
Citation
L'auteur
Gilles Paché
(gilles.pache@univ-amu.fr) - Aix-Marseille Université
Copyright
Déclaration d'intérêts
Financements
Aperçu
Contenu
Les algorithmes occupent une place centrale dans les décisions qui façonnent durablement nos vies, jusqu’à l’entrée dans l’enseignement supérieur en France (Mizzi, 2025). Leur capacité à analyser de vastes quantités de données et à aider (voire prendre) des décisions semble a priori dénuée de tout préjugé, leur conférant une apparente ‒ mais en fait fausse ‒ objectivité. En effet, une telle perception d’objectivité est trompeuse. Les algorithmes, loin d’être impartiaux, sont le fruit de choix humains à chaque étape de leur développement. Les données qui les alimentent, les modèles qu’ils appliquent, et les critères décisionnels sous-jacents sont influencés par des valeurs humaines. En bref, les algorithmes reproduisent et amplifient un ensemble de biais sociaux, économiques et politiques, et l’illusion d’objectivité masque leur vraie nature : ils sont le pur produit des choix des concepteurs et, plus ou moins directement, d’inégalités structurelles présentes dans toute société. Les dilemmes moraux soulevés par l’équité algorithmique sont donc multiples et complexes, l’un des enjeux majeurs résidant d’ailleurs dans la définition même de l’équité : doit-elle privilégier l’égalité des chances ou l’égalité des résultats ? Comment garantir des décisions équitables à la fois pour des individus et pour des groupes d’individus dans leur ensemble ?
Ces questions d’importance soulignent la nécessité absolue d’une réflexion éthique sur les algorithmes dans un contexte d’IA. Elles ne sont pas uniquement d’ordre théorique : elles entraînent des conséquences concrètes et directes sur les existences de millions de personnes. On peut ici évoquer, au sens métaphorique, un véritable « théâtre algorithmique de l’équité » lié au fait que les algorithmes, dans leur fonctionnement et leurs décisions, sont comme des acteurs dans un théâtre où les notions de justice, d’équité et d’égalité sont mises en scène (la Figure 1, adaptée de Garcia et al. [2024], en visualise pédagogiquement les différences), et les « rôles » qu’ils y jouent sont in fine influencés profondément par les humains. Compte tenu des enjeux en présence, il s’avère par conséquent essentiel de réfléchir à la manière dont les algorithmes sont conçus et utilisés, en impliquant divers acteurs et en garantissant la transparence dans les processus décisionnels. L’équité algorithmique ne peut se réduire à un simple exercice technique, elle doit être nourrie par une réflexion éthique, sachant qu’une machine ne peut faire preuve de sympathie au sens de Smith (1759 [2014]), c’est-à-dire se mettre à la place des autres pour comprendre leurs émotions. Dans cette perspective, l’objectif n’est pas seulement de concevoir des algorithmes plus « justes », mais de réfléchir à une société plus équitable à travers l’utilisation consciente de la technologie.
Figure 1. Une clarification sémantique préalable sous forme visuelle
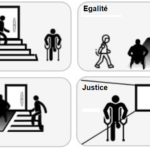
Source : d’après Garcia et al. (2024).
Algorithmes : quand est-ce qu’on biaise ?[1]
Les algorithmes sont souvent perçus par le grand public comme des arbitres impartiaux dans un monde de plus en plus complexe et difficile à déchiffrer, où la fatigue informationnelle devient une réalité omniprésente, affectant les capacités cognitives des individus (Gault & Medioni, 2022). Une telle perception repose sur l’idée que la data science fonctionnerait indépendamment des valeurs humaines. Pourtant, les algorithmes sont conçus et développés par des humains (pour l’instant !), et formés à partir de données historiques, souvent biaisées, puis optimisés dans des cadres définis selon des objectifs spécifiques. Ces derniers sont toujours influencés par des contextes culturels, politiques et économiques particuliers. Prenons par exemple les algorithmes utilisés pour la police prédictive, qui cherchent à identifier les lieux et moments où des délits pourraient se produire, en se basant pour cela sur des données historiques de criminalité. À première vue, la méthode semble être une manière d’allouer les ressources policières de façon optimale. Cependant, elle soulève une inquiétude majeure : ces algorithmes risquent de perpétuer des préjugés historiques, en ciblant de manière disproportionnée certaines communautés déjà vulnérables et sur-représentées dans les données criminelles.
