
Citation
L'auteur
Soukaina EL GHALDY
(soukainaelghaldy@yahoo.com) - Paris School of Business
Copyright
Déclaration d'intérêts
Financements
Aperçu
Contenu
Depuis des décennies, notre système financier a toujours été épaulé par un tiers de confiance, la banque, pour assurer la sécurité de nos transactions. Ce tiers de confiance a été remis en cause lors la crise de 2008. Nous avons été témoins d’un risque d’effondrement total du la machine financière. D’où la nécessité d’un système de paiement alternatif fiable, dénationalisé, libre de toute autorité et à faible coût. En 2008, le bitcoin a été créé pour répondre à ce besoin. En effet, les cryptomonnaies ne dépendent d’aucun intermédiaire. Les transactions de cryptomonnaies sont vérifiées à l’aide de la technologie « blockchain » qui sécurise les échanges. Depuis le lancement du bitcoin en 2009, aucun hacker n’a pu infiltrer sa blockchain démontrant un haut niveau de sécurité, mais aussi l’énorme potentiel technologique de son réseau. Toutefois, les deux monnaies (cryptomonnaie et fiat) acquièrent principalement leur valeur de l’acceptation et la confiance des parties prenantes. De toute évidence, le sentiment des investisseurs à propos du bitcoin a une valeur informationnelle importante pour expliquer les variations de son cours, ceci explique d’une autre part sa grande volatilité.
État de l’art
Les algorithmes de Machine Learning (ML) ont été largement utilisés dans la littérature prédictive des séries temporelles. Jaquart et al.(2020) ont découvert que les modèles « Deep Learning » tels que les réseaux neuronaux récurrents (RNN) et les classificateurs à renforcement de gradient (GBC) sont particulièrement bien adaptés pour prédire le comportement du marché du bitcoin à court terme. Et que pour ces modèles de prédiction, les inputs « techniques » sont les plus adaptées à la prédiction des prix du bitcoin. Ces inputs dits « techniques » sont : l’évolution des retours sur investissement du bitcoin dans le temps, les caractéristiques de sa blockchain (comme que le nombre de transactions BTC), et les sentiments de sa communauté (sentiment Twitter).
Chevallier et al.(2021) ont déployé 6 algorithmes de ML pour prédire les prix du bitcoin en utilisant les cours de plusieurs actifs financiers comme les cryptomonnaies, les actions, etc. Ils ont découvert que l’un des meilleurs modèles de prévision est le réseau neuronal AdaBoost en utilisant comme prédicteur le prix des cryptomonnaies alternatives. Ceci a renforcé la littérature concernant les réseaux neuronaux. Chen et al.(2021) ont également révélé en 2021 qu’en utilisant des « déterminants économiques et technologiques », le RNN LSTM pourrait atteindre de meilleures performances prédictives que l’ARIMA, le SVM et bien d’autres modèles. Les déterminants sous-entendus dans cette étude sont des prédicteurs basées sur les caractéristiques de la blockchain Bitcoin (comme le volume des transactions), le sentiment de la communauté bitcoin (volume de tweets et Google Trends) ainsi que plusieurs autres actifs financiers (comme le cours de l’or, l’euro ou l’indice SP500).
Dans la littérature, L’analyse sentimentale utilisant Twitter et Google Trends est un nouvel outil pour prévoir les prix du Bitcoin. L’analyse sentimentale, ou « Sentimental analysis » en anglais, fait référence à l’identification et à la classification des sentiments exprimés dans un texte en langage naturel. Philippas et al.(2019) soutiennent l’idée que les prix du bitcoin sont déterminés par le sentiment de la communauté bitcoin dans les réseaux sociaux, ils évoquent le concept d’appétit sentimental pour la demande d’informations. Twitter est particulièrement utile pour générer une grande quantité de données de sentiment pour ce type d’analyse. Wolk (2020) a utilisé 10 algorithmes différents pour déterminer la meilleure combinaison pour la prédiction du Bitcoin et a établi qu’il existe une corrélation entre les données de Twitter et la fluctuation des prix des cryptos. Il a constaté que les tweets avaient une forte corrélation négative avec le prix, comme si de mauvaises nouvelles provoquaient une augmentation de la post-fréquence et donc une baisse du prix du bitcoin. L’auteur a mis en évidence l’impact de la réaction de la communauté sur le marché spéculatif de la crypto-monnaie.
