréhension de la distribution géographique des clients et des vendeurs.
- Table des produits : Cette table détaille chaque produit avec sa description, ses dimensions, sa catégorie, enrichissant ainsi la compréhension du catalogue et aidant à optimiser la gestion des stocks.
- Table des vendeurs : Elle offre un aperçu des vendeurs de la plateforme, incluant des informations géographiques et démographiques essentielles pour la gestion des relations vendeurs.
- Table des nouveaux vendeurs : Focalisée sur les nouveaux vendeurs, cette table est un outil stratégique pour l’expansion et le développement de la base de vendeurs d’Olist.
Notre solution de gestion de la qualité
Dans cette troisième grande partie, nous allons explorer la gestion de la qualité des données d’Olist en utilisant une solution spécifique. Cette section se concentrera sur les différentes étapes et outils impliqués dans le processus de gestion de la qualité des données.
Organiser la collaboration avec un glossaire
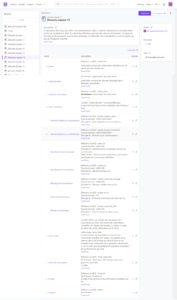 Un glossaire est un outil essentiel dans le cadre de la gestion de la qualité des données. Il s’agit d’un répertoire de termes et de définitions spécifiques utilisés dans le contexte des données de l’entreprise. L’utilité d’un glossaire réside dans sa capacité à créer un langage commun au sein de l’organisation. Voici comment il contribue à la gestion de la qualité des données :
Un glossaire est un outil essentiel dans le cadre de la gestion de la qualité des données. Il s’agit d’un répertoire de termes et de définitions spécifiques utilisés dans le contexte des données de l’entreprise. L’utilité d’un glossaire réside dans sa capacité à créer un langage commun au sein de l’organisation. Voici comment il contribue à la gestion de la qualité des données :
- Clarification des termes : Un glossaire définit précisément chaque terme technique ou métier utilisé dans les données, ce qui évite les malentendus et les interprétations erronées.
- Il permet aux équipes techniques mais aussi métiers de travailler de manière cohérente et de garantir que chaque membre de l’organisation a une définition commune de chaque terme.
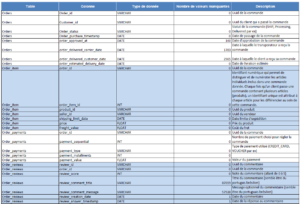
Inventorier les données à partir d’un dictionnaire
L’inventaire des données à partir d’un dictionnaire est une étape cruciale dans le processus de gestion de la qualité des données. Cette étape implique de répertorier toutes les données présentes dans l’entreprise, en les associant aux termes définis dans le glossaire. Cela permet de créer une vue complète et organisée de toutes les données disponibles, facilitant ainsi leur gestion et leur utilisation.
Extrait du dictionnaire développé
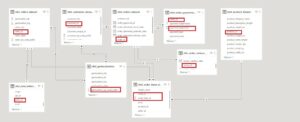
Localiser les données avec une cartographie
La cartographie des données est un autre aspect essentiel de la gestion de la qualité des données. Elle consiste à identifier l’emplacement précis de chaque donnée, en notant où elle est stockée, comment il est utilisé et qui en est responsable. Elle permet d’établir la jonction entre chacune des tables.
Le modèle de base de données est ici dit en « étoile » où la table principale olist_orders_dataset, agit comme table de fait.
Autour de cette table, plusieurs tables de dimensions y sont liées pour enrichir l’analyse. Les jointures entre ces tables sont alors établies via des identifiants uniques permettant de relier les commandes, les produits, les paiements, les évaluations clients, les informations géographiques, les clients, et les vendeurs pour une analyse complète de la plateforme d’e-commerce Brésilienne.
Contrôler la qualité grâce à des KPI
Les KPI (Key Performance Indicators), jouent un rôle central dans le contrôle de la qualité des données. Les indicateurs clés de performance (KPI) sont essentiels pour surveiller et améliorer la qualité des données.
Nous avons retenu les KPI suivants pour notre analyse:
- Taux de Valeurs Manquantes : Mesure le pourcentage de données manquantes dans chaque colonne ou table, identifiant les lacunes critiques dans les informations.
