
Citation
Les auteurs
Michel LUTZ
(michel.lutz@total.com) - TotalWilfrid AZAN
- Université de LyonAurélien GALICHER
- Total
Copyright
Déclaration d'intérêts
Financements
Aperçu
Contenu
Introduction
Aujourd’hui, l’IT des grandes organisations n’est pas toujours fait pour intégrer les pratiques liées à la data science et le transfert de savoirs peut ne pas s’opérer pas (Azan et al., 2017 ; Azan et al. 2010). L’IT s’est organisée pour gérer des projets longs et lourds, avec progiciels, des centres de service, des cycles en V, un objectif principal de réduction des coûts. Or, les projets data science requiert de fortes compétences scientifiques, de l’agilité, de la proximité avec les métiers, de l’open source.
Cette tension entre l’informatique des années 2000 et l’irruption de la science des données est source d’inefficiences organisationnelles mais aussi, parallèlement de gains de productivité potentiels lorsque l’IT sait intégrer ces nouvelles technologies. De plus, actionner la data science dans les organisations n’est pas qu’une question technologique, mais implique aussi de traiter plusieurs autres sujets (gouvernance des données, etc.). Cette révolution des données fait suite à la révolution du cloud, pour autant les compétences dans les directions SI ont évolué moins rapidement.
Le cas de Total est intéressant à ce titre car il vise à concilier l’agilité et le rôle des SI au service de la data science, grâce à une approche bout-en-bout que nous décrivons dans cette contribution. Le rôle d’un dispositif nommé « Data Squad » est souligné dans le développement qui suit.
Exploitation agile des données
Chez les entreprises « classiques », la structuration totale autour de la donnée n’est pas toujours naturelle. Chez les GAFA, l’exploitation des données en tant que cœur du business model est naturelle et modèle complètement l’organisation et ses processus (on parle parfois de « data-driven company »). A contrario, les entreprises « classiques » sont essentiellement structurées autour d’une organisation des données englobée par la filière informatique, organisée comme une fonction support, un centre de service, antinomique avec une exploitation agile des données.
La littérature s’organise autour de deux types d’agilité du système d’information.
| Agilité stratégique | Fait d’accroître la flexibilité, l’aptitude au changement,. La dynamique de la stratégie passe par l’exploitation rapide des imperfections du marché, par des mouvements stratégiques fondés sur l’innovation, par des transformations répétées de l’organisation au service de « coups offensifs » ou de réponses défensives. Cette vision stratégique fondée sur le mouvement peut s’appuyer sur un recours accru aux TI. Le développement de cette « agilité compétitive» peut, en particulier, reposer d’abord sur la reconfiguration des activités au sein de réseaux et,ensuite, sur les ressources spécifiques découlant de l’apprentissage organisationnel. | Reix et al. (2011), Cao (2017) |
| Agilité compétitive | Fait de reconfigurer des activités au sein de réseaux et, ensuite, sur les ressources spécifiques découlant de l’apprentissage organisationnel. Le SI permet au jour le jour d’ajuster l’organisation à l’environnement.
|
Reix et al. (2011), Barocas & Boyd (2017), Cao et al. (2015), Azan and al. (2018) |
Tableau 1. Agilité en SI d’après Reix et al. (2011)
Nous nous situons dans la deuxième acception, par « exploitation agile des données », nous entendons la capacité à livrer rapidement des services basés sur de la donnée de bout-en-bout aux utilisateurs. Un service de bout-en-bout est nécessairement multidimensionnel. En effet, il va bien au-delà d’une question d’analyse des données. Il doit permettre d’extraire des données, les manipuler et restituer les résultats aux utilisateurs de façon industrielle. En ce sens, il doit couvrir les facteurs suivants :
Usage de la donnée : les usages modernes sont multiples et vont bien au-delà de la traditionnelle BI d’entreprise : data visualisation, BI self-service, interfaces de restitution en langage naturel (agents conversationnels par exemple) et, très populaire aujourd’hui, data science. Sur le cas précis de la data science, l’intégration du code dans les systèmes IT classiques pose question. Si les DSI traditionnelles maîtrisent les langages classiques tels que Java, PHP, ABAP… il en va autrement des langages plébiscités par les data scientists, notamment R ou Python. En conséquence, le risque est fort que des développements très prometteurs dans ces langages ne franchissent pas le stade de prototype, par incapacité à déployer ces langages dans des environnements de production ;
