
Citation
Les auteurs
Florine COMLAN
(florine.comlan@gmail.com) - Paris School Of BusinessJordy_hsn
(jordy_hsn@yahoo.com) - Paris School of BusinessWuraola
(ramyahount@gmail.com) - PSB ParisKabirou
(kabkabirou@gmail.com) - Paris School of Business
Copyright
Déclaration d'intérêts
Financements
Aperçu
Contenu
INTRODUCTION
Aujourd’hui, les réseaux sociaux représentent, pour les entreprises, une arme redoutable qui leur permet d’atteindre leur cible lors de campagnes de communication. Pouvoir identifier le bon interlocuteur pour faire passer un message est primordial. Avez-vous déjà cherché à identifier à quel compte twitter confier une campagne de communication ou quel compte suivre pour être sûr de ne rien rater ?
Nous proposons, dans cet article, une démarche permettant d’analyser une communauté, c’est-à-dire des ensembles de comptes twitter échangeant les uns avec les autres sur un sujet.
CRITERES UTILISES POUR IDENTIFIER LES LEADERS D’OPINION
Afin de réaliser une analyse pertinente, nous avons défini les critères de centralité qui peuvent permettre d’identifier un leader d’opinion sur un réseau.
- Eigen centrality (centralité de vecteur propre) : en théorie des graphes, il permet de mesurer l’influence d’un nœud (tweetos) sur un réseau en fonction du nombre de liens qu’il possède avec d’autres nœuds du réseau. Il prend également en compte la qualité de la connexion d’un nœud et le nombre de lien de ses connexions à travers tout le réseau. Cet indicateur fonctionne de sorte à identifier les nœuds ayant une influence sur l’ensemble du réseau.
- Authority : permet de mesurer la pertinence de l’information contenue dans un compte associé à un acteur d’un réseau.
- PageRank : c’est une variante d’Eigen Centrality. La différence est que le PageRank prend également en compte le poids des liens. Il permet de découvrir les nœuds dont l’influence s’étend au-delà de leurs connexions directes dans un réseau plus large. Cet indicateur peut être utile pour comprendre l’autorité du nœud dans le réseau.
- Weighted indegree : c’est un indicateur qui fournit un classement des acteurs du réseaux avec le plus de mentions. Ce qui peut permettre d’observer le niveau d’écoute et de reconnaissance des acteurs du réseau.
- Weighted degree : mesure l’engagement d’un acteur dans un réseau indépendamment du nombre de voisins auxquels il est connecté .
- Betweeness centrality : mesure le nombre de fois où un nœud se trouve sur le chemin le plus court entre les autres nœuds. Il permet ainsi de faire voir quels nœuds sont des « ponts » entre les autres nœuds d’un réseau. Il est très utile pour analyser la dynamique de la communication dans un réseau.
- Weighted outdegree : classe les acteurs en fonction du nombre de tweets où ils ont mentionné d’autres comptes.
PRESENTATION DU JEU DE DONNEES
Une fois les objectifs clairement définis, la première étape a consisté à collecter les données qui permettront de les atteindre.
Nous avons choisi de travailler avec les données fournies dans le data challenge afin de bénéficier d’informations sur une période plus longue. En effet, une collecte a été faite avec python via l’API de Twitter. Malheureusement, cette API ne permet d’obtenir que 7 jours de données sans abonnement. Nous avons donc jugé qu’il était plus intéressant de se servir du jeu de données fourni qui offrait un champ d’observation sur environ 3 semaines (du 28 mars au 11 avril 2021).
Ces données une fois transformées présentaient les caractéristiques suivantes :
- la date du tweet,
- le nom de la source (tweeter),
- le nom de la destination s’il y en a (retweeter),
- le contenu du tweet,
- le nombre d’abonnés du tweeter, sa localisation, son nombre d’abonnement, son nombre de tweets, la description de son profil et la relation entre la source et la destination.
Notre jeu de données est composé au total de 7767 observations qui correspondent au nombre de liens (tweet et retweet) et de 4718 nœuds (tweetos). Les tweets sont majoritairement localisés en France plus précisément en région parisienne comme le montre le graphique ci-dessous.
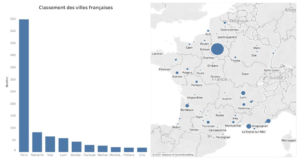
Fig 1 : Cartographie des sources de tweets en France
METHODOLOGIE
Création du jeu de données final
Trois fichiers Excel correspondant aux différentes semaines d’extraction ont été mis à notre disposition. La première étape de notre démarche fut l’agrégation de ces données afin d’obtenir un fichier unique sur lequel effectuer nos analyses. S’en est suivi le traitement du contenu de notre fichier notamment en nous servant des techniques de nettoyage et de dédoublonnage de données. Une fois terminé nous avons procédé à la fusion des différentes feuilles dudit fichier Excel grâce à l’outil Tableau ; ceci afin d’obtenir une feuille unique qui contient à la fois les nœuds et les liens de notre réseau.