Méthode
Les données utilisées dans ce projet proviennent de la période qui commence le 6 septembre 2021 et se termine le 31 octobre 2021, soit un total de 8 semaines. Elles proviennent principalement de 2 sources : Binance.com et Twitter.com.
Afin d’extraire les données Binance, nous avons utilisé l’API Binance plus précisément la bibliothèque « python-binance ». Afin d’extraire les données de Twitter, nous avons utilisé la bibliothèque « Snscrape » qui est un service scraper pour réseaux sociaux. L’extraction a été mise en service via Docker en CLI sur un serveur externe (24h/24). Celle-ci a duré 6 jours pour 8 semaines de données. À noter que le taux d’extraction dépend des ressources de calcul allouées.
Après avoir nettoyé les données, nous avons utilisé l’analyse sentimentale avec la bibliothèque VADER sur les tweets que nous avons récupérés. Le lexicon VADER est un simple dictionnaire préétabli, nous pouvons alors y ajouter ou en supprimer des mots. Il existe quelques lignes directrices pour les meilleures pratiques de notation incluses dans l’article académique lié sur le référentiel GitHub de VADER. Ainsi, dans ce travail nous avons décidé d’ajouter un dictionnaire de données au lexicon. La raison de cette décision est le fait que la communauté twitter bitcoin utilise beaucoup d’émojis argotiques et spécifiques qui expriment des émotions non lues par VADER. Le score d’intensité émotionnelle ou de sentiment est mesuré sur une échelle de -4 à +4, où -4 est le plus négatif et +4 est le plus positif. Le point médian 0 représente un sentiment neutre. Notre principale préoccupation durant cette étape était de déterminer les scores des mots car nous n’avons pas d’échantillon d’évaluateurs humains objectifs de la communauté bitcoin et un score arbitraire pourrait biaiser nos résultats. De ce fait, les scores ont été définis en utilisant une stratégie de notation médiane. Celle-ci peut être illustrée de la manière suivante :
- -4 : extrêmement négatif
- -2 : négatif
- 0 : neutre
- 2 : positif
- 4 : extrêmement positif
Cette stratégie nous aidera à influencer les notations en minimisant le biais, qui pourra faire l’objet d’un autre travail. Le nombre total d’expressions argotiques et d’emojis utilisés dans cet ouvrage est de 59. Le dictionnaire de données pour les expressions et les scores attribués se trouve dans la Figure 5. Les emojis ont été traduits via le lexicon d’emoji Vader disponible dans le référentiel GitHub.
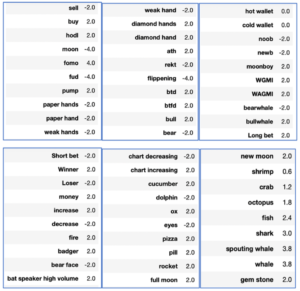
Figure 5: The slangs and emojis data dictionary
L’étape suivante va être de sélectionner les prédicteurs (inputs) de nos modèles grâce à l’exploration des données (EDA). En utilisant une matrice de corrélation par paires, nous avons identifié les prédicteurs que nous allons employer pour nos modèles (Figure 6).