L’exemple de COMPAS est particulièrement frappant à cet égard (voir l’Illustration n° 1). Sa mission, à savoir prédire avec précision la criminalité à venir (Brennan & Dieterich, 2018), omet de prendre en compte l’équité sociale : est-il réellement juste de se fonder sur des données biaisées pour anticiper des comportements futurs ? Cette dimension de l’IA devient encore plus inquiétante lorsqu’on se penche sur des cas concrets rappelant les pires dystopies. Par exemple, dans les années 2010, deux trafiquants de drogue du comté de Broward en Floride, ayant des profils quasiment identiques, se sont vu attribuer par le système COMPAS des niveaux de risque de récidive très contrastés, simplement en fonction de leur couleur de peau. Le trafiquant blanc a reçu une note de 3, indiquant un faible risque, tandis que le trafiquant noir a été évalué à 10, signalant un risque élevé (voir la Figure 2). Une telle discrimination ne surprendra sans doute pas celles et ceux qui connaissent la persistance des préjugés raciaux, non seulement aux États-Unis, mais également dans de nombreuses sociétés à travers le monde, y compris en France. Ceci met en lumière les dérives potentielles des systèmes algorithmiques quand ils reproduisent des injustices profondément enracinées.
Illustration n° 1. COMPAS : une « aide à la décision » controversée
Un algorithme peut-il prédire correctement le risque de récidive ? Aux États-Unis, c’est exactement ce que fait le programme COMPAS (Correctional Offender Management Profiling for Alternative Sanctions), utilisé par de nombreuses juridictions locales comme aide à la décision pour les juges, ses défenseurs arguant que COMPAS est plus objectif et moins biaisé que les humains. C’est pourquoi deux professeurs d’informatique au Dartmouth College ont eu l’idée de comparer ses performances avec celles de personnes non expérimentées, recrutées sur Internet. Ils leur ont présenté les profils de centaines de condamnés, avec des informations sur leur genre, leur âge et leurs antécédents judiciaires. Ces personnes devaient ensuite répondre à la question suivante : « Pensez-vous que cette personne commettra un autre crime d’ici deux ans ? ». Dans 67 % des cas en moyenne, les humains ont vu juste, là où COMPAS affiche un score de 65,2 % – des résultats relativement proches. Qui plus est, si les humains ne disposaient que de quelques données sur les personnes condamnées (genre, âge et antécédents judiciaires), l’algorithme, quant à lui, prend ses décisions en se basant sur 127 critères. Ce n’est pas la première fois que l’efficacité de COMPAS est mise en doute. En 2016, une enquête de ProPublica estimait non seulement que le logiciel était peu fiable, mais aussi qu’il surévaluait largement le risque de récidive des Afro-Américains (sur ce point, voir notamment Beaudouin & Maxwell [2023]).
Source : d’après Le Monde, 17 janvier 2018.
Figure 2. À la tête du client : exemple de discrimination algorithmique

Source : Document ProPublica (2016).
