
Citation
Les auteurs
Mourad AINOUCHE
- Groupe Crédit AgricoleAlexandre ALFOCEA
- La Banque PostaleJérémie ASSERAF
- Universal Music GroupMarie ESCLOZAS
- AXA
Copyright
Déclaration d'intérêts
Financements
Aperçu
Contenu
Introduction
Nous avons participé à un data challenge dont le but était de prédire les résultats de plus d’un million de transactions au sein des marchés publics européens.
Les juristes définissent un marché public comme un contrat conclu à titre onéreux par un ou plusieurs acheteurs publics avec un ou plusieurs opérateurs économiques publics ou privés, pour répondre à leurs besoins en matière de travaux, de fournitures ou de services. Dit plus simplement, quand des acheteurs publics (États, collectivités territoriales ou établissements publics) ont besoin d’un produit ou service, ils utilisent ces marchés européens pour attribuer les contrats selon certains critères.
Pour ce challenge, nous avions à disposition une base de données, la même pour tous les participants, et des outils informatiques et statistiques de notre choix. Ici, nous avons utilisé Python, R et Jupyter. Nous avions aussi au sein de l’équipe des profils complémentaires pour répartir les tâches entre préparer et comprendre les données et la construction et ajustement des modèles. Par conséquent, cela nous a permis de mener à bien ce projet dans un temps limité, nous avions au total 30 heures pour rendre la totalité des modèles.
Dans cet article, nous allons présenter la méthode que nous avons mise en oeuvre pour répondre à la question suivante : Quel sera le profil du gagnant d’un appel d’offres pour des marchés publics européen (PME ou grande entreprise) ?
Dans un premier temps, nous allons présenter la base de données et quelques statistiques descriptives, nous enchainerons par la préparation des données et par la présentation de ce que nous aurions fait différemment si nous avions eu plus de temps . Enfin, nous terminerons par une conclusion.
Présentation des données
La base de données que nous traitons rassemble plus de deux millions d’observations et une vingtaine de variables. Elle contient des informations sur l’attribution des marchés publics européens. Cette base de données contient des variables catégorielles qui peuvent contenir jusqu’à plusieurs dizaines de niveaux. Nous avons aussi des variables continues ainsi qu’une variable temporelle qui représente les années. Cette dernière peut être interprétée comme l’année à laquelle un marché public a été attribué à un type particulier d’entreprise.
La variable cible de notre étude se nomme ”B_CONTRACTOR_SME”. C’est une variable catégorielle avec deux niveaux (Oui et Non). Elle pourra être interprété de la manière suivante :
- oui, le marché est susceptible d’être attribué à des petites et moyennes entreprises.
- Non, le marché n’est pas susceptible d’être attribué à des petites et moyennes entreprises.
Ci-dessous un graphique qui résume la distribution de cette variable. Nous remarquons que la distribution entre le oui (Y sur le graphique) et le non (N sur le graphique) est assez homogène. Ce qui est une bonne nouvelle pour la modélisation. En effet, nous n’aurons pas à faire face à un problème de données non balancées. Malheureusement, ce graphique nous apprend aussi que cette variable contient des valeurs manquantes. Ces dernières représentent plus de 80% des observations. Par conséquent, nous aurons des choix cruciaux à faire lors de la phase de traitement des données.
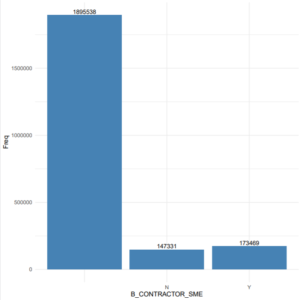
Figure 1 : Distribution de la variable B_CONTRACTOR_SME
La phase d’exploration de données nous à permis de mettre en avant des points intéressants. En analysant la variable MAIN_ACTIVITY (graphique ci-dessous), nous nous apercevons que les principaux appels d’offres dans le marché européen concernent le domaine de la santé (pratiquement 20% des observations), de l’éducation, et de la défense.
Nous observons la même chose en analysant la variable CPV. Cette dernière constitue un système de classification unique pour les marchés publics visant à standardiser les références utilisées pour décrire l’objet d’un marché par les pouvoirs adjudicateurs et les entités adjudicatrices (SIMAP). Cette variable de classification à quatre niveaux peut paraître très variés et peu homogènes alors qu’elle peut être simplifiée à son premier niveau en ne gardant que les deux premiers chiffres.
Ces affirmations confirment les données fournies par l’Union européenne. Effectivement, l’UE dépensent en moyenne plus de 11% de son PIB dans le domaine de la santé.