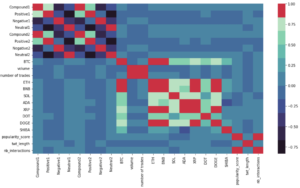
Figure 6: The Correlation heatmap
Celle-ci utilise le coefficient de corrélation de Pearson. C’est un coefficient varie de +1 à 1, avec le 0 indiquant qu’il n’y a pas de corrélation entre les deux variables. On a utilisé les prédicteurs qui obtiennent un score supérieur à 0,3 ou inférieur à -0,3. Nous retrouvons pour le modèle 2 :
- BNB (0.939467),
- ETH (0.923908),
- XRP (0.827807),
- DOGE (0.792926),
- SOL (0.637263),
- DOT (0.545468),
- ADA (0.530686),
- SHIBA (0.469606).
En plus des prédicteurs du modèle 2, le modèle 1 aura d’autres inputs qui ont un score de corrélation supérieur à 0,02 ou inférieur à -0,02. Ces prédicteurs sont :
- Le nombre de transactions BTC (0,044098),
- Le score d’intensité des sentiments neutres avant le dictionnaire (0,042435),
- Le score d’intensité des sentiments neutres après le dictionnaire (0,032852),
- Le score d’intensité des sentiments positifs avant le dictionnaire (-0,020107),
- Le score d’intensité des sentiments négatifs apres le dictionnaire (-0,041778),
- Le score d’intensité des sentiments négatifs avant le dictionnaire (-0,042173).
Ensuite vient l’étape de prétraitement des données (« data preprocessing ») qui consiste à transformer les inputs bruts en structure de données (« data structure ») convenable pour notre modèle ML. Après avoir défini et ajusté (« define and fit ») notre modèle, nous avons conçu l’architecture du réseau neuronal.
L’architecture du modèle 1 est :
- Une couche LSTM à 6 cellules dans la première couche visible.
- Une couche de régularisation avec un dropout de 0,2.
- Une couche dense avec 1 cellule comme couche de sortie pour prédire le prix du bitcoin.
- L’input shape sera 1 pas de temps avec 15 prédicteurs.
- L’erreur absolue moyenne (MAE) comme métrique et la version efficiente d’Adam pour la descente de gradient stochastique comme un optimiseur.
- Le modèle sera adapté pour 100 epochs d’entraînement avec un batch size de 12 000.
L’architecture du modèle 2 est :
- Une couche LSTM à 6 cellules dans la première couche visible.
- Une couche de régularisation avec un dropout de 0,2.
- Une couche dense avec 1 cellule comme couche de sortie pour prédire le prix du bitcoin.
- L’input shape sera 1 pas de temps avec 10 prédicteurs.
- L’erreur absolue moyenne (MAE) comme métrique et la version efficiente d’Adam pour la descente de gradient stochastique comme un optimiseur.
- Le modèle sera adapté pour 87 epochs d’entraînement avec un batch size de 12 000.
Enfin, nous avons résumer toutes les étapes du travail sur le modèle 1 dans la figure 7 et le modèle 2 dans la figure 8.
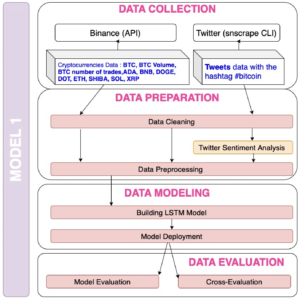
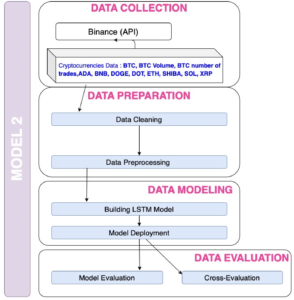
Figure 7: The model 1 Figure 8: The model 2
Résultats
Inputs
Les modèles basés sur les réseaux de neurones récurrents (RNN), notamment le modèle LSTM pour « Long Short-Term Memory », ont prouvé durant les dernières années qu’ils sont particulièrement adaptés à la prédiction de séries temporelles. Ces modèles représentent les méthodes prédominantes pour prédire la dynamique des marchés financiers traditionnels. Durant cette étude, nous avons construit un modèle LSTM hybride qui utilise les résultats catégoriques d’une analyse sentimentale de la communauté bitcoin sur Twitter ainsi que les prix des cryptomonnaies alternatives comme inputs pour prédire le cours du bitcoin, que nous appellerons le modèle 1. En vue de mesurer l’intérêt d’utiliser du composant sentimental comme input, nous avons également construit un modèle LSTM classique qui utilise uniquement les prix des cryptomonnaies alternatives comme inputs, que nous appellerons le modèle 2.