L’idée selon laquelle les algorithmes peuvent prendre des décisions « moralement neutres » est finalement un mythe dangereux (Xavier, 2025). À chaque étape du développement d’un algorithme, les choix humains façonnent ses résultats, sachant que les ingénieurs choisissent les données pour entraîner le modèle, décident des fonctionnalités à prioriser et fixent des seuils pour des taux d’erreur acceptables. En bref, ces choix intègrent les valeurs humaines dans l’algorithme, que ce soit intentionnellement ou non. Prenons le cas d’algorithmes de notation de crédit par les institutions financières, qui évaluent la solvabilité d’un individu en fonction de diverses données, notamment l’historique de paiement, le revenu, et même son code postal de résidence. Bien que ces algorithmes visent à minimiser les risques pour les prêteurs, ils pénalisent souvent les personnes issues de quartiers à faible revenu ou marginalisés (le fameux syndrome du « 9-3 » [Troussel, 2020]). En considérant les codes postaux comme un indicateur de risque financier, les algorithmes perpétuent les inégalités économiques et renforcent les obstacles existants à l’accès aux services financiers (pour une analyse de la gouvernance des algorithmes d’IA dans le secteur financier, voir Dupont et al. [2020]).
L’un des aspects les plus insidieux de l’illusion d’objectivité est qu’elle crée le plus souvent un faux sentiment de légitimité. Les décisions prises par les algorithmes sont perçues comme fiables simplement parce qu’elles sont prises par des machines qui s’appuient sur la somme de toutes les connaissances humaines (Leffer, 2023), et une telle vision rend plus difficile la remise en cause de résultats biaisés ou préjudiciables. Lorsqu’un juge d’une Cour ou un responsable RH prend une décision de recrutement biaisée, il est facile de remettre en question ses motivations et/ou ses préjugés, et de le tenir ainsi pour responsable. Lorsqu’un algorithme produit le même résultat, il est plus susceptible d’être accepté comme juste et impartial, même s’il perpétue des injustices existantes. En bref, les algorithmes ne sont pas impartiaux ; ce sont des outils créés par des humains, façonnés par les valeurs qu’ils portent et déployés dans des contextes sociaux intrinsèquement inégaux. Reconnaître un tel fait est l’étape préalable pour relever les défis éthiques posés par la prise de décision algorithmique, conduisant à modifier notre façon de considérer les algorithmes, non pas comme les porteurs d’une sorte de Vérité immanente, mais comme des acteurs non-humains ayant une capacité d’agentivité au sens de Latour (2006), et qui reflètent les préjugés, les hypothèses et les priorités de leurs créateurs.
Pour dépasser l’illusion de l’objectivité, la société doit exiger davantage de transparence et de responsabilité dans la diffusion des algorithmes, en les ouvrant à des audits externes, en s’assurant que les données utilisées pour former les modèles sont représentatives et exemptes de biais, tout en impliquant diverses parties prenantes dans le processus de conception. Cela signifie également reconnaître que l’équité ne peut pas être entièrement capturée par des formules mathématiques, elle est une valeur profondément humaine qui nécessite une réflexion éthique et un débat public permanents. Dit autrement, l’illusion de l’objectivité des algorithmes n’est pas seulement un problème technique, c’est aussi le reflet d’une crise morale (Nowotny, 2021). Alors qu’ils gouvernent de plus en plus des aspects cruciaux de la vie quotidienne, nous devons affronter la réalité inconfortable selon laquelle les algorithmes sont loin d’être impartiaux. Ils résultent de choix façonnés par des forces culturelles et sociétales, et ils ont la capacité de renforcer ou de remettre en cause les dynamiques de pouvoir existantes (Grumbach, 2022). La question de savoir qui définit l’équité dans les algorithmes revient en fin de compte à savoir qui détient le pouvoir dans la société, et si ce dernier est exercé de manière responsable et éthique.