Expérience utilisateur : l’acceptation de ces nouveaux usages par les utilisateurs doit encore être renforcée : comment construire un tableau de bord efficace, comment passer d’un script de modélisation statistique à un outil convivial ? Plus important encore : comment s’assurer que le traitement analytique appliqué répond bien à un besoin d’aide à la décision exploitable et attendu par les métiers ? (ce point précis est développé dans Lutz et Boucher, 2016)
Architecture analytique : les usages modernes s’appuient sur des briques techniques plus flexibles que les traditionnels entrepôts de données. On parle aujourd’hui beaucoup de « datalake », pouvant être vu sous deux axes :
- Axe technique, en tant qu’alternative low-cost et plus souple en termes de dimensionnement aux entrepôts de données classiques. Ces composants permettent également d’intégrer plus facilement des données peu structurées (pas de modèle de données a priori)
- Axe fonctionnel qui, au-delà de la technologie, milite pour le déploiement de grands réceptacles de données transverses aux silos organisationnels, facilitant l’accès, le partage des données et de croisement de données pour développer des usages nouveaux ;
Gouvernance de la donnée : terme générique incluant la nécessité d’organiser des rôles, responsabilités et processus autour de la donnée, afin de garantir la gestion et le maintien en qualité des bases de données, de rationaliser les modèles de données (référentiels, gestion des données maîtres), de cadrer le partage des données et le respect des exigences légales (ex. : GDPR), etc. En effet, à partir du moment où l’on favorise la circulation de la donnée et son usage dans des applications décisionnelles, il convient d’en avoir une maîtrise exemplaire. Le cas contraire, on risque de fausser des modèles ou des prises de décisions en les alimentant par des données fausses, ou d’enfreindre la loi, par exemple en maîtrisant pas la diffusion de données personnelles.
En parallèle de ces grandes composantes, un service ne pourra être délivré que si le projet de développement se base sur les principes de développement agile et sur des outils favorisant la productivité. Les principes de l’agile ont renversé les cycles en V traditionnels (modèle de développement informatique standard depuis les années 1980, qui, contrairement au développement agile, distingue fortement les étapes de spécification et de conception, les étapes de codage, et les étapes de test), et ce depuis les années 2000. Leur valeur est encore plus forte dans le cadre des projets basés sur de l’analyse de données. En effet, ces projets sont par nature exploratoires et les interactions avec les métiers sont d’autant plus nécessaires pour emmener le projet dans la bonne direction.
Le cas Total : un service « Data Squad » pour accompagner les projets data de bout-en-bout
Total a mis en place un dispositif nommé « Data Squad » pour apporter un accompagnement de bout-en-bout aux projets data. Cette vision « bout-en-bout » est résumée par l’image qui suit.
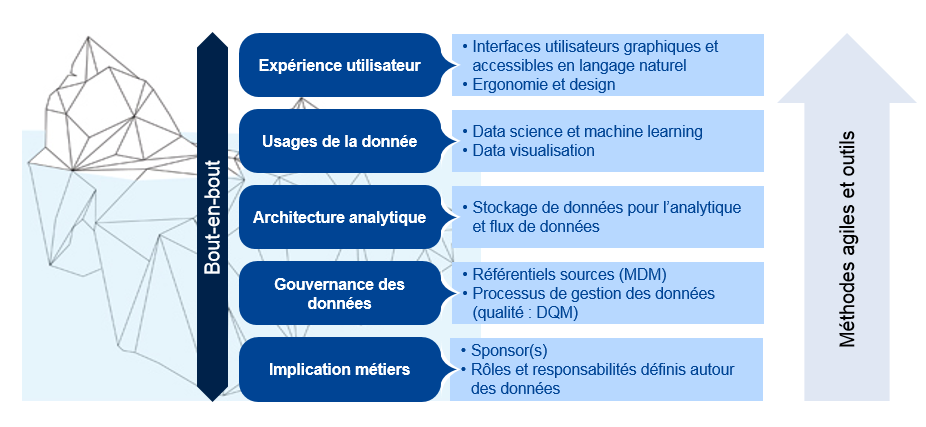
Figure 1. Approche de bout-en-bout des projets data (conception Total)
Cette approche de bout-en-bout est un gage d’aboutissement des projets data. Elle a été pensée car, dans de nombreuses entreprises, trop de ces projets ont échoué ces dernières années car cette prise en compte globale de toutes les problématiques est rarement observée. Au fil des modes, on a effectivement observé de nombreuses initiatives mortes-nées :
- La création de datalake sans données car sans usages métier
- La multiplication des POC (Proof Of Concepts) data science sans lendemain car l’industrialisation technique n’a pas été envisagée
- La rédaction de « chartes de gouvernance de la donnée » lues uniquement par leur comité de rédaction
TOTAL a engagé un plan de transformation Groupe sur l’ensemble de ces dimensions, avec une volonté de le nourrir d’une logique « test and learn ». En effet, pour qu’un tel plan reste opérationnel et aux services des métiers du Groupe, il n’est pas réaliste de vouloir le concevoir sans le confronter à la réalité du terrain aussi souvent que possible.
