
Citation
L'auteur
Simon CHIGNARD
(simon.chignard@data.gouv.fr) - ETALAB
Copyright
Déclaration d'intérêts
Financements
Aperçu
Contenu
Été 2017. Le journal Les Echos révèle que la SNCF, la RATP, Transdev et Blablacar ont signé un accord pour développer un « entrepôt commun de données ». Le projet était à l’époque présentée comme une réponse à l’hégémonie des GAFA, et en premier lieu de Google. Quelques mois plus tard, l’initiative tarde toujours à se concrétiser.
Le secteur de la mobilité est pourtant le terrain idéal pour expérimenter le partage de la donnée. Nombre des acteurs de cette industrie interviennent à la fois sur le champ du service public et dans le domaine concurrentiel. Ils sont directement concernés par l’obligation d’ouverture par défaut pour la partie de leurs activités qui relèvent d’une mission de service public. Ils interviennent parfois dans des domaines directement soumis à la concurrence et exportent leur savoir-faire sur les marchés étrangers. C’est aussi dans le domaine de la mobilité que la concurrence d’acteurs « pure-players » s’est fait ressentir le plus rapidement. Uber ou Citymapper n’ont pas eu besoin de posséder des actifs matériels pour proposer des services de mobilité. Leur maîtrise des données leur donne un avantage compétitif certain. De plus, l’existence de standards (du type GTFS) permet de lever certains freins techniques à la circulation et la réutilisation des données de mobilité.
Pourquoi est-ce si difficile de partager des données des entreprises ?
Une étude[1] commanditée par la Commission Européenne révèle qu’un peu moins de 40% des entreprises interrogées sont engagées dans des démarches de partage de données avec d’autres entreprises (B2B). La possibilité de développer de nouveaux produits ou services est la première motivation évoquée (74% des répondants), devant la possibilité d’établir des partenariats avec de nouveaux acteurs (49%) et la génération de revenus supplémentaires par la monétisation des données (40%). A l’inverse, les principaux freins identifiés sont les enjeux de privacy (49%), la crainte d’une utilisation des données par la concurrence (33%) et l’absence d’une demande pour les données de l’entreprise (33%).
Il nous semble que l’une des difficultés majeures tient à l’appréciation, par une majorité d’entreprises, de la manière dont on peut créer de la valeur économique à partir des données. Une donnée qui ne circule pas ne génère guère de valeur d’usage. La donnée ne présente pas non plus de valeur de thésaurisation, elle ne se bonifie pas avec le temps. De même, le croisement entre plusieurs sources de données va générer une valeur supplémentaire.
L’une des grandes caractéristiques de l’économie des données est que la valeur se constate a posteriori, elle ne se décrète pas. C’est bien une fois que les données auront été croisées, analysées, qu’elles auront été utilisées pour décrire, expliquer, prédire ou prescrire que l’on pourra constater la valeur économique produite, tant en terme de gains d’opportunité que d’innovation[2].
Dès lors, la plupart des entreprises sont confrontées à ce qui ressemble fort à la quadrature du cercle: pour connaître la valeur de mes données il faudrait que j’accepte de les faire circuler pour en permettre le croisement avec des sources tierces auxquelles je n’ai pas accès. Mais accepter de partager aujourd’hui sans connaître les règles de répartition de cette potentielle création de valeur c’est compliqué. Interrogé il y a quelques années à propos de la diffusion en open data (c’est à dire librement et gratuitement) de certaines données de la SNCF, un cadre de l’entreprise de transport répondait: “tant que personne ne crée de la valeur avec, je n’ai aucun souci à partager ces données” !
Les enjeux de concurrence sont l’autre obstacle majeur au partage des données du secteur privé. Les relations entre les données et la concurrence sont multiples.
D’une part, les données (et le numérique au sens large) génèrent des économies d’échelle qui donnent un avantage compétitif certains aux acteurs dominants d’un marché – à l’image de l’impressionnante part de marché de Google en France dans le domaine des moteurs de recherche ou plus généralement des dynamiques de marché qui caractérisent les GAFA.
D’autre part, la maîtrise des données permet à des nouveaux entrants de concurrencer durement les acteurs établis, y compris sur des marchés historiques. Le secteur de la mobilité est particulièrement concerné par cette “couche additionnelle” de concurrence. Citymapper, qui propose une application de calcul d’itinéraires multimodaux ne se contente plus d’offrir un service d’information. La société londonienne a annoncé la mise en place de son propre service de transport (des mini-bus) sur les zones où l’offre de transport public est jugée défaillante. C’est la maîtrise des données (tant sur la demande que sur l’offre) qui permet à Citymapper de conquérir ainsi peu à peu l’ensemble de la chaîne de valeur du transport. En France, Blablacar a annoncé à l’occasion des grèves de l’opérateur ferroviaire la mise en place de liaisons par bus sur les destinations les plus demandées.
Bref, dans un monde de données abondantes, tout le monde est susceptible de devenir votre concurrent s’il ne l’est pas déjà aujourd’hui.
Comment créer les conditions du partage?
