
Citation
L'auteur
Charles Ngando Black
(cngando@msn.com) - Institute for Data & AI Practices
Copyright
Déclaration d'intérêts
Financements
Aperçu
Contenu
Une gouvernance historiquement centrée sur la connaissance des données
Depuis deux décennies, les organisations ont investi dans des dispositifs visant à produire une connaissance structurée de leurs données. Ces dispositifs ne suivent pas la transformation des données elles-mêmes — qui relève de la chaîne DIKW — mais celle des métadonnées qui les décrivent, les qualifient et les relient, selon une dynamique propre à la chaîne MIKW (analogie avec DIKW où M représente la métadonnée).
Profilage, catalogage, lignage ou encore scoring qualité participent ainsi à un même mouvement : transformer des observations fragmentées en une connaissance organisée du patrimoine de données. Cette connaissance est progressivement enrichie, historisée, rendue accessible et exploitable par les acteurs de l’organisation.
Cette évolution a produit des effets réels. Les organisations comprennent mieux leurs données, identifient leurs faiblesses, structurent leurs référentiels, et outillent leurs processus de contrôle.
Mais cette progression s’interrompt à un point précis : celui où la donnée, devenue information puis connaissance, doit se prolonger dans une décision.
Or, la décision constitue une forme distincte. Elle n’est pas une donnée enrichie. Elle est un acte situé, contraint, qui engage l’organisation et qui s’inscrit dans un cadre d’exigences explicites. C’est à ce niveau que la gouvernance révèle aujourd’hui sa limite : elle produit de la connaissance, mais ne dit pas ce que cette connaissance doit permettre de décider, ni dans quelles conditions.
Une architecture continue, de la connaissance à la décision
La gouvernance des données ne peut pas être comprise comme une juxtaposition de capacités. Elle repose sur une chaîne continue qui relie trois niveaux :
- La production de connaissance sur les données,
- La définition du cadre décisionnel dans lequel elles s’inscrivent,
- L’évaluation de leur adéquation à ces décisions.
Ces trois niveaux correspondent à trois familles de capacités :
- Les capacités d’intelligence des données, qui produisent la connaissance (chaîne MIKW)
- Les capacités de cadrage, qui définissent les décisions et les exigences
