
Citation
L'auteur
Sophie Balech
(sophie.balech@gmail.com) - IAE d’Amiens
Copyright
Déclaration d'intérêts
Financements
Aperçu
Dans cette note, nous nous interrogeons sur la manière de détecter et d’évaluer les antagonismes présents dans les discours. Prenons les professions de foi des candidats à une élection présidentielle : peut-on objectivement quantifier la nature de gauche ou de droite des discours ? Plus précisément, y-a-t-il une différence de discours inhérente à l’appartenance des candidats à différents mouvements politiques ?
Contenu
Introduction
Si nous prenons à présent les discours dans le temps des candidats d’un même parti à une élection, peut-on objectivement évaluer l’évolution du courant de pensée de ce parti ? Le parti socialiste est-il toujours de la même gauche que dans les années 1970 ? Ce sont ces questions qui ont conduit au développement du modèle Wordfish par Slapin et Proksh en 2008 (Slapin & Proksh, 2008).
Leur modèle, développé à l’origine en sciences politiques, permet de déduire les oppositions des acteurs à travers le vocabulaire employé par chacun d’eux. L’évolution du vocabulaire employé dans le temps par un même acteur permet de mettre en lumière les différents vocables représentatifs de d’une évolution de la pensée. L’idée est que dans l’arène sociale, les acteurs s’opposent entre eux, selon une grandeur commune (Boltanski et Thévenot, 1991), et cette opposition se traduit dans le discours propre de chacun des acteurs : ces derniers vont utiliser le langage de manière différente pour exprimer leurs positions et potentiellement dévaloriser les positions de leurs adversaires.
Le modèle Wordfish
Le modèle mathématique est agnostique quant à la nature de l’antagonisme présent dans les textes. Il utilise les fréquences d’apparition des termes, supposées suivre une loi de Poisson, pour placer les textes les uns par rapport aux autres, sur un unique axe. Il est considéré que le nombre d’occurrence du mot j dans le discours de l’acteur i au temps t est fonction du contexte dans lequel le discours est produit, des effets propres du mot, de l’importance du mot pour discriminer la position de l’acteur et de la position de l’acteur au temps t. D’une manière formelle, nous obtenons :
yijt=Poisson(λijt)
λijt=exp(αit+ψj+βj∗ωit)
Avec : yijt , le nombre d’occurrences du terme j dans le discours d’un acteur i au temps t, αit, les effets du contexte sur l’acteur i au temps t, ψj, les effets propres du terme j, βj, un estimateur de la spécificité du poids du terme j qui permet d’évaluer l’importance du terme pour discriminer les acteurs entre eux, ωit, la position estimée de l’acteur i au temps t.
Les positions sont estimées par un algorithme EM (expectation-maximisation), qui permet une estimation du maximum de vraisemblance sur des variables latentes.
Toute opposition, dès lors qu’elle se traduit par une utilisation différente de vocabulaire, peut alors être détectée, sans qu’il soit nécessaire de connaître à l’avance les positions des acteurs ou les textes de référence pour chacune des positions. Un corpus de politiques permettra de mettre en évidence les oppositions droite / gauche tout autant que progressiste / conservateur, mais l’on peut aussi repérer les antagonismes juste / injuste, ou les antagonismes d’intérêt, dans des corpus de nature plus économiste.
Le modèle permet de représenter sur une échelle unidimensionnelle les positions des acteurs les uns par rapport aux autres, ou leurs évolutions dans le temps, suivant la nature des corpus. Il permet aussi de visualiser les termes en fonction de leurs occurrences et de leurs utilisations par les différents acteurs.
Le cas d’application : Uber
Nous appliquons ici le modèle Wordfish à un cas particulier : il s’agit du conflit qui s’est joué en France autour du développement de l’activité de chauffeur VTC, déclenché avec l’apparition d’Uber sur le marché français à partir de 2012-2013.