C’est pour cela que la Data Squad a été mise en place. Ce dispositif a un double objectif. D’une part, aider les projets data à réellement livrer des services en les aidant à avancer en tenant compte du projet dans toutes ses dimensions. D’autre part, contribuer à améliorer la filière data du Groupe en mettant les bonnes pratiques à l’épreuve du terrain, afin de nourrir le socle technique et méthodologique du Groupe.
Pour bien fonctionner et pour réellement intégrer toutes les dimensions dans une logique de passage en production, cet incubateur rassemble les principaux acteurs concernés par les sujets « data » (mécanisme destiné à faciliter le transfert de savoirs Azan et al. 2009, 2017) :
- L’entité « Digital Groupe » de la Direction de la Stratégie, dont le rôle est de piloter la transformation digitale de l’ensemble du Groupe TOTAL et de promouvoir les nouveaux usages ;
- L’entité « DSI Groupe », qui a pour mission de définir et mettre en œuvre un plan stratégique de transformation du SI TOTAL ;
- L’entité « TGITS », responsable des infrastructures et services informatiques du Groupe.
Ce fonctionnement tripartite a un double avantage. D’une part, il permet d’apporter un soutien global et multi-compétence aux projets, du cadrage à la mise en production. D’autre part, il permet aux entités Digital, DSI et TGITS de se synchroniser et d’ajuster mutuellement leurs stratégies. C’est un gage de réussite car, dans bien des entreprises, les entités digitales et informatiques sont plus concurrentes que partenaire, au détriment d’une stratégie cohérente et, évidemment, des utilisateurs finals.
A noter que la Data Squad n’est pas un centre de service : il accompagne plutôt des projets existants déjà portés par des équipes. Il les aide à effectuer un cadrage de bout-en-bout et leur apporte le conseil et la connaissance des bonnes pratiques et des outils Groupe, pour accompagner le développement des projets et leur passage en production. Le principe de la Data Squad est résumé ci-dessous :
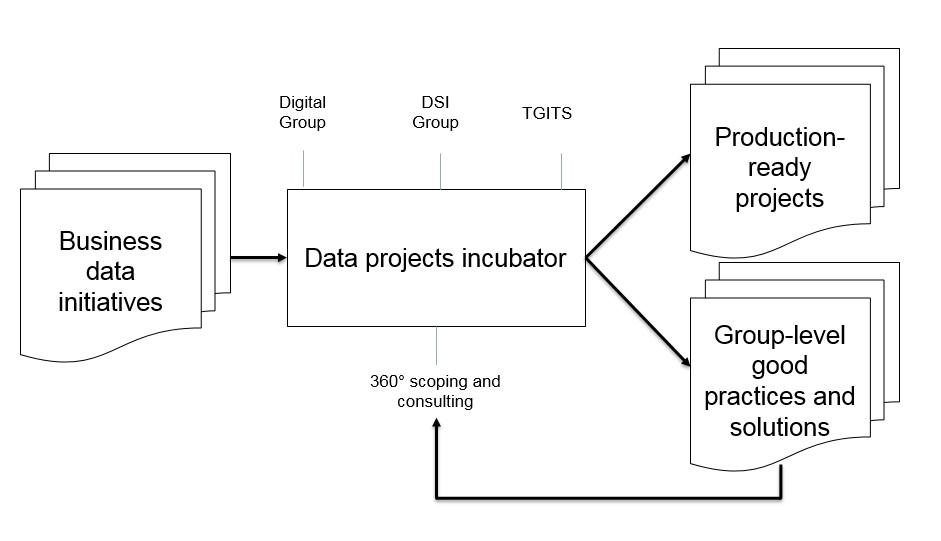
Figure 2. Principe de la Data Squad (conception Total).