Algorithmes : réhumaniser l’équité
Dans un monde technologique en constante évolution, notamment dans le domaine de l’IA et de la prise de décision algorithmique, l’équité se présente comme une préoccupation centrale. Face à l’omniprésence des algorithmes dans des domaines aussi cruciaux que la santé, la justice ou l’emploi, il devient urgent de passer d’une approche strictement technocratique à une perspective réellement centrée sur l’humain. Une telle transition n’est pas qu’une simple option morale : elle est indispensable pour s’assurer que les valeurs sociétales fondamentales, telles que la justice sociale et la protection des droits individuels (Rouvière, 2021), se reflètent dans les technologies développées. Toutefois, l’équité ne doit pas être perçue comme un principe figé ou universel. Ainsi, ce qui est jugé équitable dans un système éducatif donné peut être perçu comme injuste dans le secteur de la santé : l’équité peut signifier accorder des ressources supplémentaires aux élèves défavorisés afin de compenser les inégalités initiales alors que dans le secteur de la santé, une approche similaire sera perçue comme injuste si elle entraîne un accès différencié aux soins pour des patients ayant des besoins identiques. Cela souligne la nécessité d’une exploration nuancée de l’équité, prenant en compte les expériences vécues des personnes concernées par les décisions algorithmiques, afin d’éviter des généralisations hâtives et simplistes.
L’un des cas les plus récents de telles généralisations est l’arrestation de Guy Joao à l’aéroport de Glasgow en Écosse en octobre 2019, pris à tort pour Xavier Dupont de Ligonnès, célèbre fugitif recherché depuis le printemps 2011 pour le présumé assassinat de son épouse et de ses quatre enfants à Nantes[2]. L’erreur grossière, corrigée après 26 heures de garde à vue, repose sur des méthodes algorithmiques utilisant un nombre limité de points de comparaison faciale. Pour maximiser la vitesse d’identification, elles se concentrent en effet sur quelques traits distinctifs ‒ comme la distance entre les yeux, la forme du nez ou des pommettes ‒ plutôt que d’analyser l’ensemble du visage dans ses moindres détails. Cependant, cette approche parcimonieuse présente un risque accru d’erreur, notamment lorsqu’un individu présente des similitudes partielles avec une autre personne recherchée. Dans le cas de Guy Joao, les autorités écossaises ont comparé son visage à une photographie vieillie de Xavier Dupont de Ligonnès, mais les algorithmes n’ont pas correctement pris en compte les effets du vieillissement, les variations de lumière et des micro-expressions spécifiques. En utilisant un nombre restreint de points de comparaison, le système a ignoré de telles « subtilités » et généré instantanément une fausse correspondance (Politi, 2019).
Les algorithmes, qui influencent de manière significative les choix des individus, ne peuvent donc plus fonctionner « dans l’ombre ». Il est essentiel que les processus décisionnels, les données utilisées et les hypothèses formulées soient transparents pour le public. Lorsque les algorithmes opèrent comme des « boîtes noires », sans supervision démocratique, la confiance envers la technologie s’effrite. En favorisant une transparence totale, les concepteurs permettent aux citoyens de comprendre les mécanismes de prise de décision et de tenir les acteurs impliqués responsables de biais éventuels. Cette ouverture devient notamment indispensable dans des domaines sensibles comme la santé. Par exemple, des algorithmes de triage médical utilisés dans les hôpitaux peuvent prioriser certains patients selon des critères automatisés, une tentation que la pandémie de Covid-19 a mis en lumière en France à travers l’établissement d’un « score de fragilité » (voir l’Illustration n° 2). Si les critères de priorité ne sont pas clairement définis, des patients à vulnérabilités spécifiques, mais en parfaite forme, risquent d’être désavantagés. De même, dans les systèmes de diagnostic assisté par IA, le manque de transparence entraînera des décisions médicales fondées sur des données biaisées, amplifiant les inégalités dans l’accès aux soins (Nordling, 2019). La transparence permet de fait aux médecins, patients et régulateurs de vérifier que les systèmes algorithmiques respectent des principes d’équité et d’objectivité dans un cadre éthique robuste.