- Les capacités de pilotage, qui évaluent la fiabilité des décisions fondées sur les données
La logique n’est pas additive. Chaque famille donne son sens à la précédente. Sans cadrage, l’intelligence des données reste sans finalité. Sans pilotage, elle reste sans effet au moment où la décision doit être prise.
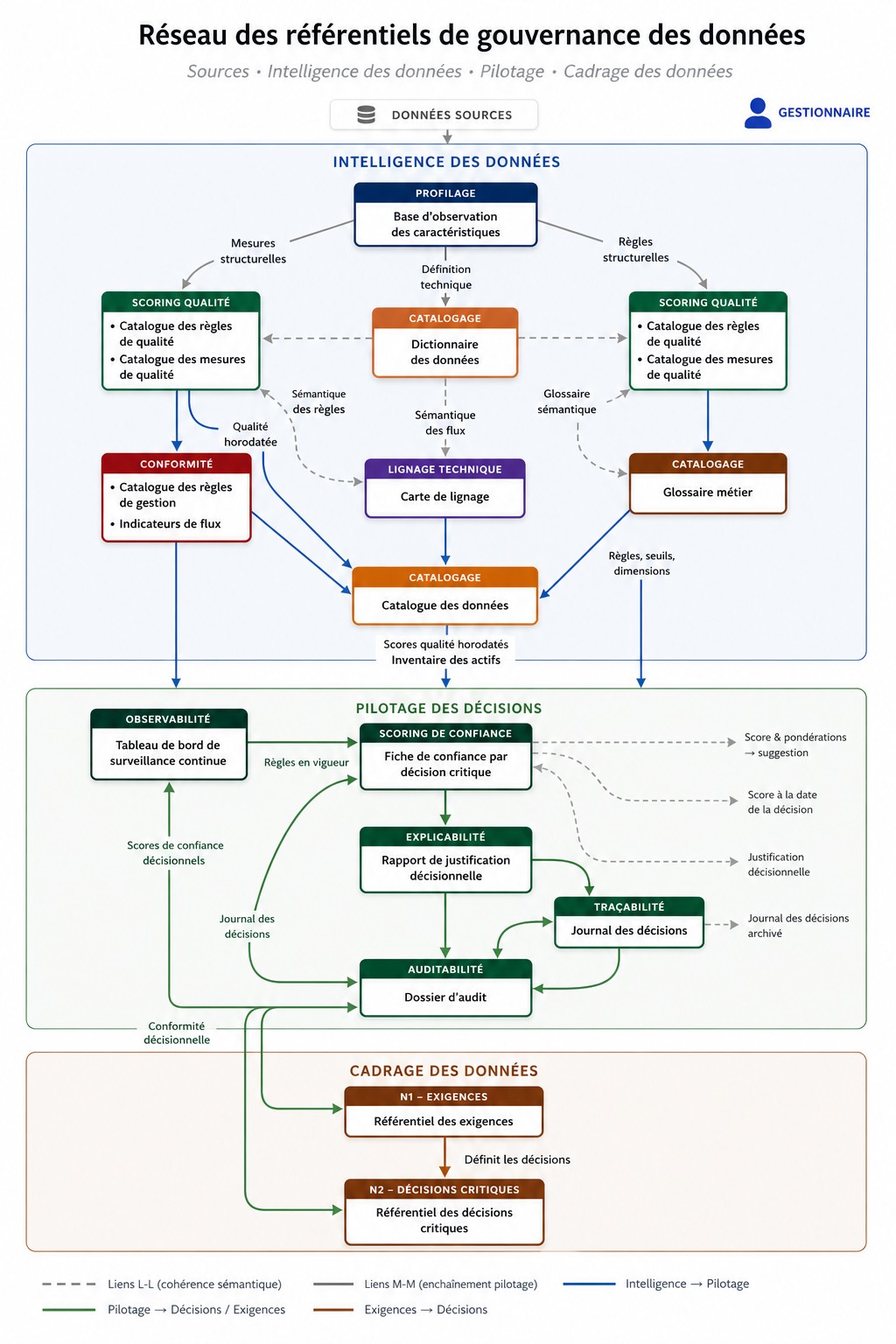
Les capacités d’intelligence des données
Les capacités d’intelligence constituent le socle historique de la gouvernance. Elles produisent une connaissance structurée du patrimoine de données en organisant la collecte, la transformation et la restitution des métadonnées.
Le profilage intervient en amont. Il observe les données à la source, indépendamment de toute règle, et en restitue les caractéristiques structurelles : distributions, taux de nullité, valeurs aberrantes. Il produit une photographie objective du patrimoine, souvent en décalage avec la perception qu’en ont les équipes. Cette observation constitue une base de référence, historisée, qui permet de suivre les évolutions dans le temps et de détecter des dérives.
Sur cette base, le scoring qualité introduit une logique normative. Il applique des règles définies par l’organisation — complétude, exactitude, cohérence, fraîcheur — et mesure l’écart entre l’état observé et l’état attendu. Là où le profilage décrit, le scoring évalue. Il produit des indicateurs comparables, mobilisables dans le temps, et permet de structurer des processus de correction et d’amélioration.
Ces deux premières chaînes produisent une connaissance encore technique. Le catalogage vient lui donner une forme exploitable. En structurant un glossaire métier, un dictionnaire des données et un catalogue des actifs, il rend les données compréhensibles, trouvables et partageables. Il relie les définitions métier aux objets techniques, et permet aux acteurs non techniques de se réapproprier le patrimoine informationnel.
Le lignage prolonge cette compréhension en introduisant une dimension dynamique. Il retrace les transformations de la donnée entre systèmes, documente les règles de calcul et permet de remonter à l’origine d’une anomalie ou d’anticiper l’impact d’une modification. Il rend visible ce qui, sans lui, reste implicite dans les architectures.