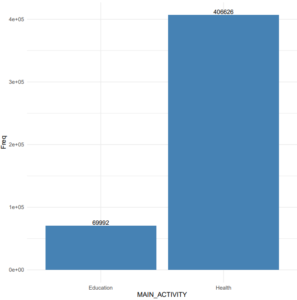
Figure 2 : Distribution de la variable MAIN_ACTIVITY
Traitement des données
Préparation des variables
Afin d’établir les meilleures prédictions possibles, il est important de mesurer le temps de travail. En effet, lors du data challenge, étant soumis à une deadline, les équipes avaient un créneau très restreint pour établir leurs prédictions : une journée et quelques heures.
Nos premières réflexions étaient focalisées sur un sujet essentiel dans le data engineering : Comment traiter les données manquantes ? Plusieurs variables avaient des valeurs manquantes qui pouvaient être plus ou moins conséquentes. En effet, la variable à prédire en faisait partie et était composée d’une grande majorité de données manquantes (1 895 538 sur 2 216 338 soit 85%).
Exemples de réflexions :
- Supprimer les colonnes à majorité de valeur manquantes.
- Remplacer les valeurs manquantes catégorielles par les valeurs les plus fréquentes.
- Remplacer les valeurs numériques par la moyenne.
- Remplacer les valeurs manquantes numériques par les valeurs les plus fréquentes.
Suppression des valeurs manquantes de la variable cible
Finalement, nous avons opté pour garder uniquement les lignes où la variable à prédire « B_CONTRACTOR_SME » était présente. Nous avons donc travaillé sur 320 800 lignes.

Remplacement des valeurs manquantes des variables explicatives
Vient ensuite la réflexion du remplacement des valeurs manquantes dans les variables explicatives. Bien que la variable cible n’avait plus de valeurs manquantes, ce n’était pas le cas pour les variables explicatives. En effet, nous avons choisi de remplacer les valeurs manquantes catégorielles et numériques par les valeurs les plus fréquentes.
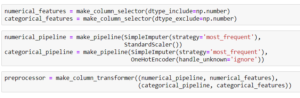
Afin d’obtenir les résultats souhaités, nous avons mis en place des pipelines afin de traiter les variables. La démarche est différente entre les variables numériques et catégorielles :
- Numériques : l’objectif est de remplacer les valeurs manquantes par la valeur la plus fréquente et d’implémenter un StandardScaler. Le Standard Scaler a pour objectif de standardiser les variables en soustrayant la moyenne et en divisant par l’écart type.
La formule est : z = (x – u) / s (avec u la moyenne et s l’écart type). - Catégorielles : l’objectif est de remplacer les valeurs manquantes par la valeur la plus fréquente (le mode) et d’implémenter un One Hot Encoder. Le One Hot Encoder a pour objectif de transformer les valeurs catégorielles en valeurs numériques binaires.
![]()

Un point que nous voulons noter est le choix de la stratégie de remplacement des valeurs numériques manquantes. Nous avons opté pour la stratégie ‘most frequent’ au lieu de remplacer par la valeur moyenne ou médiane car une analyse relativement rapide nous avait démontré que remplacer par la valeur la plus fréquente était légèrement plus fiable. Nous étudierons dans les limites les autres solutions que nous aurions pu implémenter si nous avions eu plus de temps.
Création de pipeline
On implémente ensuite notre pipeline preprocessor dans un nouveau pipeline qui va associer preprocessor au modèle RandomForestClassifier :
![]()
Cette étape ne va donc pas modifier notre dataset, mais va être associée à un modèle de prédiction, ici le RandomForest.
Optimisation des hyperparamètres
Nous avons décidé de procéder à une optimisation des hyperparamètres en utilisant la méthode du RandomizedSearch. Cette méthode permet d’optimiser des hyperparamètres du modèle choisi.
Pour être précis, RandomizedSearch calcule les performances du modèle pour chaque valeur d’hyper-paramètre choisie de façon aléatoire. Nous avons opté pour l’optimisation des différents hyperparamètres du randomforest suivants :
- Nombre d’arbres dans la forêt.
- Nombre maximal de variables pour splitter un nœud.
- Nombre maximal de niveaux par arbre de décision.
- Nombre minimal d’observations placées dans un nœud avant le split.
- Nombre minimal d’observations dans un nœud de feuille.
Cependant, notons que nous avons comparé les résultats obtenus entre les hyper-paramètres optimisés et les hyper-paramètres par défaut et nous avons retenu le modèle avec les hyper-paramètres par défaut car il semble être plus performant. En effet, pour effectuer une recherche d’hyper-paramètres avec le RandomizedSearch, il faut comparer un grand nombre de compositions différentes, ce qui peut prendre un temps considérable, relativement au data challenge.
Évaluation du modèle
Nous avons ensuite défini une fonction (ci-dessous le code Python) permettant de présenter les performances de notre modèle. Celle-ci calcule l’Aire sous la courbe de la courbe ROC, dite aussi de receiver operating Characteristic.