Illustration n° 2. Un « score de fragilité » pour trier les patients
Face à l’afflux de cas graves de patients atteints du Covid-19, comment les services de réanimation ont-ils fait le choix de celles et ceux à traiter en priorité ? Au printemps 2020, le ministère français de la Santé publie un document intitulé Priorisation de l’accès aux soins critiques dans un contexte de pandémie en vue d’aider les soignants. Il présente un arbre décisionnel pour assister les médecins non-réanimateurs dans l’établissement d’un pronostic et prioriser les malades. Le document s’appuie sur une donnée jugée objective : un « score de fragilité ». Son calcul prend en compte plusieurs critères et, en premier lieu, l’âge du patient. Celui-ci est déterminant dans la pandémie, la mortalité due au Covid-19 étant maximale chez les malades les plus âgés. Viennent ensuite d’autres critères, comme le nombre de pathologies dont souffre le patient et le nombre de traitements suivis, la mobilité, ou encore la perception de la santé par rapport aux personnes de même âge. Plus le « score de fragilité » est élevé, plus le patient est jugé fragile et donc moins à même de répondre à des techniques de réanimation lourdes. Le premier pas vers une « algorithmisation » généralisée du système français de santé ?
Source : d’après Les Échos, 20 mars 2020.
Au-delà de la transparence, il s’avère essentiel que la conception des systèmes algorithmiques intègre des principes que nous qualifierons de « participatifs ». L’équité ne doit pas être laissée uniquement aux data scientists ; il est impératif d’inclure les voix des communautés directement affectées par ces systèmes, un peu comme des consommateurs sont impliqués dans la création et le lancement de nouveaux produits (Chang & Taylor, 2016). En impliquant divers acteurs – des éthiciens, des sociologues, des juristes, des membres de diverses communautés, etc. – dans le processus de développement des algorithmes, il est possible de s’assurer qu’ils ne reposent pas uniquement sur des modèles abstraits, mais intègrent des valeurs éthiques concrètes et tiennent compte des impacts sociaux. Dans le cas de Parcoursup, le poids attribué aux notes lors du processus de répartition peut ainsi être contrebalancé par des informations qualitatives jugées pertinentes par des commissions d’enseignants telles qu’une implication dans des activités humanitaires, voire une lettre de motivation convaincante (Mizzi, 2025). Une telle approche participative ne garantit pas que les algorithmes tiennent compte des réalités vécues par les populations concernées, mais elle constitue pour le moins un pas vers des technologies plus équitables, notamment en renforçant l’inclusivité et en réduisant les biais systémiques qui émanent des processus de conception dominés par certains groupes. Car en tout état de cause, le décideur s’appuyant sur l’IA pour l’aider dans la prise de décision, comment peut-il assumer sa probable incompréhension de la fabrique de la décision, souligne fort justement Hizam (2024) ?
Enfin, afin de veiller à la mise en œuvre d’une véritable éthique des algorithmes, il est indispensable d’introduire des audits systématiques et des évaluations d’impact par des tierces parties. De la même manière que les projets de construction de grands équipements exigent désormais des évaluations d’impact environnemental, les systèmes algorithmiques doivent être soumis à une évaluation approfondie de leurs conséquences éthiques avant leur déploiement. Les audits doivent être réalisés en vue d’identifier de manière proactive les biais ou les risques sociaux associés puisqu’il est possible en dernier ressort d’aligner les décisions de l’algorithme sur une éthique humaine (Goglin, 2024). Parallèlement, il s’avère nécessaire de repenser les méthodes utilisées pour évaluer l’équité algorithmique car si les statistiques actuelles, comme l’élimination de faux positifs (par exemple, un test qui détecte une maladie chez une personne en bonne santé), offrent des informations utiles, elles ne capturent pas pleinement les dimensions complexes de l’équité. Une approche plus globale doit intégrer des critères liés aux injustices historiques associées à des stéréotypes et aux déséquilibres de pouvoir. En élargissant les critères d’évaluation, il sera alors possible de prendre en compte les divers aspects de l’équité afin d’aller vers des systèmes algorithmiques servant le bien commun et respectant la diversité des réalités sociales.
