
Citation
L'auteur
Philippe LE MAGUERESSE
(plemagueresse@outlook.fr) - OCEANS ET ASTROLABE
Copyright
Déclaration d'intérêts
Financements
Aperçu
Contenu
Depuis le début des années 2000, l’Union Européenne a libéralisé au fur et à mesure le secteur ferroviaire. Ce mouvement s’est accéléré au début de notre décennie et désormais pratiquement tout le transport ferroviaire (marchandises et personnes) est ouvert à la concurrence en France. Des lignes emblématiques comme Paris-Lyon sont proposées par Trenitalia et Velvet, d’ici 2028, devrait proposer des trains sur l’axe Atlantique.
Le défi : développer la satisfaction client pour prospérer
Dans ce contexte totalement transformé, la capacité de SNCF à satisfaire ses clients devient un facteur clé de succès incontournable. Traditionnellement, des mesures par enquête auprès des voyageurs sont conduites, « à chaud », au plus près du voyage ou « à froid ». Les volumes d’enquête à chaud réalisés par SNCF sont massifs.
Mais si ces mesures complémentaires permettent de comprendre et de hiérarchiser les actions à mettre en place, elles ne permettent pas de répondre de façon plus personnalisée et plus immédiate aux voyageurs. Comment disposer d’une mesure de la satisfaction de chaque voyageur pour chacun de ses trajets et ainsi pouvoir mieux interagir avec chaque client ?
C’est précisément la question qui a été soulevée par la Direction de la connaissance client de SNCF Voyageurs.
La solution : hybrider les sources de données
Le principe méthodologique qui a inspiré et guidé la démarche est celui de l’hybridation des sources de données. Hybrider des données, c’est relier entre elles des données de natures variées et de sources différentes pour créer de la valeur dans les organisations.
Par exemple, associer, depuis une base CRM, des données comportementales d’un client avec les données déclaratives issues d’une enquête conduite auprès de ce même client permet d’avoir à la fois le comment et le pourquoi :
- Comment le CA se construit (type de produits achetés, fréquence, panier, etc.) ?
- Pourquoi le CA se construit (motivation, image, critère de choix, etc.) ?
Appliqué à notre cas, la question devient : quelles données me permettraient d’expliquer et de prédire la satisfaction de chaque voyageur pour chacun de ses trajets, sachant que nous disposons d’un volume important de mesures déclaratives de satisfaction à chaud ?
Il s’agit donc d’identifier des variables causales de la satisfaction ou de l’insatisfaction.
La méthode : objectiver et enrichir la mesure de satisfaction
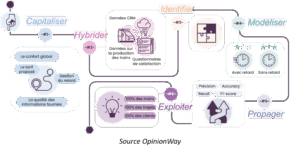
Etape 1 : Capitaliser sur l’existant
Comme on établit un état de l’art avant de se lancer dans une thèse, nous nous sommes appuyés sur la connaissance accumulée par l’organisation pour bien instruire la problématique et orienter la recherche des variables causales pertinentes. Par exemple, quelles clés de lecture des enquêtes de satisfaction présentent les dispersions de notes les plus importantes ? Illustrations : Les plus jeunes voyageurs sont en général plus sévères que les voyageurs seniors ou encore le retard d’un train génère très souvent une insatisfaction.
Etape 2 : Hybrider les données
Où puis je trouver, dans les différents systèmes d’information existants au sein de SNCF, les variables causales que ma connaissance a priori me suggère ? Nous avons retenu deux grands silos : la base clients (CRM) et la base de production (ponctualité, incidents, conditions de service). Au-delà des variables attendues, nous avons exploré plusieurs centaines de paramètres pour élargir le champ de connaissance.
Chaque enquête correspond à un voyageur identifié et à un train précis. Ces deux clés ont permis de relier chaque enquête à son jeu de données. On a ainsi une variable à expliquer (la note de satisfaction) à l’aide de variables explicatives (plusieurs centaines donc portant sur le voyageur et sur le trajet concernés). La préparation des données constitue une étape indispensable et chronophage.
Etape 3 : Identifier les variables clés
Après la phase de divergence sur les variables, il s’agit ici de converger sur un set réduit de variables causales. Des mesures d’indépendance de variable deux à deux sont conduits et permettent d’éliminer les variables trop faiblement reliées à la satisfaction.
Etape 4 : Modéliser
Deux cadres distincts structurent la satisfaction : train à l’heure vs train en retard. Dans le second cas, l’information voyageurs devient déterminante, alors qu’elle reste secondaire dans le premier.
Nous sommes dans une configuration d’un modèle supervisée et de classification binaire (Sur le trajet X, le client Y est-il satisfait ou pas). Comme dans tout projet de data science, différentes familles de modèles de classification supervisée vont être mis en compétition entre eux : arbre, forêt, régression logistique, modèles de gradient boosting ou encore réseaux de neurones.
Le base de données est séparée en 2 ensembles seulement : l’échantillon d’entrainement et l’échantillon témoin qui permettra in fine de déterminer la qualité du modèle.
Cette phase nécessite encore des transformations de variables et est guidée également par la recherche d’une optimisation du nombre de variables nécessaires : il faut d’ores et déjà penser à la phase de déploiement / l’industrialisation.
Etape 5 : Propager
Cette phase permet de mesurer le couple biais (adaptation du modèle) / variance (sensibilité aux données d’entrainement) et de l’optimiser. En quelque sorte, on apprend du jeu de données, mais on n’en devient pas prisonnier. L’objectif n’est pas de prédire le mieux possible les données d’entrainement (on s’en fiche, on a la mesure de la satisfaction !) mais les données pour lesquelles on ne disposera pas de la mesure déclarative.