- Conformité des Types de Données : S’assure que les données sont stockées dans le bon format, comme les chaînes de caractères (VARCHAR) ou les dates (DATE), garantissant l’intégrité des types de données.
- Validité des Valeurs de Données : Vérifie que les données entrent dans les plages ou formats prévus, ce qui est crucial pour leur exactitude et leur applicabilité.
- Intégrité Référentielle : S’assurer que les relations entre les clés primaires et étrangères sont correctement maintenues, ce qui est fondamental pour la fiabilité des relations de données.
- Cohérence des Données : Vérifie l’uniformité et la cohérence des données à travers différentes tables, évitant les contradictions et les incohérences.
- Tendance Historique : Analyse l’évolution de la qualité des données au fil du temps, permettant de détecter les tendances d’amélioration ou de dégradation des données.
- Duplications : Identifie la présence de doublons, en particulier dans les clés primaires ou d’autres champs uniques, ce qui est vital pour maintenir l’unicité des enregistrements
Déployer la gestion de la qualité sur Openmetadata
Openmetadata est la solution choisie par notre équipe pour la gestion de la qualité des données.
En combinant un glossaire, un inventaire des données, une cartographie, des KPI et Openmetadata, cela nous permettra d’établir une base solide pour garantir la qualité de ses données. Cette approche méthodique permet à l’entreprise de maintenir des données fiables, précises et conformes, ce qui est essentiel pour son succès continu. Vous pouvez également retrouver une vidéo tutoriel que nous avons publié sur YouTube.
Standardisation et contrôle de qualité des données de manière continue
Un processus de standardisation des données suivi d’un contrôle de qualité continu a ensuite été mis en place sur Open Metadata. La standardisation vise à uniformiser les données, tandis que le contrôle de qualité en temps réel permet de détecter et de résoudre rapidement les problèmes de qualité des données, assurant ainsi leur fiabilité et leur intégrité pour le succès continu du projet. L’introduction du monitoring via les alertes Open Metadata est ici aussi un pas significatif vers une meilleure gestion de la qualité des données.
Optimisation des processus de gestion des données
La data est un processus itératif qui évolue chaque jour. Ainsi, certaines règles qui étaient vraies aujourd’hui ne le seront plus demain. Pour résoudre cela, il est primordial de maintenir et d’améliorer la qualité des données dès que l’on peut.
Conclusion
Dans le cadre de ce projet de gestion de la qualité des données pour Olist, nous avons tiré d’importantes leçons et expériences enrichissantes. La gestion de la qualité des données se révèle être une préoccupation majeure dans le domaine de la data, exigeant une multitude de compétences.
Nous avons adopté la méthode agile Scrum. La découverte du mode de fonctionnement et compétences individuelles des membres de l’équipe est cruciale pour maximiser l’efficacité de cette dernière. Grâce à une organisation bien définie il est possible de surmonter les défis initiaux.
Techniquement, les obstacles ont été limités, nous souligneront tout de même une vigilance nécessaire lors de la liaison entre le serveur de base de données et OpenMetadata. Tout n’est pas toujours évident et il faudra être capable de réadapter l’organisation des sprints en fonction des difficultés rencontrées. Trouver des solutions de contournement sera primordial pour mener à bien le projet dans les temps.
La méthode Agile Scrum a impacté la gestion de ce projet en favorisant la collaboration, l’adaptabilité et la transparence au sein de l’équipe. Elle a permis de prioriser les tâches, de réagir aux changements et de livrer régulièrement des résultats. Cette approche itérative assure une amélioration continue grâce aux retours des parties prenantes.
Pour réussir un projet de qualité des données, nous recommandons de se concentrer sur la valeur ajoutée de chaque livrable, en impliquant tous les acteurs, d’automatiser les processus pour optimiser l’efficacité, d’évaluer les résultats et de communiquer efficacement. Il est également extrêmement important d’organiser des moments d’échange réguliers pour un suivi constant du projet tout comme le fait de tirer des enseignements de chaque expérience vécue. Cette expérience renforce notre engagement envers l’excellence opérationnelle et la fiabilité des données, fondamentales pour le succès continu de notre projet.
il ne peut pas avoir d'altmétriques.)