La période sur laquelle court le conflit qui nous intéresse va de 2013 à 2017 : l’arrivée d’Uber sur le marché de la mobilité parisienne, qui va ensuite s’étendre aux plus grandes villes de France, soulève la colère des chauffeurs de taxis qui voient naître une redoutable concurrence à leur activité. En 2014 et 2015, les manifestations sont fréquentes à mesure que le débat public et législatif se cristallise autour de certains points marquants (la maraude électronique, le statut des chauffeurs, les tarifs). Les décisions prises seront alors appliquées à partir de 2016-2017, dans l’attente du verdict de la Cour de Justice de l’Union Européenne concernant le statut juridique de l’activité exercée par Uber et consorts, décision qui aura des conséquences sur toutes les législations nationales des pays membres.
Nous allons utiliser le modèle Wordfish pour déterminer les positions des acteurs dans le conflit qui a pu opposer Uber à la ville de Paris, et les taxis aux chauffeurs VTC. Les données collectées représentent les positions publiques, exprimées à travers des communiqués de presse, des posts de blog et des compte-rendus de débats, des différents acteurs identifiés dans le conflit[1]. Le corpus se compose de 228 documents partagés entre 8 émetteurs, et les textes se trouvent au format .txt.
Les compagnies de taxis sont représentées par la CGT-Taxi, qui représentent les chauffeurs, et par la FNAT et l’UNIT pour les représentations patronales. Allocab, Uber et la CFDT-VTC représentent les positions des nouveaux entrants sur la marché. Les discours de la Mairie de Paris et de l’Autorité de la Concurrence permettent d’avoir le point de vue des pouvoirs publics.
La préparation des données
Les packages utilisés pour réaliser cette étude sont au nombre de six :
library(tidyverse) #le langage du code
library(tidytext) #le langage pour le texte
library(quanteda) #le traitement des corpus
library(lubridate) #la gestion des dates
library(reshape2) #la transformation des données (pour les graphiques notamment)
library(wordcloud) # les nuages de mots
L’import des données consiste en la récupération des textes enregistrés dans des fichiers .txt dont les titres correspondent à la date d’émission du texte, rangés dans différents sous-dossiers aux noms de l’acteur concerné. On utilise ces différentes données pour construire notre corpus de textes, et les variables (auteurs, années) correspondant à chaque document. Pour plus de détails, on pourra se référer à cette page pour l’import des données avec le package quanteda.
tbl_french <- list.files(pattern = "*.txt",recursive = TRUE, include.dirs = TRUE ) %>% #on cherche les fichiers .txt dans les différents sous-dossiers
map_chr(~ read_file(.)) %>% #on récupère le texte dans une variable nommée .
data_frame(text = .)%>% #on nomme la colonne « text »
mutate(doc=list.files(pattern="*.txt",recursive=TRUE))%>% #on crée une variable d'identification des documents à partir de leur nom et du nom des sous-dossiers
separate(doc, c("acteur","date"))%>% # variables acteur et date créées à partir de l'identification des documents
mutate(date=ymd(date, truncated=1))%>% # on modifie le format de la date
mutate(year=year(date))%>% #on extrait l'année
mutate(document=paste0("text", c(1:228) )) # on numérote les documents
tbl_french
## # A tibble: 228 x 5
## text acteur date year document
## <chr> <chr> <date> <dbl> <chr>
## 1 "Taxi/VTC : AlloCab.com au cœur des né~ Alloc~ 2013-03-13 2013 text1
## 2 "Taxi-VTC : Décret des 15 minutes susp~ Alloc~ 2013-05-02 2013 text2
## 3 "le 12 août 2013\r\n\r\nLes 15 minutes~ Alloc~ 2013-08-12 2013 text3
## 4 " le 17 octobre 2013\r\nTaxis vs VTC :~ Alloc~ 2013-10-17 2013 text4
## 5 "le 18 octobre 2013\r\nLe mouvement le~ Alloc~ 2013-10-18 2013 text5
## 6 "\r\nLes 15 Minutes des VTC : Allocab.~ Alloc~ 2014-01-13 2014 text6
## 7 "Les VTC plébiscités par les francilie~ Alloc~ 2014-04-14 2014 text7
## 8 "Rapport Thévenoud : sur la voie de l’~ Alloc~ 2014-04-24 2014 text8
## 9 "Les VTC exclus des voies réservées su~ Alloc~ 2014-05-28 2014 text9
## 10 "AlloCab.com défend l’activité des VTC~ Alloc~ 2014-09-01 2014 text10
## # ... with 218 more rows
Nous avons maintenant à épurer le corpus des mots trop fréquents qui n’apportent pas d’information supplémentaire et qui allongent le temps de calcul tout en donnant des solutions illisibles. Nous allons donc supprimer des textes l’ensemble des stopwords, des mots qui permettent l’articulation du langage mais qui n’apporte pas de sens particulier. Le package ‘quanteda’ dispose d’un dictionnaire de ces stopwords en français, que nous agrémentons de quelques termes supplémentaires.
