
Citation
Les auteurs
Valentin Angelvy
(valentin.angelvy@gmail.com) - ISG Business SchoolLucien Favelin
(lucien.favelin@ipsa.fr) - ISG Business School
Copyright
Déclaration d'intérêts
Financements
Aperçu
Contenu
Introduction
De nos jours, le succès d’une organisation se résume nottament à sa capacité à acquérir et à retenir des talents. Malheureusement, bien que les marchés des entreprises soient grandissants, le nombre de talents sur le marché semble rétrécir.
Ainsi un nouveau data challenge a été proposé par la plateforme « Management & Data Science » : analyser le turnover des collaborateurs de l’entreprise « Xcorp ».
Pour cela, il a fallu identifier les caractéristiques des populations de salariés qui vont rester ou quitter l’entreprise, tout en proposant des solutions pour réduire le turnover des collaborateurs.
Jeu de données
Le jeu de données à notre disposition compte 11 variables (facteurs analysés) pour 10052 collaborateurs.
- Id : Numéro du collaborateur
- Satisfaction level : Niveau de satisfaction des collaborateurs
- Last evaluation : Niveau de satisfaction des collaborateurs lors de l’évaluation précédente
- Number project : Nombre de projets portés par le collaborateur
- Average monthly hours : Nombre d’heures mensuel moyen d’un collaborateur
- Time spend company : Nombre d’années passées au sein de l’entreprise
- Work accident : Information qui précise si le collaborateur a subi un accident du travail
- Promotion last 5 years : Information qui précise si le collaborateur a été sujet à une promotion durant les 5 dernières années
- Job : Secteur dans lequel travaille le collaborateur
- Salary : Salaire du collaborateur (bas, moyen, haut)
- Left : Si le collaborateur a finalement quitté l’entreprise ou non
Nous nous sommes rendu compte que le jeu de données à notre disposition était très propre. En effet, il n’y a pas de valeurs aberrantes ni de valeurs particulièrement extrêmes. Cela nous donne donc une base de travail solide et une analyse étant possible sur l’ensemble du jeu de données.
Méthodologie
Pour l’atteinte de notre objectif, notre data challenge s’est déroulé en 3 phases. La première est une phase d’apprentissage, où l’on se familiarise avec les données (sur les salariés) ainsi que l’outil à disposition BigMl. Cet outil de Machine Learning, une science moderne permettant de découvrir des patterns et d’effectuer des prédictions à partir de données. Il est très efficace dans les situations où les insights doivent être découverts à partir de larges ensembles de données diverses et changeantes : le big data. C’est le cas ici, puisqu’on dispose de données collectées sous format Excel.
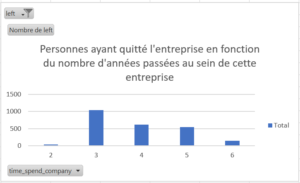
Pour ce faire, notre première étape a été d’analyser les données, de trouver s’il y avait des données aberrantes ou à l’inverse primordiales pour atteindre notre objectif. Ainsi nous avons commencé par effectuer des tableaux croisés dynamiques que vous trouverez ci-dessous.
 |
 |
 |
 |
 |
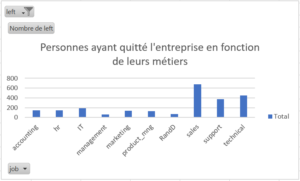 |
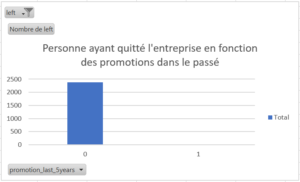
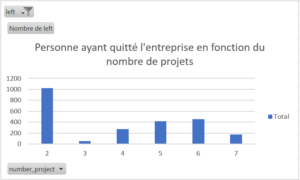
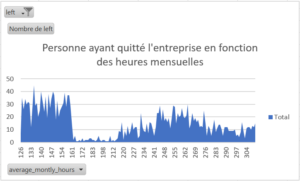
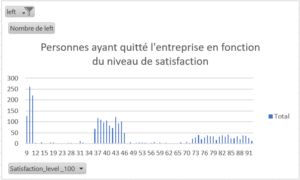
Veuillez noter que les données que vous verrez apparaître ont préalablement été filtrées sur « left=1 », c’est-à-dire qu’elles représentent les personnes ayant quitté l’entreprise.
Nous remarquons alors les points majeurs suivants nous permettant de créer notre persona type d’une personne étant susceptible de quitter l’entreprise :
- Personne n’ayant reçu aucune promotion durant les 5 dernières années
- Personne ayant peu de projets (2) ce qui pourrait signifier un manque de confiance de la part des employeurs.
- Personne au-dessus de 60h/semaine (surcharge) ou en-dessous de 39h/semaine (désintéressement)
- Personne avec une ancienneté moyenne (entre 3 et 5 ans)
- Personne ayant un salaire bas ou moyen
- Personne ayant un niveau de satisfaction inférieur ou égal à 50/100
Forts de cette pré-analyse, nous avons ensuite importé les données à notre disposition sur BigML. BigML est une solution MLaaS qui propose une interface Web permettant la spécification des algorithmes à utiliser et la visualisation des résultats obtenus. La solution fournit une plate-forme facile à utiliser pour développer des modèles d’apprentissage automatique. L’avantage de cette solution c’est que l’utilisateur n’a pas besoin d’une connaissance approfondie des techniques d’apprentissage automatique pour tirer le meilleur parti de BigML.
Dans BigML, la première étape est de renseigner le type de données tel que présenté ci-dessous.