Les obstacles identifiés, tant en matière de perception des modalités de création de valeur que de risques concurrentiels ne sont pas insurmontables. Pour créer les conditions du partage, il faut tout d’abord accepter l’idée que les modalités de ce partage peuvent être multiples. Il existe un continuum de solutions qui vont du partage de quelques données entre acteurs liés par des conditions contractuelles fortes et des approches totalement ouvertes plus proche de la philosophie open data. Nous avons identifié quatre initiatives qui visent à faciliter le partage des données entre acteurs. Chacune d’entre elles apporte un élément de réponse aux difficultés actuelles.
Nous avons classé ces initiatives sont classées selon deux axes.
- Le périmètre du partage de données (filière vs. écosystème): dans le premier cas le partage des données ne concerne que les acteurs d’une filière industrielle (par exemple l’agriculture, la mobilité ou l’aéronautique). Dans le second cas les acteurs qui partagent leurs données se placent dans une optique plus large d’écosystèmes, qui ne sont pas donc pas réduits aux seuls acteurs établis d’un secteur d’activité.
- La structuration du marché (avec / sans acteur dominant): on distingue ainsi les situations où les initiatives relèvent principalement des décisions d’un seul acteur (le plus souvent l’acteur puissant) de celles qui émergent d’une coalition d’acteurs.
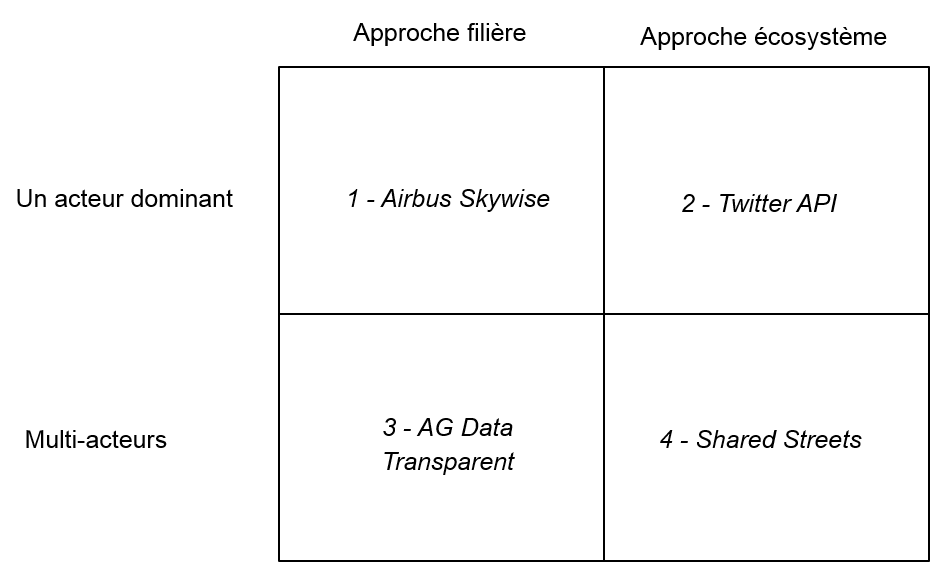
1. Airbus Skywise
la plateforme lancée en 2017 par l’avionneur européen et co-développée avec Palantir se concentre sur le partage de données sur le fonctionnement de l’avion avec les compagnies aériennes. Les données concernées sont très nombreuses (un appareil de type A 350 embarque plus de 250 000 capteurs) et proviennent de l’ensemble des composants de l’avion. La plateforme ne propose pas seulement des données, mais aussi des analyses prédictives, notamment en terme de maintenance et d’entretien des appareils. Ce modèle, centré sur une filière autour d’un acteur dominant, rappelle celui de l’échange de données informatisées (EDI) très présent dans le domaine industriel (automobile ou aéronautique) pour l’approvisionnement de la chaîne de production. La plateforme Skywise met en relation la filière amont (les fabricants des composants) et l’aval (les compagnies aériennes et les sociétés de maintenance) autour des données d’usage et non plus de production.
2. Twitter API
Facebook, Google ou Twitter doivent une partie de leur succès à leur politique d’API. Une API permet de définir les conditions d’accès aux données tant d’un point de vue technique (standard), juridique (conditions générales d’utilisation) qu’économique (tarification à l’usage). Ce modèle de partage s’inscrit clairement dans une logique écosystémique et non dans une approche de filière. Les API ont un avantage important du point de vue du producteur de la donnée: elles sont modulables et réversibles dans le temps. C’est à dire qu’il est possible de faire évoluer, de manière unilatérale, les conditions d’accès aux données. Dans un tel modèle, la prise de risque vis-à-vis des concurrents potentiels est limité, puisqu’il est possible à tout moment de limiter, voire de rendre impossible, l’accès aux données.