Conclusion
Le développement et l’utilisation des systèmes algorithmiques soulèvent une question éthique fondamentale : jusqu’à quel point devons-nous confier des décisions de nature morale à des machines ? La tentation d’automatiser divers choix sociétaux en déléguant une telle responsabilité aux algorithmes révèle des tensions paradoxales croissantes entre efficacité et humanisme. Les algorithmes, loin d’être des entités impartiales, ne sont que le reflet des choix humains, des biais et des valeurs des concepteurs, même ni l’humain n’échappe pas lui-même aux biais, comme le prix Nobel Kahneman (2011) l’a indiqué dans ses travaux. La prétendue objectivité des systèmes algorithmiques est une illusion car ils sont inévitablement influencés par les contextes singuliers de leur développement. Force est d’admettre que l’illusion de l’impartialité algorithmique empêche de reconnaître que les choix paraissant « neutres » sont le plus souvent façonnés par des préjugés implicites (voire explicites), dont nous avons souligné la forte présence dans le milieu du football, par exemple sur la taille des joueurs afin d’occuper la place singulière de gardien de but (Paché, 2024). Il est donc impératif de faire en sorte que les valeurs humanistes fondamentales, telles que le respect de la dignité et de l’équité, ne soient pas sacrifiées sur l’autel de l’efficacité algorithmique.
Pour aborder au mieux les défis éthiques des algorithmes, il est crucial que la société reprenne collectivement le contrôle des décisions. Cela commence par exiger une transparence totale dans le processus algorithmique, afin de mieux comprendre les principes guidant lesdites décisions. Mais la transparence seule ne suffit pas : il faut aussi et surtout s’assurer d’un contrôle humain actif, de manière que les algorithmes restent au service de l’Humanité, et non l’inverse. Reconnaissons qu’il s’agit là d’une vieille antienne depuis le fameux I, Robot d’Asimov (1950 [2018]) sur les trois lois de la robotique. Une telle démarche nécessite un changement culturel profond pour enfin admettre que l’équité ne peut se réduire à des formules mathématiques. Au contraire, elle renvoie à des considérations humaines complexes, qui tiennent compte de contextes sociaux, historiques et individuels. Or, en s’inspirant de la réplique du magnat véreux Noah Cross dans Chinatown (1974) de Roman Polanski, il faut admettre notre capacité sans cesse renouvelée à créer des systèmes qui perpétuent l’injustice sous de multiples formes. C’est dire que le chemin sera certainement long et tortueux vers un avenir où l’éthique et l’équité se placeront au cœur de l’IA.
[1] Le lecteur averti reconnaîtra dans ce titre un clin d’œil à l’ouvrage de Durand (2019) consacré notamment aux biais cognitifs.
[2] Tous mes remerciements à mon collègue et ami Marc Bidan qui, connaissant mon vif intérêt pour l’affaire Xavier Dupont de Ligonnès, m’a éclairé sur les fondements de la méprise relative à Guy Joao, aujourd’hui décédé.
Bibliographie
Asimov, I. (1950 [2018]). I, robot. New York: HarperCollins.
Beaudouin, V., & Maxwell, W. (2023). La prédiction du risque en justice pénale aux États-Unis : L’affaire ProPublica-COMPAS. Réseaux, n° 240, pp. 71‒109. https://doi.org/10.3917/res.240.0071
Brennan, T., & Dieterich, W. (2018). Correctional offender management profiles for alternative sanctions (COMPAS). In Singh, J., Kroner, D., Wormith, S., Desmarais, S., & Hamilton, Z. (Eds.), Handbook of recidivism risk/needs assessment tools (pp. 49‒75). Hoboken (NJ): Wiley-Blackwell.