![]()

Cette représentation graphique est créée en traçant le taux de vrais positifs (sensibilité) par rapport au taux de faux positifs (1-spécificité) à divers seuils de calculs. Ensuite, l’aire sous la courbe de ce graphique est calculée, elle comprise entre zéro et un. Plus cette aire est importante, plus le modèle à de bonnes performances (Kumar et al, 2011).
Résultats
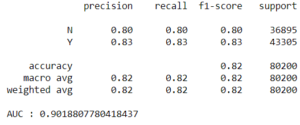
Avec RandomizedSearch:
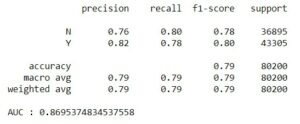 Par défaut:
Par défaut:
Discussion et limites du modèle
La modélisation statistique permet d’analyser des phénomènes réellement observés pour ensuite en construire une représentation simplifiée. L’étude que nous avons réalisée consiste à prédire les profils des gagnants des appels d’offres au sein des marchés publics européens. Le modèle que nous avons construit est un Random Forest. Cette technique fait partie des “ensemble techniques “ et plus précisément des modèles dit de “Bagging”.
Le jeu de données que nous avions à disposition était assez conséquent : plus de deux millions d’observations et une vingtaine de variables (catégorielles et continues). Par conséquent, une phase d’exploration approfondie était nécessaire pour comprendre comment étaient structurées les informations que nous avions à disposition.
Les statistiques descriptives réalisées nous ont révélé des valeurs manquantes. Nous avons décidé de les supprimer par manque de temps (pour la variable cible). En effet, dans l’absolu il est préférable de les garder. Ainsi, nous évitons de perdre de l’information dans notre modèle, et celui-ci ne sera que plus robuste. Donc au lieu de supprimer les variables manquantes ou des les imputer avec la moyenne ou le mode, il existe des méthodes plus “sophistiquées” pour le faire. Nous pouvons citer les arbres de décision ou encore la méthode k-plus proche voisin (KNN).
La première méthode consiste à donner pour chaque individu une valeur personnalisée en fonction des autres données existantes. Cette méthode consiste à attribuer la valeur la plus fréquente de la variable manquante au nœud de l’arbre de décision. La deuxième méthode consiste à estimer les valeurs manquantes en recherchant les k-individus les plus proches, en calculant la distance sur les autres variables renseignés (cette technique repose sur le calcul de distance Euclidienne). Ensuite, nous remplaçons la valeur manquante par la moyenne de ces k-individus. L’application de ces techniques nécessite une période de calcul très longue et surtout des machines puissantes.
L’autre limite de notre modèle est le choix des variables explicatives à intégrer dans le modèle. En effet, nous avions plusieurs variables catégorielles que nous avons dû encoder en utilisant la technique du One-Hot encoding. Par conséquent, nous nous sommes retrouvés avec des centaines de variables explicatives.
Dans ce cas, il aurait été judicieux de mettre en œuvre des techniques pour sélectionner les variables les plus importantes pour notre modèle. Il existe une méthode appelée Permutation Feature Importance. Cette dernière consiste à opposer les performances du modèle de prédiction avec et sans la variable à évaluer. On peut se baser sur le taux d’erreur ou tout autre métrique pour évaluer les modèles de machine learning (Fisher et al, 2018).
Conclusion
Dans le cadre de la réponse à la question ¨Quel sera le profil d’un gagnant d’un appel d’offres pour des marchés publics européens (PME ou grande entreprise) ?¨, nous avons commencé par analyser toutes les données, la donnée cible étant de format binaire mais à 85% vide. Nous avons choisi de développer le modèle à partir des données cibles disponibles et de remplacer les valeurs manquantes des variables numériques et catégorielles.
Nous avons ensuite créé un pipeline et optimisé les hyperparamètres pour produire un modèle de Random Forest qui calculait un Area Under Curve (AUC) à 90,19% juste sur nos valeurs tests. Au moment d’appliquer le modèle sur les valeurs réelles de prédiction, ce même modèle atteint 96% de prédictions correctes.
Nous avons optimisé notre modèle au maximum même si nous aurions pu utiliser d’autres techniques de preprocessing de données, comme un KNN ou Permutation Feature Importance.
Comprendre par la pratique comment développer des modèles complets de machine learning dans un temps restreint et l’importance d’avoir différents profils (analyse de données et data science), travaillant en parallèle sur chacune des étapes présentées, comme c’est le cas en entreprise, a fait de ce data challenge une expérience très enrichissante.
Bibliographie
Fisher, A., Rudin, C., & Dominici, F. (2018). All models are wrong but many are useful: Variable importance for black-box, proprietary, or misspecified prediction models, using model class reliance. arXiv preprint arXiv:1801.01489, 237-246.
Molnar, C. (2020). Interpretable Machine Learning. Lulu. com.
Kumar, R., & Indrayan, A. (2011). Receiver operating characteristic (ROC) curve for medical researchers. Indian pediatrics, 48(4), 277-287.