3. AG Data Transparent
L’agriculture est un secteur fortement impacté par l’abondance de données. Les grandes exploitations agricoles disposent aujourd’hui d’outils d’aide à la décision, qui s’appuient notamment sur la collecte de données localisées. Les équipements agricoles sont maintenant connectés et produisent de très nombreuses données non seulement sur le fonctionnement de l’équipement lui-même (pour en faciliter sa maintenance) mais aussi, de manière incidente, sur le volume et la qualité des récoltes. L’American Farm Bureau, qui représente les intérêts des exploitants agricoles, s’est émue très tôt de la capacité des grands équipementiers (dont John Deere) à utiliser ces données pour spéculer sur les marchés des céréales, allant ainsi à l’encontre de l’intérêt des utilisateurs de ses équipements. L’initiative AG Data Transparent vise à certifier les équipementiers sur le respect des principes définis dans la charte “Privacy and security principles for farm data”. Ces principes prévoient notamment la portabilité des données entre fabricants d’équipements, l’interdiction d’usage des données à des fins contraires à l’intérêt des exploitants agricoles, un contrôle accru sur la revente de données non anonymisées à des tiers. AG Data Transparent se distingue des autres initiatives (Skywise, Twitter API) dans la mesure où il ne s’agit pas ici d’une plateforme de partage de données, mais plutôt d’un outil pour créer les conditions de la confiance entre les acteurs d’une filière.
4. Shared Streets
L’initiative lancée en 2018 par l’association des responsables des transports des grandes métropoles nord-américaines (NACTO) et l’Open Transport Partnership vise à développer à la fois un standard d’identification et de nommage des rues et à concevoir une plateforme d’échanges de données entre les acteurs publics et privés. Le constat de départ est le suivant: l’essor des nouvelles mobilités représente un défi pour les métropoles qui doivent gérer l’espace public et en particulier les rues. Pour permettre un meilleur usage de cet espace il faudrait pouvoir partager facilement des données issues de sources publiques ou privées (par exemple les données sur les parkings, les données de trafic routier, les données des trajets Uber). Ce partage nécessite un identifiant partagé pour identifier de manière unique les rues or chaque système d’information géographique possède son propre référentiel. Shared Streets vise à proposer, dans une approche de communs numériques, un standard qui facilite les échanges de données entre tous ces acteurs et ensuite à proposer une plateforme qui doit fonctionner une chambre de compensation (clearing house) pour permettre des collaborations entre le public et le privé.
Lever les verrous du partage des données
L’analyse de ces quatre initiatives montre qu’il est possible de lever une partie des verrous et des freins au partage des données des entreprises.
| Les verrous | Expression | Éléments de réponse |
| Partage de la valeur | “Des tiers vont utiliser mes données contre mes intérêts” | Transparence sur les conditions d’usage (AG Data Transparent) |
| Partage de la valeur | “Que vais-je gagner à partager mes données ?” | Des services d’analyse des données, pas uniquement l’échange de données brutes (Airbus Skywise) |
| Risque concurrentiel | “Je ne suis pas en mesure d’identifier avec certitude mes concurrents de demain” | Réversibilité (API Twitter) |
| Risque concurrentiel | “En partageant mes données je risque d’être en position de faiblesse par rapport aux acteurs dominants” | Approche par les communs et gouvernance partagée (Shared Streets) |
| Absence d’un standard d’échange | “Il est trop difficile et coûteux d’échanger des données entre des systèmes incompatibles” | Définition d’un standard partagé (Shared Streets) |
Les vertus de l’expérimentation
Les exemples ci-dessus montrent qu’il est donc tout à fait possible, pour une entreprise, de s’engager dans une démarche volontariste de partage des données. Il faut cependant veiller à ce que le modèle retenu soit adapté à l’environnement dans lequel intervient l’entreprise ainsi qu’à sa place sur le marché. En matière de données, rien ne vaut l’expérimentation, c’est à dire la capacité à tester, dans les conditions réelles du marché, un ensemble d’hypothèses sur le partage des données, ses bénéfices et les risques éventuels.
Pour une entreprise qui souhaiterait explorer ces différentes pistes, l’une des premières étapes est donc de construire un plan d’expérimentation data. Il faut tout d’abord formuler une dizaine d’hypothèses, dont certaines contradictoires, et imaginer des expérimentations permettant de les infirmer ou de les confirmer.
Voici quelques exemples d’hypothèses qu’une entreprise pourrait formuler pour expérimenter le partage de données:
- le référentiel de données que je produis a le potentiel pour être largement utilisé en dehors de mon organisation et constituer le coeur d’une stratégie de plateforme,
- les données de logistique que je récolte peuvent être monétisés auprès de mes fournisseurs, et leur propension à payer excède largement les coûts de mise à disposition,
- de part ma légitimité et ma position sur mon marché, je suis en mesure de proposer un standard de données qui soit adopté par une majorité des acteurs du marché dont mes principaux concurrents,
- le référentiel de données produit par mon concurrent et accessible via une API, peut être utilisé pour enrichir mes propres données,
- …
Un dernier élément, essentiel avant de se lancer: avec une expérimentation on cherche à apprendre, pas nécessairement à réussir. C’est sans doute d’ailleurs les expérimentations si difficiles à faire accepter au sein de la plupart des organisations. Le retour sur investissement (ROI) d’une expérimentation ne se mesure pas en gain de part de marché, de marge ou de revenus. Il doit plutôt se mesurer en gain de connaissance, de compréhension et d’intelligence du marché !
Bibliographie
il ne peut pas avoir d'altmétriques.)