Chang, W., & Taylor, S. (2016). The effectiveness of customer participation in new product development: A meta-analysis. Journal of Marketing, Vol. 80, n° 1, pp. 47‒64. https://doi.org/10.1509/jm.14.0057
Dupont, L., Fliche, O., & Yang, S. (2020). Gouvernance des algorithmes d’intelligence artificielle dans le secteur financier : Document de réflexion. Paris : ACPR / Banque de France.
Durand, T. (2019). Quand est-ce qu’on biaise ? Paris : HumenSciences.
Garcia, A.-C., Garcia, M.-G., & Rigobon, R. (2024). Algorithmic discrimination in the credit domain: What do we know about it? AI & Society: Knowledge, Culture & Communication, Vol. 39, n° 4, pp. 2059‒2098. https://doi.org/10.1007/s00146-023-01676-3
Gault, G., & Medioni, D. (2022). Les Français et la fatigue informationnelle : Mutations et tensions dans notre rapport à l’information. Paris : Fondation Jean-Jaurès Éditions.
Goglin, C. (2024). Réhabiliter la raison grâce à l’intelligence artificielle ? Management & Data Science, Vol. 8, n° 3, Article 37498. https://doi.org/10.36863/mds.a.37498/
Grumbach, S. (2022). L’empire des algorithmes : Une géopolitique du contrôle à l’ère de l’anthropocène. Paris : Armand Colin.
Hizam, M. (2024). Éclairage sur l’évolution de la fabrique de la décision à l’ère de l’IA. Management & Data Science, Vol. 8, n° 1, Article 28115. https://doi.org/10.36863/mds.a.28115
Kahneman, D. (2011). Thinking, fast and slow. New York: Farrar, Straus & Giroux.
Latour, B. (2006). Changer de société : Refaire de la sociologie. Paris : La Découverte.
Leffer, L. (2023). Humans absorb bias from AI‒and keep it after they stop using the algorithm. Scientific American, October 26. https://www.scientificamerican.com/article/humans-absorb-bias-from-ai-and-keep-it-after-they-stop-using-the-algorithm/
Mizzi, A. (2025). Inscriptions post-bac : Parcoursup, l’orientation par algorithmes ? The Conversation, 14 janvier. https://theconversation.com/inscriptions-post-bac-parcoursup-lorientation-par-algorithmes-246701
Nordling, L. (2019). A fairer way forward for AI in health care. Nature, Vol. 573, pp. s103–s105. https://10.1038/d41586-019-02872-2
Nowotny, H. (2021). In AI we trust: Power, illusion and control of predictive algorithms. Cambridge: Polity Press.
Paché, G. (2024). Droit au but avec l’IA : Une révolution à bas bruit pour le football professionnel. In Mamavi, O., & Zerbib, R. (Éds.), Défis et perspectives de l’IA en entreprise : Productivité, transformation, régulation (pp. 79‒91). Paris : MDS Éditions.
Politi, C. (2019). Affaire Xavier Dupont de Ligonnès : Comment en est-on arrivé à croire à une fausse piste ? 20 Minutes, 12 octobre. https://www.20minutes.fr/societe/2626459-20191012-affaire-xavier-dupont-ligonnes-comment-arrive-croire-fausse-piste
Rouvière, F. (2021). La justice prédictive : Peut-on réduire le droit en algorithmes ? Pouvoirs, n° 178, pp. 97‒107. https://revue-pouvoirs.fr/la-justice-predictive-peut-on/
Smith, A. (1759 [2014]). Théorie des sentiments moraux. Paris : Presses Universitaires de France.
Troussel, S., Éd. (2020). Baromètre des discriminations en Seine-Saint-Denis. Saint-Denis : Département de Seine-Saint-Denis.
Xavier, B. (2025). Biases within AI: Challenging the illusion of neutrality. AI & Society: Knowledge, Culture & Communication, à paraître. https://10.1007/s00146-024-01985-1