Cartographie grâce à l’outil Gephi
Ensuite, nous avons utilisé le logiciel Gephi pour une exploration complète de la structure du réseau. En y appliquant les différents critères d’analyse énumérés plus haut, nous avons généré différentes cartographies de notre réseau. Le facteur de spatialisation utilisé pour le déploiement est celui de Yifan Hu.
Par la suite, en nous basant sur les informations temporelles de notre jeu de données, nous avons visualisé l’évolution des interactions entre les différents nœuds de notre réseau sur les trois semaines considérées.
A la fin de l’exploration, l’outil Gephi nous permet d’obtenir des statistiques par rapport aux différents critères d’observation ; nous nous en sommes servis pour la suite de notre analyse.
Classement des critères d’influences, scoring puis détection des nœuds influents du réseau
En se servant des statistiques générées par Gephi, nous avons créé une nouvelle liste contenant les 20 premiers nœuds les plus importants par critère d’analyse.
Afin de déterminer un classement unique qui prend en compte tous les critères d’influence à la fois, nous les avons rangés par ordre d’importance et leur avons affecté une pondération (Fig. 3). Cette pondération a été assignée à notre liste regroupant les nœuds selon leurs rangs pour que nous obtenions un premier classement d’influenceurs. Une dernière vérification est faite pour s’assurer de la justesse et de la pertinence du classement grâce à un traitement du contenu des pages associés.
Analyse du contenu des tweets et création d’un Wordcloud
A partir du contenu des tweets et des hashtags présents, nous avons fait une analyse textuelle en python afin de déterminer les mots les plus fréquents. Lors de cette analyse, ont été retenus uniquement les mots en français et en anglais. Certains tweets étaient en chinois et en espagnol mais nous avons choisi de ne pas les garder. S’en est suivi la représentation visuelle (Fig. 7). Les mots principaux qu’on peut y lire correspondent bien au sujet d’étude.
RESULTATS
Les cartographies des acteurs les plus influents en fonction des différents critères d’analyse et leur regroupement en communauté
Ce regroupement a été fait en se basant sur la classe de modularité avec une spatialisation dont la répartition selon les clusters est renseignée sur la figure suivante :
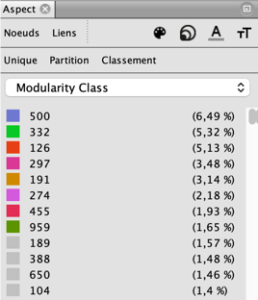
Fig 2 : Répartition des clusters par classe de modularité
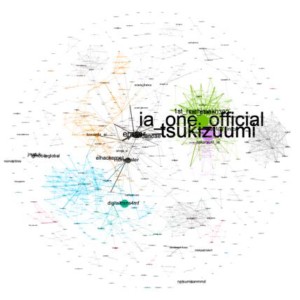 |
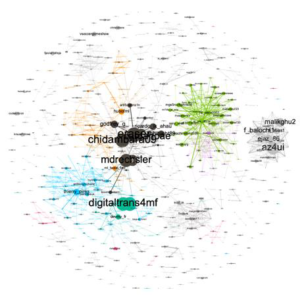 |
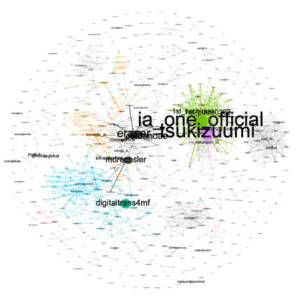 |
| Degré pondéré entrant | Degré pondéré sortant | Degré pondéré |
 |
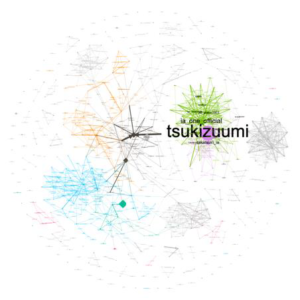 |
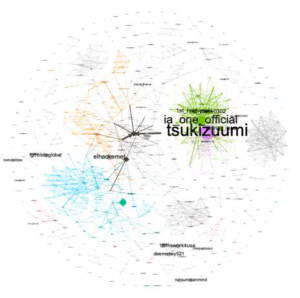 |
| Eigencentrality | Authority | Pagerank |
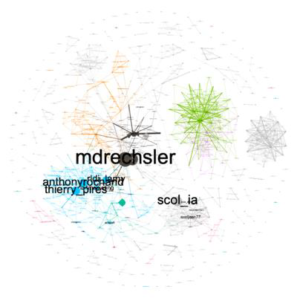 |
||
| Betweeness centrality |
La dynamique du réseau sur 3 semaines
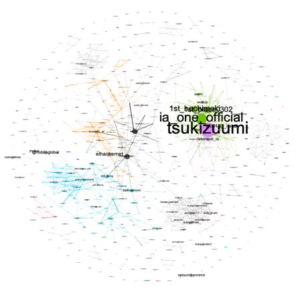 |
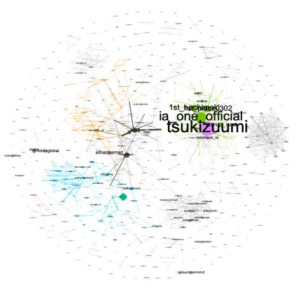 |
 |
| Semaine 1 | Semaine 2 | Semaine 3 |
L’interaction entre les membres des réseaux prépondérants reste plus ou moins stable tout au long des trois semaines ce qui justifie la force de leurs relations.