Pour tester notre modèle, nous avons utilisé un échantillon de l’ensemble de données (figure 1) qui comprend des observations entre le 20/09/2021 et le 30/10/2021. Les résultats normalisés du modèle 1 sont affichés sur le graphique 1 et ceux du modèle 2 sont affichés sur le graphique 2. Le cours représente les prix d’échange du bitcoin en tether (BTC/USDT).
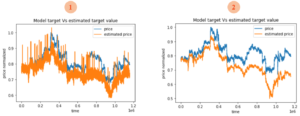
Figure 1: The Prediction values vs actual values
Analyse et évaluation des Outputs
Sur le graphique 1, le modèle a réussi à capturer la tendance du cours du bitcoin avec un taux d’erreur maximal de 10%. Malgré la forte volatilité du cours du bitcoin, la courbe du modèle 1 gagne en précision par rapport à la courbe du modèle 2, qui a un taux d’erreur maximal de 17%. Cependant, le modèle 1 comporte quelques valeurs aberrantes. Ce qui est probablement dû à l’intégration du composant sentimental. Les filtres de Hampel seraient une excellente solution pour gérer ces « outliers » tout en lissant la courbe. Malheureusement, nous n’avions pas eu la possibilité d’intégrer cette partie lors cette étude.
Lorsque nous transposons les 3 courbes nous pouvons observer à l’œil nu des relations assez subtiles (Figures 2 et 3). Nous remarquons que les données du modèle 1 sont très bruitées. L’Écart interquartile (IQR) est un bon moyen de mesurer ces fluctuations. C’est la distance entre le premier quantile (25%) et le troisième (75%).
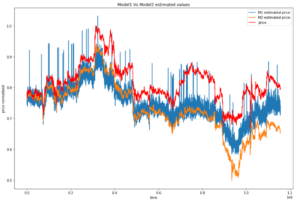
Figure 2: The models’ values vs actual values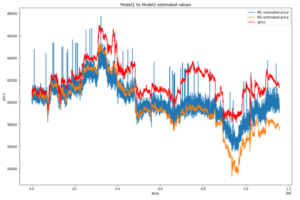
Figure 3: The models’ values vs real values
L’écart interquartile pour les prédictions du modèle 1 est autour de 0.068, qui est quasiment égale à l’IQR des valeurs réelles de la même période (courbe en bleu) qui est de 0.069, contre un IQR de 0.107 pour le modèle 2. Ceci démontre bien la forte corrélation entre les prédictions du modèle 1 et les valeurs réelles. Cependant, l’écart-type et la moyenne du modèle 1 sont inférieurs à ceux des valeurs réelles, ce qui reflète l’écart négatif entre les deux courbes. Tandis que l’écart-type du deuxième modèle est plus élevé que ceux des deux autres courbes, ceci explique la forte décroissance de la courbe en orange vers la fin de la période.
La prédiction de séries temporelles est un problème de régression. Il est donc logique d’utiliser des métriques spécifiques aux erreurs de régression. Nous avons calculé les MAE, MSE et RMSE des 2 modèles que nous avons notés dans la grille de performances de la figure 4.