#on récupère le dictionnaire des stopwords en français
sw<-get_stopwords("fr")
#on ajoute les mots manquants
sw<- bind_rows(data_frame(word = c("ville","l'autorité","a","c'est","n'est","d'un","d'une","n'a", "publié","parnathanaelle","leshem"),
lexicon = c("custom")),
sw)
#on transforme en format dictionnaire
swdic<-rename(sw, sentiment=lexicon)
swdic<-as.dictionary(swdic)
Maintenant que nous disposons de la base des textes et du dictionnaire des stopwords personnalisé, nous allons passé aux premiers traitements des textes. La fonction corpus() permet de transformer les données importées en objet de type corpus. Nous pouvons alors extraire les termes utilisés (tokens). Pour alléger le traitement, nous enlevons les stopwords et regroupons les termes qui apparaissent majoritairement ensemble, et qui donnent ainsi une unité sémantique supplémentaire. Par exemple, nous avons deux termes, taxi et parisien, mais leur forte co-occurrence, ou apparition simultanée, nous donne un nouveau « terme », taxi_parisien pour parler de l’entité régionale de la profession. Nous pouvons ensuite transformer ces données en matrice documents-features, qui croise les documents et les occurrences des tokens.
#Transormation en objet corpus corpus
corpus<-corpus(tbl_french)
corpus
## Corpus consisting of 228 documents and 4 docvars.
#tokens
tok<-corpus%>%
tokens(remove_numbers = TRUE, remove_punct=TRUE, include_docvars = TRUE) %>%
tokens_tolower()%>%
tokens_remove(swdic)
#les mots apparaissant l'un après l'autre fréquemment
cap_toks <- tokens_select(tok, valuetype = 'regex', case_insensitive = FALSE, padding = TRUE)
cap_col <- textstat_collocations(cap_toks, min_count = 3, tolower = FALSE)
head(cap_col, 10)
## collocation count count_nested length lambda z
## 1 madame maire 102 0 2 7.130781 38.55068
## 2 mise place 70 0 2 6.492248 35.52157
## 3 millions d'euros 75 0 2 8.212048 32.88583
## 4 voie publique 71 0 2 8.639470 32.42845
## 5 monsieur maire 60 0 2 5.471119 32.13760
## 6 mme maire 58 0 2 5.420064 31.58787
## 7 service public 49 0 2 5.982750 30.50014
## 8 adjoint président 58 0 2 8.516859 30.35849
## 9 prise charge 68 0 2 9.180832 29.74271
## 10 président merci 44 0 2 6.276477 29.52744
tok <- tokens_compound(tok, cap_col[cap_col$count > 10])
rm(cap_toks,cap_col)
head(tok$text101, 9)
## [1] "commission" "professionnelle" "taxi_parisien"
## [4] "décembre" "l'incompréhension" "totale"
## [7] "vivons" "tous" "taxi"
#document-features matrix
dfm<-dfm(tok)