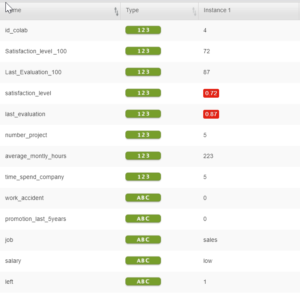
Noter également que nous avons rajouté deux colonnes concernant les niveaux de satisfaction en faisant « *100 » car les nombres décimaux n’étaient pas acceptés par BigML.
La seconde étape était de créer nos datasets. Nous avons fait deux cas : sans aucun filtre de données car le fichier de base nous paraissait propre et avec 2 filtres (moins de 7 ans d’expérience dans l’entreprise & niveau de satisfaction inférieur à 100 ce qui nous donnait un jeu de données de 9585 données)
Nous avons ensuite testé successivement différentes méthodes d’analyse et relevé nos résultats de precision et d’accuracy :
-
- Sans aucun filtre
- Méthode « modèle simple » non optimisé : Précision = 98,2% / Accuracy : 98,3%
- Méthode « modèle simple » optimisé : Précision = 98,2% / Accuracy : 98,6%
- Méthode « ensemble/forest » non optimisé : Précision = 98,9% / Accuracy : 98,6%
- Méthode « ensemble/forest » optimisé : Précision = 99,1% / Accuracy : 98,8%
- Méthode « OptiML », choix du meilleur modèle : Précision = 99,3% / Accuracy : 99%
Vous trouverez les détails de ce modèle ci-dessous (avec filtres <7ans d’expérience & <100 de niveau de satisfaction):
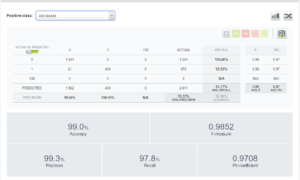
- Méthode « modèle simple » non optimisé : Précision = 96,2% / Accuracy : 97,7%
- Méthode « ensemble/forest » optimisé : Précision = 98,1% / Accuracy : 98,4%
- arrêt des test car les résultats sont moins bons qu’avec les filtres
Résultats
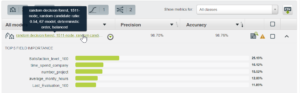
Dans toute analyse, il existe des facteurs déterminants. Nous avons pu relever le poids des colonnes dans le calcul. En effet, le logiciel BigML sait reconnaitre quelles colonnes sont plus ou moins importantes. Nous pouvons remarquer que les colonnes job, salaire, accidents de travail et promotion durant les 5 dernières années sont presque négligeables comme visible sur la capture d’écran ci-dessous :
Préconisations
Afin de protéger au maximum son effectif, nous pouvons recommander les points d’action ci-dessous :
- « Prendre la température » régulièrement en effectuant des questionnaires de satisfaction : il s’agit ici de détecter au plus tôt les profils à risque et les personnes n’étant pas à l’aise dans leur environnement. Si le résultat est inférieur ou égal à 50/100 alors il serait préférable de prendre des mesures telles qu’un entretien individuel ou autre pour comprendre le problème,
- Proposer des promotions aux personnes méritantes : Nous avons pu remarquer que parmi les personnes ayant quitté l’entreprise, aucune n’avait reçu de promotion durant les 5 années précédentes. Cela est donc un potentiel facteur de démission,
- Augmenter la masse salariale / ne pas sous-payer : La majorité des collaborateurs ayant quitté l’entreprise avaient un salaire bas, et a contrario, toutes les personnes ayant un salaire haut sont restées. Il s’agit donc d’un facteur participant grandement au niveau de satisfaction des employés,
- Limiter le nombre d’heures mensuelles : De nombreux employés effectuant plus de 60h/semaine ont quitté l’entreprise. La surcharge de travail peut donc mener à la perte de ses collaborateurs,
- Faire preuve de confiance et de reconnaissance : La majorité des collaborateurs ayant quitté l’entreprise n’étaient porteurs que de 2 projets. Cela peut traduire un manque de confiance de la part des employeurs à donner plus de responsabilité aux employés. Le manque de reconnaissance et de confiance est donc également un facteur majeur de démission,
- Mettre en place des formations pour les personnes ne faisant pas assez de projets : Certains salariés quittent l’entreprise car ils ont trop peu de projets, ne se sentent pas assez utile et ont un sentiment d’appartenance trop faible. Ainsi les former pour qu’ils acquièrent des domaines d’expertises différents leur permettrait d’avoir plus de projets à leur charge.
Conclusion
Comme nous avons pu l’aborder auparavant, conserver les talents dans une entreprise n’est pas une mince affaire surtout dans une grosse entreprise, où le management est majoritairement vertical et n’incite pas au dialogue social entre salarié et manager. Le travail des Ressources Humaines est primordial. Certains salariés n’oseront exprimer leurs pensées, des managers n’arriveront pas à déceler les difficultés que ces derniers peuvent rencontrer et cela complexifie profondément les objectifs du service RH.
C’est à ce moment-là qu’entre en jeu l’analyse des données de chaque salarié, que ce soit via des questionnaires pour leur satisfaction en entreprise ou bien par des données factuelles comme le nombre d’années en entreprise. Croiser ce type de données, à une échelle de quelques salariés est faisable manuellement, mais lorsque l’entreprise voit son nombre de salariés grandir de manière exponentielle c’est une mission « quasi impossible ». L’utilisation de la data science devient alors primordiale, puisqu’elle permet de décupler la productivité de l’humain sans le remplacer.
Les préconisations que nous avons faites à l’entreprise « Xcorp » n’auraient pas été possibles en si peu de temps sans l’outil BigML.
Outre les Ressources Humaines, la data science peut avoir un réel apport stratégique comme le démontre la plateforme d’œuvres cinématographiques et télévisuelles Netflix : elle décide quelles séries produire en allant chercher les patterns de visionnage de son contenu pour comprendre ce qui suscite l’intérêt des utilisateurs.
il ne peut pas avoir d'altmétriques.)