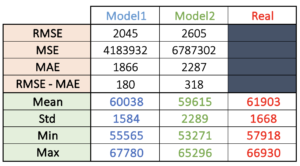
Nous pouvons nous attendre à une erreur moyenne de 1866 USDT pour le modèle 1 et de 2287 USDT pour le modèle 2. Ou plus clairement, un risque de perdre ou de gagner respectivement 1865 USDT ou 2287 USDT par unité de bitcoin achetée pendant cette période, si nous nous fions aux estimations des modèles. La valeur moyenne réelle du bitcoin pendant cette période est de 61903 USDT. Ainsi, le modèle 1 a un risque moyen de perte d’environ 3,01 % et le modèle 2 de 3,69 %. La variance des erreurs est plus grande sur le modèle 2, cela implique que des erreurs plus importantes sont plus susceptibles de se produire. Le type d’erreurs qui pourraient avoir lieu dans le modèle 2 est illustré par exemple dans les derniers jours de l’échantillon où sa valeur historique minimale a atteint 53 271 USDT/BTC. L’erreur sur ce point est d’environ 4647 USDT/BTC ce qui est significatif car elle représente 7,5% de la moyenne.
Conclusion
Ce travail apporte 4 contributions :
- La construction d’un nouveau type de modèles hybride utilisant les scores des données catégoriques de l’analyse sentimental.
- Le renforcement de la littérature en utilisant le modèle de deep Learning LSTM.
- Une comparaison entre les modèles proposés et des modèles de la littérature.
- L’introduction d’un nouveau dictionnaire de données pour les expressions argotique du bitcoin.
Enfin, et dans le but d’aider à améliorer les modèles proposés, nous avons essayé de réfléchir à des idées pour améliorer leurs performances tout au long de la modélisation. Pour les personnes désireuses de reprendre ce travail et de l’améliorer, plusieurs options s’offrent à vous. Nous avons énuméré ci-dessous quelques idées qu’ils doivent absolument garder à l’esprit :
- Les corrélations des prédicteurs bitcoin peuvent changer au fil du temps en raison de différents types d’événements (migration de la communauté bitcoin de Twitter à un autre réseau social).
- L’analyse des sentiments peut bénéficier d’un meilleur coefficient réseau qui prendra en compte le pouvoir d’influence des différents utilisateurs sur le réseau.
- Trouver une meilleure méthode de noter les mots du dictionnaire de données en minimisant le biais peut être un axe d’étude très intéressant.
- La gestion des valeurs aberrantes dans le modèle 1, à l’aide des filtres de Hampel par exemple, diminuerait énormément les taux d’erreur.
Bibliographie
- Wei Chen, Huilin Xu, Lifen Jia and Ying Gao, WC,HX,LJ and YG, 2021.Machine learning model for Bitcoin exchange rate prediction using economicand technology determinants. International Journal of Forecasting, vol. 37(3),1300-1301. https://www.sciencedirect.com/science/article/abs/pii/S0169207020300431
- Julien Chevallier, Dominique Guegan and St´ephane Goutte,JC,DG and SG, 2021. Is It Possible to Forecast the Price of Bitcoin? Advances of MachineLearning Forecasting within the FinTech Revolution. vol. 3(2), 377-420. https://www.researchgate.net/publication/351994358_Is_It_Possible_to_Forecast_the_Price_of_Bitcoin
- Patrick Jaquart, David Dann, Christof Weinhardt, PJ, DD and CW,2020. Short-term bitcoin market prediction via machine learning.The Journalof Finance and Data Science. vol. 7, 45-66. https://www.sciencedirect.com/science/article/pii/S2405918821000027
- Dionisis Philippas, Hatem Rjiba, Khaled Guesmi and Stephane Goutte,2019.DP, HR,KG and SG. Media attention and Bitcoin prices.Finance Research Let-ters. vol. 30, 37-43. https://www.sciencedirect.com/science/article/abs/pii/S1544612319300558
- Krzysztof Wolk, WK, 2020.Advanced social media sentiment analysis forshort-term cryptocurrency price prediction.Expert Systems. vol. 37, e12493. https://onlinelibrary.wiley.com/doi/abs/10.1111/exsy.12493
Crédits
Cet article est issu de mon mémoire de fin d’étude pour l’obtention du MSc en Data Management de Paris School of Business et de l’EFFREI. Je remercie Olivier MAMAVI, mon tuteur académique.