Enfin, la conformité aux règles de gestion établit un lien direct entre les exigences fonctionnelles ou réglementaires et les données. Elle vérifie que les conditions d’usage des données sont respectées et matérialise les écarts sous forme de non-conformités exploitables.
Ces cinq chaînes forment un ensemble cohérent. Elles produisent une connaissance riche, structurée et actionnable des données. Mais cette connaissance reste suspendue à une question qu’elle ne traite pas : que doit-on en faire ?
Les capacités de cadrage : définir le périmètre décisionnel
Les capacités de cadrage introduisent une dimension absente des approches traditionnelles : la définition explicite de ce qui doit être gouverné.
La première opération consiste à modéliser les décisions critiques. Contrairement à une idée répandue, ces décisions ne se déduisent pas des données disponibles. Elles s’identifient à partir des processus métier, des obligations réglementaires et des arbitrages stratégiques de l’organisation. Leur modélisation suppose un travail conjoint entre métiers, fonctions de contrôle et équipes de gouvernance.
Chaque décision est alors définie précisément : son périmètre, les acteurs qui y participent, les données qu’elle mobilise, les règles qui l’encadrent et les niveaux de confiance acceptables. L’ensemble est structuré dans un référentiel des décisions critiques, qui devient le point d’ancrage du dispositif. Là où le catalogue des données décrit ce que sont les données, ce référentiel décrit ce qu’elles doivent permettre de fonder.
Ce travail serait incomplet sans une formalisation explicite des exigences. Celles-ci peuvent être réglementaires, stratégiques ou financières. Elles définissent non seulement pourquoi une décision est critique, mais aussi à quel niveau elle doit être gouvernée. Elles déterminent les seuils d’acceptabilité, les niveaux de risque tolérés et les obligations auxquelles l’organisation est soumise.
Le référentiel des exigences structure ces éléments et les rend exploitables. Il ne constitue pas une simple liste de contraintes : il définit le niveau d’exigence qui doit être appliqué aux décisions et, par extension, aux données qui les fondent.
L’architecture prend pleinement sens dans l’alignement entre ces deux référentiels. Les exigences définissent les décisions à gouverner et leur niveau d’exigence ; les décisions, en retour, permettent de démontrer la conformité de l’organisation à ces exigences. Ce lien bidirectionnel donne à la gouvernance sa cohérence verticale, depuis les sources de données jusqu’aux obligations stratégiques et réglementaires.
Sans ce cadrage, les capacités d’intelligence restent sans direction. Les seuils appliqués aux données sont arbitraires, les analyses sont déconnectées des enjeux, et la gouvernance ne sait pas ce qu’elle doit servir.
Les capacités de pilotage : transformer la connaissance en confiance décisionnelle
Les capacités de pilotage interviennent au moment où la donnée doit être mobilisée pour décider. Elles répondent à une limite essentielle : la valeur d’une donnée ne peut être évaluée indépendamment de la décision qu’elle doit fonder.
Le scoring de confiance constitue la première de ces capacités. Contrairement au scoring qualité, il ne mesure pas la qualité intrinsèque des données, mais leur adéquation à une décision donnée. Il est nécessairement contextuel : un même jeu de données peut être suffisant pour une décision opérationnelle et insuffisant pour une décision réglementaire. Le score de confiance traduit cette adéquation en fonction du niveau de risque, des exigences applicables et du rôle du décideur.
Sur cette base, l’aide à la décision produit une suggestion argumentée. Elle mobilise les données disponibles, les règles définies dans le référentiel des décisions critiques et les décisions comparables passées pour proposer une orientation. Elle intervient en amont de l’acte décisionnel, sans se substituer au décideur, qui conserve la responsabilité de valider, ajuster ou rejeter la proposition.
L’explicabilité permet de rendre cette suggestion intelligible. Elle détaille les facteurs qui influencent le score de confiance, les indicateurs en écart et les règles mobilisées. Elle répond à une exigence opérationnelle — permettre au décideur de comprendre — mais aussi à une exigence réglementaire, notamment dans le cadre des décisions automatisées.