Cette étape permet également de déterminer les règles de propagation de la modélisation à l’ensemble du data set (y compris donc les trajets pour lesquels nous n’avons pas de mesures déclaratives de satisfaction). L’indicateur de « précision » a été retenu : nous avions besoin d’être le plus sûr possible que lorsqu’un trajet était insatisfaisant, il était vraiment insatisfaisant, quitte à ne pas couvrir tous les trajets insatisfaisants.
Etape 6 : Exploiter les résultats de la modélisation
Le volet data science est achevé et celui de l’exploitation des données enrichies commence. L’ensemble des trajets est désormais renseigné sur la satisfaction.
Les résultats : transformer l’avis en action
C’est un « game changer » : concrètement il devient possible, avec une approche probabiliste, de décrire l’ensemble des trajets avec toutes les variables disponibles en fonction du niveau de satisfaction.
Le niveau retenu peut être celui du voyage : par exemple, quelle est la proportion de voyages satisfaisant à n’importe quelle maille (jour, destination, type de matériel roulant, etc.).
Le niveau retenu peut être celui du voyageur : par exemple, parmi les voyageurs ayant effectué plus de X trajets, quelle est la proportion de ceux qui ont connu plus de Y insatisfactions.
Et il est alors possible d’enclencher des actions personnalisées auprès des clients en fonction de cet historique dans la relation puisque SNCF dispose des coordonnées du client (email notamment) !
Nous ne décrivons pas les actions mises en place mais insistons sur le fait que ce projet rend possible la mise en place d’un véritable « laboratoire vivant » de la satisfaction.
En effet, avec le déploiement du modèle dans le SI, il est possible à la volée de mesurer la satisfaction de chaque trajet, de mettre en place des actions et de suivre les effets de ces actions dans les comportements (via le CRM), dans les opinions et la satisfaction (via des enquêtes). Et de progresser au fur et à mesure et en connaissance et en performance !
A titre d’exemple, les premières actions ont permis de faire gagner entre 5 et 10 points de NPS (Net Promoter Score qui mesure le niveau de recommandation) auprès des publics visés.
L’énonciation du principe de l’hybridation des données fait apparaitre un caractère d’évidence ? En somme, pourquoi ne pas l’avoir fait plutôt ?!
Les enjeux : dépasser les freins
Plusieurs difficultés surgissent dans un tel projet. En voici quelques-unes, attendues et exprimées en quelques lignes. Avant de prendre, en conclusion, de la hauteur sur cette approche.
Le frein technique de la préparation des données
Volumes massifs, réconciliations, nettoyages : autant de défis techniques qui exigent des ressources compétentes en data science et une plateforme robuste (type Dataiku). Le caractère stratégique des données nécessite également de travailler exclusivement dans l’environnement data du client.
Le frein juridique
L’ensemble des données exploitées dans ce cas d’usage constituent de la « first data party » (=informations collectées par l’entreprise directement auprès de son public). La satisfaction est par ailleurs un motif légitime de sollicitation pour une marque.
Il faut cependant respecter les choix des clients en matière de sollicitation. Et donc, interagir avec ses clients pour construire une relation respectueuse dans l’usage des données, de façon à ne pas provoquer des « opt out » massifs.
Le frein organisationnel
Il est nécessaire de solliciter plusieurs services, de les coordonner. Dans notre cas, 3 silos de données ont été fusionnés dans un même data set. Il a fallu également mobiliser d’autres équipes pour la phase d’industrialisation et pour déployer, concrètement auprès des clients SNCF, les actions décidées après l’exploitation des données.
les impacts : de la technique à la transformation organisationnelle
La démarche de l’hybridation des données génère de nombreux bénéfices pour les organisations, comme le suggère le cas présenté (compréhension augmentée, activation facilitée, apprentissage en continu, etc.).
Mais pour en tirer pleinement parti, trois niveaux complémentaires sont à prendre en compte.
Le rationnel : une conduite rigoureuse de projet
Hybrider les données requiert avant tout une organisation solide : préparation des données, choix méthodologiques assumés, respect des contraintes techniques, juridiques et organisationnelles. Sans cette rigueur, le projet ne peut aboutir ni être industrialisé. C’est la dimension rationnelle, indispensable, qui assure la crédibilité et la fiabilité du modèle.
L’émotionnel : une expérience collaborative différente
Au-delà de la méthode, le vrai changement se joue dans la façon de travailler ensemble. Partager ses données, confronter ses visions, chercher collectivement des solutions : c’est une expérience qui bouscule le « business as usual ». L’émotionnel tient ici à l’ouverture, à la curiosité, et à la satisfaction de construire ensemble une approche inédite. Cette dynamique crée une énergie nouvelle dans l’organisation.
Le symbolique : donner du sens et construire un récit commun
Enfin, ces projets créent de la valeur (et pas que financière !) lorsqu’ils nourrissent un « pourquoi » mobilisateur. Ils deviennent une histoire collective qui dépasse le seul cadre technique : contribuer à mieux comprendre et satisfaire le client, construire un langage commun entre silos, renforcer la confiance dans l’organisation, proposer une expérience collaborateur nouvelle, etc.
Conclusion
Un projet d’hybridation des données, ce sont en fait des « travaux pratiques » de transformation des organisations. C’est en faisant qu’on apprend le mieux, qu’on mesure les bénéfices et les limites et qu’on engage un effet systémique durable.
Hybrider les données, c’est aussi renoncer au statu quo. Cette voie de la facilité, cette logique du renoncement à s’interroger, à se remettre en cause et à innover.
La condition préalable reste le courage du porteur du projet en interne. Il peut transformer l’essai et ancrer durablement la dynamique, grâce à un accompagnement méthodologique qui coordonne, challenge et facilite la diffusion et l’appropriation des résultats.
il ne peut pas avoir d'altmétriques.)