dfm
## Document-feature matrix of: 228 documents, 15,969 features (98.3% sparse).
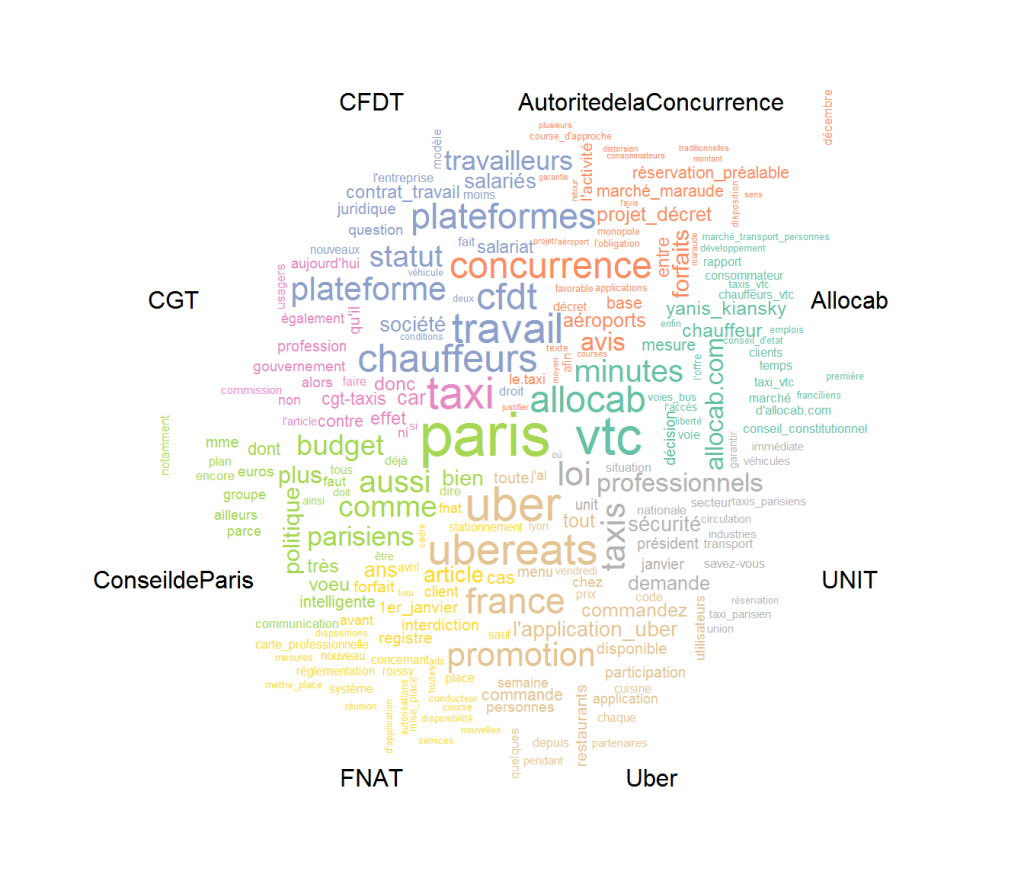
On peut dès à présent représenter les termes les plus fréquents de chaque acteur. Pour cela, nous allons réaliser un nuage de mots qui distingue les occurrences entre les différents acteurs, grâce à la fonction de comparaison comparison.cloud() de ‘wordcloud’. Nous devons auparavant transformer le format des données pour qu’elles soient compréhensibles pour la fonction. Comme Il nous importe de pouvoir distinguer les textes entre eux en fonction de leurs auteurs, nous allons créer une variable de groupe, la variable « acteur », pour regrouper tous les textes émis par le même auteur ensemble.
#on groupe le dfm par acteur
dfmgroup<-dfm_group(dfm,groups = "acteur")
dfmgroup
## Document-feature matrix of: 8 documents, 15,969 features (77.9% sparse).
#on transforme pour ne garder que les 40 les plus importants pour chaque acteur (graphique trop gros sinon)
d<-tidy(dfmgroup)%>%
group_by(document)%>%
top_n(40)%>%
ungroup%>%
acast(term ~ document, value.var = "count", fill = 0)
#wordcloud
comparison.cloud(d,scale=c(2.5,0), #échelle de la taille des mots selon la fréquence
colors = brewer.pal(8,"Set2"), #palette de couleurs
title.size = 1, #taille des titres
use.r.layout = T, langage R utilisé pour les collisions
title.bg.colors = NULL, #arrière-plan des titres
title.colors = "black") #couleur des titres
Le nuage de mots nous montrent déjà une relative diversité dans les termes employés par les différents acteurs. Ces différences reflètent les intérêts de chacune des parties en présence : Uber cherche à promouvoir ses services, la CFDT à défendre les droits des travailleurs des plateforme, là où le principal syndicat patronal de la profession de taxis est centré sur le respect de la loi vis-à-vis de sa profession.