La pondération appliquée aux critères d’analyses suivant leur importance
![]()
Fig 3 : Tableau de pondération
Le top 15 des influenceurs après application de la pondération
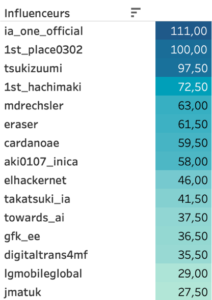
Fig 4 : Classement intermédiaire des influenceurs pour l’hashtag #IA
Après la phase d’analyse des profils des influenceurs de ce classement, nous avons remarqué que certains, bien que contenant des hashtags cible de notre recherche, ne correspondaient pas du tout à des profils du domaine spécifié. L’exemple type est le premier du classement actuel Ia_one_officiel qui n’est en réalité que le compte officiel d’un vocaloïd (logiciel de synthèse vocale développé par Yamaha). Il était donc nécessaire de revoir le classement tout en excluant ces profils dont les contenus ne sont pas pertinents pour notre étude.
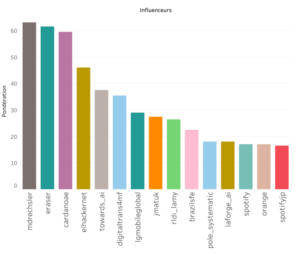
Fig 5 : Top 15 des influenceurs liés au #IA
Suite à nos résultats, nous avons pu dégager le podium et le top 15 des leaders d’opinion sur l’hashtag #IA pour la période considérée.
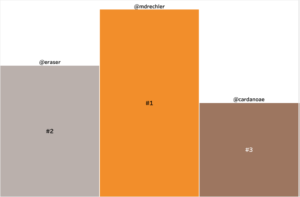
Fig 6 : Podium final des leaders d’opinion
Notre leader d’opinion identifié est @mdrechsler. Michèle Drechsler (son vrai nom) est titulaire d’un doctorat en sciences de l’information et de la communication. Son parcours professionnel est parsemé de nombreuses missions d’expertise, notamment celles menées au sein du Ministère de l’Education Nationale. C’est cela qui justifie son engagement et son leadership sur les sujets de l’IA.
Les critères d’influences appliqués aux 15 tweetos les plus suivis en termes de connexion

Fig 7: Tableau récapitulatif
La visualisation du contenu des tweets

Fig 8 : Word cloud basé sur les mots contenus dans les tweets
CONCLUSION
Limites de l’étude
Même si nous avons utilisé des critères pertinents pour identifier de l’influenceur sur #IA, notre étude comporte certaines limites qui sont à prendre à compte pour une analyse plus poussée.
- Données non quantitatives: Une étude sur une période plus large serait plus intéressante car elle nous permettra de déterminer si les leaders d’opinion identifiés le sont sur la durée ou s’il s’agit d’un effet de mode.
- Hashtag non exclusif: Même si bon nombre des tweets présents dans notre jeu de données est lié à l’IA, nous avons néanmoins rencontré des incohérences sur le contenu de certains qui faisait référence à toute une autre thématique d’où la nécessité d’analyser le contenu de chaque tweet afin de s’assurer de leur pertinence.
- Élargissement du champ de recherche: Nous pensons qu’il serait préférable de considérer d’autres hashtag supplémentaires liés à l’IA car même si #IA est assez représentatif, il n’englobe pas forcément tous les tweets liés à ce domaine donc certaines informations importantes pourraient nous passer sous le nez. Exemple d’hashtag à intégrer : #robot, #DataScience, #intelligenceartificielle, #data.
Intérêt de l’étude
Cette analyse a un intérêt pour les entreprises souhaitant atteindre efficacement leur cible. Elle leur permettra :
- d’identifier les acteurs clés ayant une influence sur une thématique donnée en permettant :
- d’avoir plus de visibilité sur les réseaux sociaux
- de maximiser leurs chances d’atteindre leurs objectifs de campagnes de communication.
- de cibler le bon public
- de suivre les tendances grâce aux interactions de la communauté du leader d’opinion qui peuvent être divergentes.
Préconisations
Afin de devenir un leader d’opinion sur Twitter, il faudrait dans un premier temps construire un réseau de qualité qui ne repose pas seulement sur la quantité de nos connexions, mais aussi sur l’influence de ces derniers dans le réseau. Il faudrait également créer un contenu assez riche et pertinent afin d’avoir une interaction fréquente non seulement avec nos relations mais également avec d’autres membres. La capacité d’interagir avec plusieurs groupes est aussi un atout très important pour un utilisateur en quête d’influence.
En somme, l’analyse de réseaux sociaux est indispensable dans ce monde connecté. Une bonne utilisation des techniques d’analyse de réseaux sociaux améliore l’efficacité des relations entreprises-cible/clients. Hormis le coté Marketing, cette analyse leur est également bénéfique pour faire passer leurs messages au bon public.