La traçabilité décisionnelle prolonge cette logique en permettant de reconstituer, a posteriori, l’ensemble du contexte ayant conduit à une décision : données utilisées, règles appliquées, niveau de confiance, acteur impliqué. Elle ne se limite pas à enregistrer : elle permet de restituer un dossier complet, mobilisable en cas de contrôle ou de contestation.
L’auditabilité ajoute une dimension supplémentaire. Elle ne consiste pas à retracer ce qui a été fait, mais à vérifier que cela a été fait conformément aux règles en vigueur au moment de la décision. Elle permet à un tiers de s’assurer que les processus ont été respectés et que les écarts éventuels ont été justifiés.
Enfin, l’observabilité introduit une logique préventive. Elle surveille en continu les flux de données alimentant les décisions critiques et détecte les dérives avant qu’elles n’affectent les résultats. Elle permet d’intervenir en amont, là où les autres capacités interviennent a posteriori.
Ces capacités de pilotage transforment la connaissance des données en un élément directement mobilisable pour décider. Elles ne remplacent pas les capacités d’intelligence : elles les prolongent dans un contexte décisionnel.
Conclusion
Les organisations ont construit des capacités solides pour produire une connaissance de leurs données. Ce socle constitue une avancée majeure, mais il ne suffit plus.
La gouvernance reste incomplète tant qu’elle ne couvre pas deux dimensions essentielles : la définition explicite des décisions à gouverner et l’évaluation de la fiabilité des décisions fondées sur les données.
L’intégration des capacités de cadrage et de pilotage ne remet pas en cause l’existant. Elle en constitue le prolongement naturel. Elle permet de relier la connaissance des données aux finalités réelles de l’organisation.
Cette évolution transforme la gouvernance des données en un système complet, articulant production de connaissance, structuration du cadre décisionnel et évaluation de la confiance.
Autrement dit, elle permet de passer d’une gouvernance des données à une gouvernance des décisions fondées sur les données.
Bibliographie
Ouvrages de référence
Ngando Black, C. (2024). Data Office and Chief Data Officers: The Definitive Guide. Books on Demand.
Ngando Black, C. (2025). Connaissance des données : l’art d’opérationnaliser la gouvernance des données. Management & Datascience.
Références réglementaires
Commission européenne (2016). Règlement (UE) 2016/679 du 27 avril 2016 relatif à la protection des personnes physiques à l’égard du traitement des données à caractère personnel (RGPD). Journal officiel de l’Union européenne.
Commission européenne (2024). Règlement (UE) 2024/1689 du 13 juin 2024 établissant des règles harmonisées concernant l’intelligence artificielle (AI Act). Journal officiel de l’Union européenne.
Commission européenne (2009). Directive 2009/138/CE du 25 novembre 2009 sur l’accès aux activités de l’assurance et de la réassurance et leur exercice (Solvabilité II). Journal officiel de l’Union européenne.
Ressources complémentaires
Taylor, J. & Raden, N. (2007). Smart (Enough) Systems : How to Deliver Competitive Advantage by Automating Hidden Decisions. Prentice Hall. — Ouvrage fondateur sur la gouvernance des décisions opérationnelles et la modélisation des règles métier. Directement pertinent pour les capacités de cadrage et d’aide à la décision.
Von Halle, B. & Goldberg, L. (2010). The Decision Model : A Business Logic Framework Linking Business and Technology. CRC Press. — Propose une méthode formelle de modélisation des décisions critiques à partir des exigences métier. Ancre directement la section II de l’article.
Molnar, C. (2022). Interpretable Machine Learning : A Guide for Making Black Box Models Explainable (2e éd.). — Référence de fait sur l’explicabilité des modèles, directement liée à la capacité d’explicabilité et aux obligations RGPD art. 22 et AI Act.
Goodman, B. & Flaxman, S. (2017). European Union regulations on algorithmic decision-making and a « right to explanation ». AI Magazine, 38(3), 50-57. — Article académique qui ancre rigoureusement le lien entre explicabilité, traçabilité décisionnelle et cadre réglementaire européen.
il ne peut pas avoir d'altmétriques.)