Les résultats du modèle Wordfish
Nous appliquons maintenant le modèle Wordfish à nos données. Son exécution ne demande rien de plus qu’une simple ligne de code. Nous groupons cette fois les données par acteur et par année, afin de voir l’évolution des discours de chacun dans le temps.
#on groupe en fonction des acteurs et des années
dfmgroup<-dfm_group(dfm,groups = c("acteur","year"))
#le modèle wordfish
wf <- textmodel_wordfish(dfmgroup)
summary(wf)
##
## Call:
## textmodel_wordfish.dfm(x = dfmgroup)
##
## Estimated Document Positions:
## theta se
## Allocab.2013 0.253825 0.016934
## AutoritedelaConcurrence.2013 0.569488 0.016336
## CGT.2013 0.525453 0.008220
## UNIT.2013 0.315736 0.022592
## # ... with 22 more rows
##
## Estimated Feature Scores:
## taxi vtc allocab.com cœur négociations l'assemblée nationale
## beta 6.0611 5.6418 0.6077 -0.08334 0.656 2.784 4.480
## psi 0.3779 0.8801 -0.3316 -1.31842 -1.446 -2.044 -0.727
## paris mars jour président-fondateur d'allocab.com rend
## beta -0.08235 -0.2996 -0.1714 0.576 0.6462 0.9043
## psi 3.17675 0.2821 0.7963 -1.574 -0.9908 -0.7071
## session travail député thévenoud l'ensemble acteurs première genre
## beta 0.2309 0.3003 8.543 6.171 0.4054 0.3646 -0.2739 0.1282
## psi -3.2776 2.0022 -2.650 -2.743 1.2687 0.9282 1.1718 -0.9607
## table ronde entre taxis l'objectif réconcilier d'échanger
## beta 0.149 0.5797 -0.1048 3.760 -0.008629 0.2309 0.5886
## psi -0.493 -1.9808 1.9637 1.622 0.142846 -3.2776 -1.9837
## paisiblement revendications
## beta 0.2309 1.8344
## psi -3.2776 -0.6276
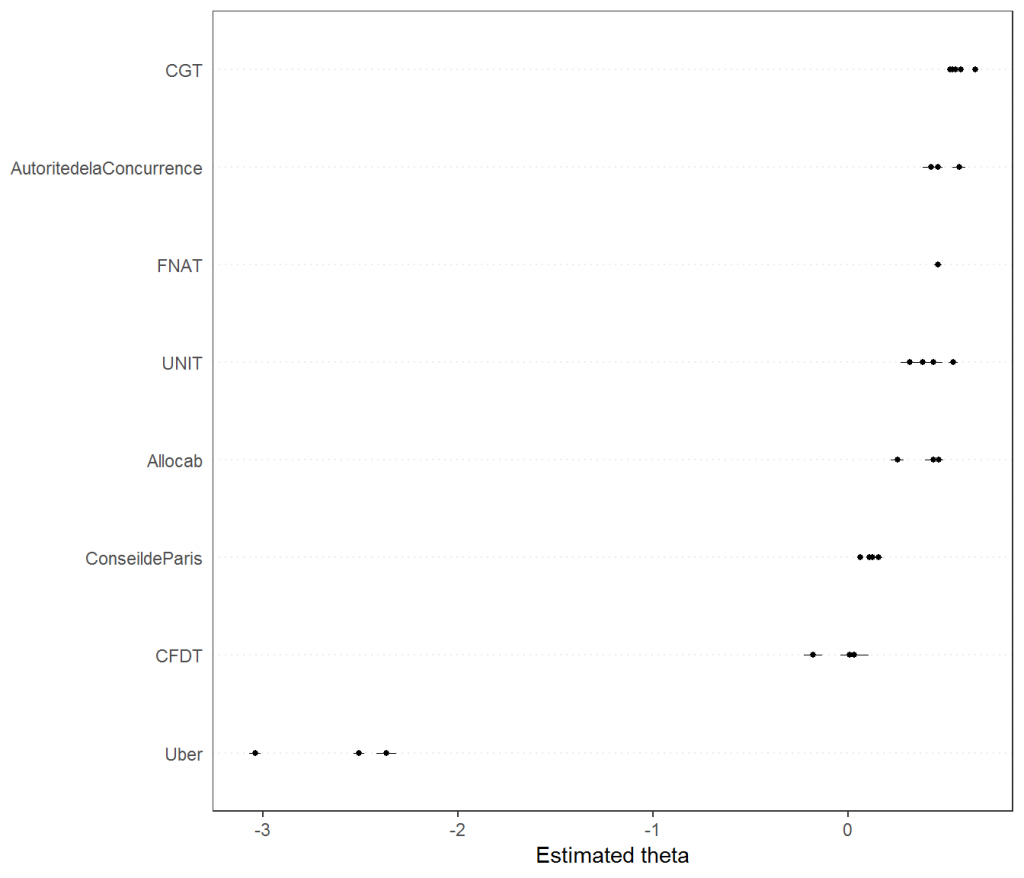
