
Citation
L'auteur
Ndeye-Emilie Mbengue
(emiliembengue62@gmail.com) - Orange Innovation
Copyright
Déclaration d'intérêts
Financements
Aperçu
Contenu
Les effets néfastes de l’activité humaine sur l’équilibre de la planète sont indiscutables. La pollution, la diminution de la biodiversité, l’épuisement des ressources et le réchauffement climatique résultent directement de nos activités. Pour combattre le réchauffement climatique, il est essentiel de réguler les émissions de gaz à effet de serre dans tous les secteurs, y compris le numérique, qui, bien qu’il ne représente que 4 % des émissions mondiales de gaz à effet de serre, possède un potentiel énergivore élevé.
Les études sur l’impact environnemental du numérique sont rares, et parmi elles, peu se concentrent sur des services spécifiques comme l’intelligence artificielle, dont l’accès est de plus en plus facilité.
L’objectif de cette étude est de mesurer l’impact environnemental de plusieurs catégories de modèles d’intelligence artificielle, des plus simples aux plus complexes. Pour ce faire, plusieurs critères ont été pris en compte : la consommation électrique, la consommation hydrique, les émissions de gaz carbonique, ainsi que le temps d’exécution, la performance algorithmique et le coût financier. Il est crucial de comprendre les compromis entre performances écologiques et industrielles pour optimiser l’utilisation de ces technologies.
Méthodologie
La tâche choisie pour cette étude comparative est l’analyse de sentiments de commentaires de consommateurs, classés en quatre polarités : positive, négative, mixte et neutre. Une revue de l’état de l’art dans ce domaine a permis de constituer une démarche expérimentale et de comprendre les différentes méthodes d’évaluation de l’empreinte environnementale d’un service, notamment l’analyse de cycle de vie définie par la norme ISO 14040. Les différentes étapes du cycle de vie à prendre en compte sont illustrées ci-dessous.
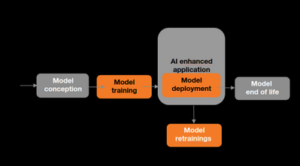
Ces différentes phases comprennent :
- La conception du modèle, avec notamment la recherche des hyperparamètres adéquats.
- Les phases d’entraînement et de réentraînement du modèle.
- Le déploiement du modèle où les utilisateurs effectuent des inférences.
L’étude s’est concentrée sur les phases d’entraînement et de déploiement du modèle, en prenant en compte les scopes d’émissions suivants, comme suggéré par l’étude de Bloom sur l’empreinte carbone :
- Scope dynamique : impacts résultant de l’exécution du code.
- Scope embodied : impact de la fabrication des appareils utilisés (terminaux, équipements réseaux).
- Scope idle : impact des équipements maintenus opérationnels pour permettre l’exécution (datacenters, cloud).
Les chiffres présentés ne tiennent compte que de la partie dynamique, mesurée empiriquement.
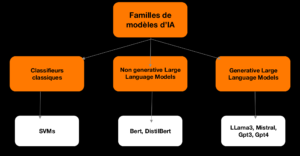
La première étape de l’étude a été de sélectionner différents types de modèles pour l’analyse de sentiments, allant des modèles classiques comme le Support Vector Machine (SVM) et les Transformers Bert et Distill Bert, aux modèles génératifs comme Llama3 8b, Mistral 7b et GPT-3.5.
Ensuite, le fine-tuning et l’inférence de ces modèles ont été réalisés, et leur consommation électrique a été calculée grâce à la bibliothèque CodeCarbon. À partir de cette consommation électrique, d’autres métriques comme les émissions de carbone, le coût financier et la consommation hydrique ont été calculées en se basant sur les références françaises. Toutes les expériences ont utilisé le même type de GPU (modèle A100) pour garantir des conditions expérimentales similaires.
Les données utilisées provenaient de deux corpus différents. Le premier, une base de données open source appelée IMDB, a permis de valider la démarche expérimentale en comparant les résultats à ceux du papier pour des configurations similaires.
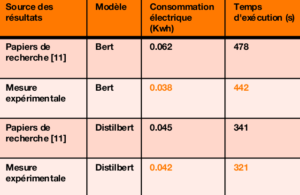
Figure 3-Tableau comparatif des métriques obtenues par CodeCarbon pour le fine tuning de Bert et Distilbert sur IMDB.
La deuxième base de données utilisée correspond aux données issues d’une application interne de l’entreprise. Utiliser ces données permet de sensibiliser sur les inconvénients d’une utilisation inadaptée de l’intelligence artificielle au travers d’un référentiel connu de tous.
Résultats
Les résultats obtenus sur les données internes sont très parlants. En omettant le poids important de la consommation électrique de l’entraînement d’un modèle génératif, une nette différence est déjà perceptible entre les différentes familles de modèles sur la partie inférence, avec des performances algorithmiques très proches.

En considérant les résultats sur une année d’utilisation des modèles au sein de l’application interne et en ne tenant compte que du scope dynamique, l’émission carbone totale est de 7520 kg de CO2 équivalent pour GPT-3.5 contre 0,156 kg pour Bert, représentant un facteur de 10 000. De plus, la f-mesure pondérée de Bert, fine-tuné avec des données internes, est meilleure que celle de GPT-3.5 (0,86 contre 0,79).