Les paramètres thêta permettent de positionner les différents acteurs entre eux sur un seul axe, tandis que les paramètres bêta et psi permettent de positionner les termes entre eux, en fonction de leur fréquence d’occurrence dans le corpus global (psi) et de leur spécificité d’appartenance à un acteur (bêta). Nous pouvons donc représenter ces résultats graphiquement. Pour cela, nous créons des étiquettes de noms des acteurs et des années.
#les étiquettes acteur et années
doclab <- paste(docvars(dfmgroup, "acteur"))
docyear<- paste(docvars(dfmgroup, "year"))
Nous pouvons représenter le positionnement des acteurs entre eux, chaque point correspondant à la position d’une année, mais d’une manière générale la fonction affiche un point par document.
#positionnement des acteurs
textplot_scale1d(wf, doclabels = doclab)
Nous pouvons aussi représenter les positions des acteurs durant chaque période, ou pour chaque période les positions des acteurs, en ajoutant une variable de groupe à la fonction précédente. Nous présentons le code et laissons au lecteur intéressé le soin de produire les figures.
#positionnement des acteurs
textplot_scale1d(wf, doclabels = doclab, groups=docyear)
#dans l'autre sens
textplot_scale1d(wf, doclabels = docyear, groups=doclab)
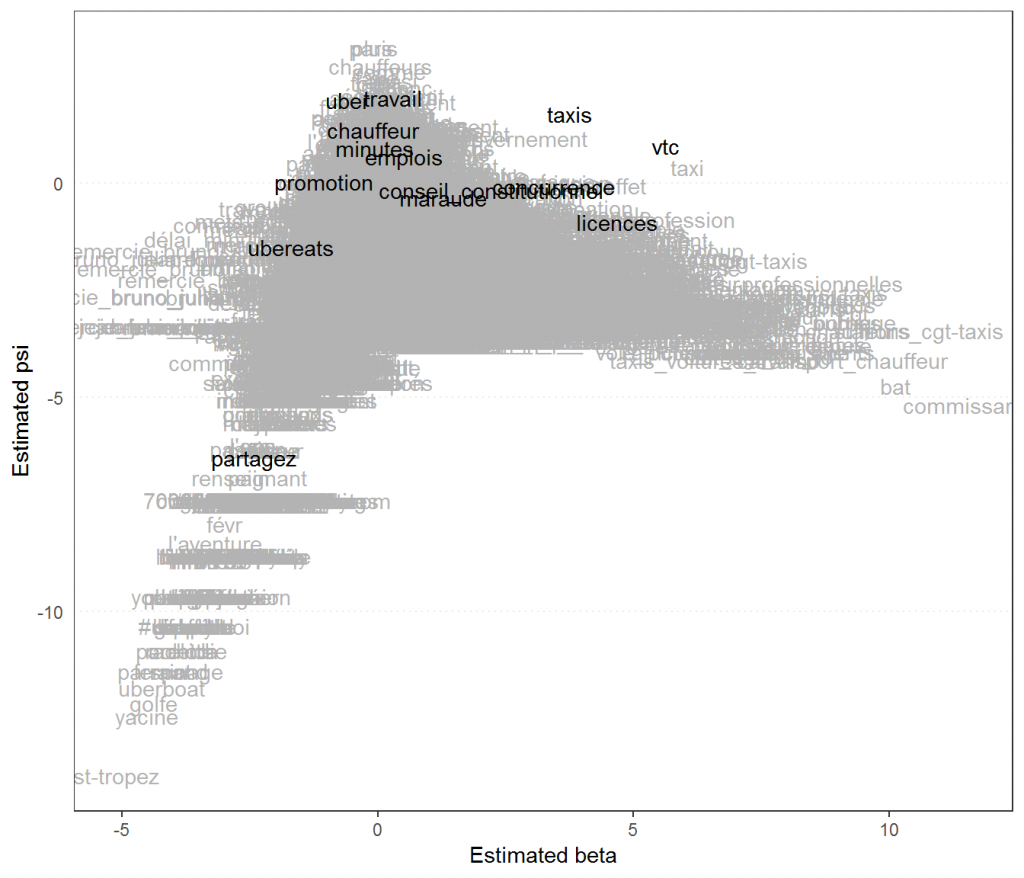
Nous pouvons enfin représenter les positions des mots entre eux, pour identifier les spécificités des discours. Sur le graphique, nous pouvons mettre en évidence un certain nombre de termes pour gagner en lisibilité. Les mots situés au centre et en haut sont les mots les plus utilisés par tous les acteurs, ceux en bas et aux extrémités de l’axe des abscisses correspondent aux termes spécifiques des acteurs positionner aux extrémités de l’axe de comparaison des acteurs.
#positionnement des mots
textplot_scale1d(wf, margin = "features",
groups = "acteur",
highlighted = c("taxis","vtc","licences","minutes","uber",
"chauffeur","maraude","ubereats",
"concurrence","emplois","travail","partagez","promotion",
"conseil_constitutionnel"))
Conclusion
À l’étude des différents résultats, la position particulière d’Uber dans le débat public sur le conflit qui touche ses chauffeurs est évidente : la plateforme ne répond pas directement sur le même terrain, son discours met en avant son offre par de multiples messages à caractère promotionnel. La réponse au conflit d’Uber se fait directement auprès de ses utilisateurs (producteurs et consommateurs) et dans les tribunaux. L’opposition la plus marquée se joue ensuite entre la CGT et la CFDT, qui défendent chacune les intérêts de leurs propres chauffeurs, taxis contre VTC. Allocab et l’UNIT semblent tenir un discours similaire, centré sur les mêmes intérêts, même si l’on peut douter de leur accord quant aux différentes mesures réglementaires prises au cours du temps. L’Autorité de la concurrence montre un glissement, d’un vocabulaire centré sur les taxis, vers la prise en compte des intérêts des chauffeurs de VTC.
Le modèle Wordfish est d’un grand intérêt pour identifier les oppositions entre acteurs et leurs évolutions sur la base du vocabulaire employé. Ses résultats ne peuvent être analysés et trouver tout leur sens qu’en s’associant à d’autres outils d’analyse. On renvoie le lecteur intéressé par plus de détails sur Uber et les conditions de son apparition à Paris à la thèse de l’auteure de cette note (Balech, 2019).
Bibliographie
Balech S. (2019), L’institutionnalisation des plateformes – Les cas d’Airbnb et Uber à Paris, Thèse de doctorat en sciences de gestion, Université Paris-Nanterre
Thévenot, L., & Boltanski, L. (1991). De la justification. Les économies de la grandeur. Gallimard.
Slapin, J. & Proksch,S. (2008). « A Scaling Model for Estimating Time-Series Party Positions from Texts » American Journal of Political Science 52(3): 705-722.