Deux éléments de l’étude comparative pourraient être critiqués et méritent d’être justifiés :
- Le choix de fine-tuner Bert et DistilBert sur les données internes, mais pas les modèles génératifs comme Llama3 8b, Mistral 7b ou GPT-3.5. Il a été supposé qu’un modèle génératif, déjà entraîné sur des milliers de données, n’aurait pas une amélioration significative de sa performance algorithmique avec un fine-tuning sur un petit corpus de données, mais que l’impact environnemental serait conséquent.
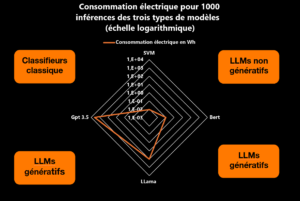
- L’évaluation des performances des modèles génératifs avec un prompt simple : « Classify between the labels positive, mixed, neutral and negative, the sentiment of the following statement: ». Bien que ce prompt simple puisse être préjudiciable pour les modèles non fine-tunés, l’amélioration de la performance algorithmique avec des prompts améliorés est marginale, tandis que la consommation électrique augmente, comme illustré ci-dessous avec Mistral 7b.

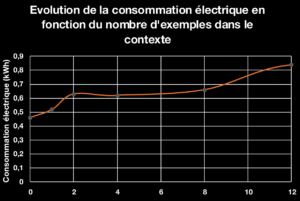
Avec la tendance croissante à l’utilisation des Large Language Models (LLMs) et de l’IA générative, il est important de quantifier leur impact pour sensibiliser les utilisateurs. Un des premiers leviers de frugalité pour l’intelligence artificielle est de choisir le bon modèle pour la bonne tâche. Les besoins matériels des modèles génératifs, dont le coût environnemental est élevé, doivent être pris en compte.
Les résultats obtenus sont précieux pour l’écosystème de l’entreprise, car ils permettent de mettre en lumière des chiffres et des ordres de grandeur sur l’utilisation interne de l’intelligence artificielle pour des tâches courantes. Ces chiffres peuvent dissuader certaines équipes d’opter pour des IAs génératives pour des tâches n’en nécessitant pas, favorisant des solutions de Machine Learning plus classiques.
Conclusion
Cette étude met en évidence l’importance de quantifier l’impact environnemental des modèles d’IA et de gérer prudemment et éthiquement les ressources pour minimiser les impacts écologiques tout en maximisant l’efficacité industrielle. En encourageant l’utilisation de modèles plus écologiques et en sensibilisant les utilisateurs, cette recherche ouvre la voie à une intégration plus responsable de l’IA dans les entreprises. Une politique de monitoring des flux environnementaux, similaire aux métriques de performance industrielle, devrait être mise en place pour optimiser l’utilisation de l’IA.
Bibliographie
- Greenit. (2019). Empreinte environnementale du numérique mondial. https://www.greenit.fr/empreinte-environnementale-du-numerique-mondial/
- ISO. (2006). Management environnemental-Analyse du cycle de vie- Principes et cadre. https://www.iso.org/obp/ui/fr/#iso:std:iso:14040:ed-2:v1:fr
- Anne-Laure Ligozat, et al. (2021). Unraveling the Hidden Environmental Impacts of AI Solutions for Environment. https://arxiv.org/abs/2110.11822
- Alexandra Sasha Luccioni, et al. (2022). Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model. https://arxiv.org/abs/2211.02001
- Jacob Devlin, et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. https://arxiv.org/pdf/1810.04805
- Victor Sanh, et al. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. https://arxiv.org/abs/1910.01108
- Meta. (2024). Meta-Llama-3-8B-Instruct. https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
- Albert Q. Jiang, et al. (2023). Mistral 7B. https://arxiv.org/abs/2310.06825
- Tom B. Brown, et al. (2020). Language Models are Few-Shot Learner. https://arxiv.org/abs/2005.14165v4
- Stanford-NLP. (2021). IMDB Dataset. https://huggingface.co/datasets/stanfordnlp/imdb
- Alexandra Sasha Luccioni, et al. (2023). Energy and Carbon Considerations of Fine-Tuning BERT. https://aclanthology.org/2023.findings-emnlp.607.pdf
- Adrien Berthelot, et al. (2024). Estimating the environmental impact of Generative-AI services using an LCA-based methodology. https://inria.hal.science/hal-04346102v2/
- Haverford-College. (2020). CodeCarbon Methodology. https://mlco2.github.io/codecarbon/methodology.html
- European-commission. (2023). Trends in the use of AI in science. https://research-and-innovation.ec.europa.eu/knowledge-publications-tools-and-data/publications/all-publications/trends-use-ai-science_en
- David Tilman, et al. (2001). Human-caused environmental change: Impacts on plant diversity and evolution. https://research-and-innovation.ec.europa.eu/knowledge-publications-tools-and-data/publications/all-publications/trends-use-ai-science_en
il ne peut pas avoir d'altmétriques.)
Nb. de commentaires
0