Parmi les bonnes pratiques Groupe soutenues par la Data Squad, l’une d’entre elle nous paraît particulièrement originale et intéressante : le développement d’un environnement data science Groupe. Les équipes data science du Groupe sont actuellement décentralisées au sein des grandes branches de TOTAL, qui suivent les grands pans de l’activité du Groupe : EP (Exploration-Production), RC (Raffinage-Chimie), MS (Marketing et Services), GRP (Gaz, Electricité et Nouvelles Energies). Des data scientists sont également présents directement auprès des métiers et certains travaillent aussi pour les fonctions transverses du Groupe (R&D, Achats, RH…). L’objectif est de conserver cette proximité opérationnelle, tout en créant une communauté data science globale et développant des pratiques partagées au niveau du Groupe. C’est tout l’enjeu d’un environnement Groupe, qui permet :
- De faciliter la collaboration entre tous les data scientists, afin qu’ils puissent partager leurs codes et solutions, et qu’ils puissent gérer des projets collaboratifs sans être gênés par les silos organisationnels ;
- D’harmoniser les pratiques de data science industrielle: normes de développement, revue de code, mise en production et contrôle des modèles, etc.
Bien évidemment, l’incubateur permet de consolider des bonnes pratiques sur toutes les dimensions de la Fig. 1 : gestion des infrastructures de stockages, processus de data management, méthodologie de développement, etc.
Les difficultés des services informatiques selon Markus et la réponse apportée par Total
Pour L. Markus (2000) le rôle du service informatique est d’aider les entreprises à utiliser et gérer efficacement l’information et la technologie de l’information. L’efficacité du service lui-même dépend, d’une part, de sa constitution (son organisation, sa position et ses politiques ou ce que l’on pourrait appeler le « hardware ») et, d’autre part, de son mode de fonctionnement (ses procédures, sa culture et ses ressources humaines ou le « software »). Pour que le service soit performant, il faut que le « hardware » et le « software » soient en ligne avec les stratégies et la culture de l’entreprise.
Or, aujourd’hui, l’IT des grandes organisations n’est pas fait pour intégrer les pratiques liées à la data science. L’IT s’est organisée pour gérer des projets type SAP, avec des centres de service, des cycles en V, un objectif principal de réduction des coûts. La data science requiert de fortes compétences scientifiques, de l’agilité, de la proximité avec les métiers, de l’open source. De plus, on l’a vu, actionner la data science dans les organisations implique de traiter plusieurs autres sujets (gouvernance des données, etc.). Cette révolution des données fait suite à la révolution du cloud, pour autant les compétences dans les directions SI ont évolué moins rapidement.
Chez Total, la Data Squad vise à faciliter ce traitement de bout-en-bout des projets data. Il rassemble toutes les compétences au sein d’une équipe légère et flexible, pour pouvoir faire avancer rapidement les sujets accompagnés et s’attaquer si nécessaires aux problématiques techniques et méthodologiques nouvelles, en restant en étroite interaction avec les porteurs métiers.
Le problème posé par Markus et al. en 2000 est également pertinent dans le cas de TOTAL. Par exemple en ce qui concerne la gouvernance, plusieurs entités peuvent avoir le souhait de mettre en place des organisations, des processus spécifiques. Mais, si on laisse faire localement, on crée des silos. Or, tout l’enjeu d’une bonne gouvernance des données est notamment de favoriser le partage des données, ce qui justifie une approche globale. L’environnement data science partagé évoqué précédemment relève de la même logique. En fédérant les équipes, on créé une communauté data science on niveau du Groupe, rassemblée autour d’une culture et de pratiques communes. Plus généralement, le Data Squad Total a bien cet objectif de diffusion de bonnes pratiques partagées, en aidant un maximum de projets à passer en production.
La Data Squad dans le cas de Total introduit de l’agilité dans le système et de la proximité avec les métiers. L’objectif est de faire de l’informatique un réel allié pour faire avancer leurs projets data. Il est essentiel de motiver les métiers à travailler avec l’informatique sur ce sujet, car tôt ou tard, tout projet d’exploitation des données devient un sujet IT pour assurer le passage en production.
A l’opposé, en son temps L. Markus observait le « dysfonctionnement » des relations résultant de divergences de fond entre les points de vue des opérationnels, des informaticiens et des utilisateurs de l’informatique. Elle expliquait que « les informaticiens ont une mentalité d’ingénieur qui n’est guère partagée par ceux avec lesquels ils travaillent ». Markus en concluait qu’il fallait reprogrammer le logiciel du service informatique. En data science, la distinction entre pratiques informatiques et critiques de ces dernières aujourd’hui est loin d’être établie (Žliobaite and al. , 2016 ; Barocas and al., 2017). Pour cette dernière, le premier pas indispensable pour les spécialistes de l’informatique, c’est d’admettre la nécessité de changer. Et c’est là que les opérationnels peuvent être utiles en leur montrant de façon constructive quelles peuvent être les répercussions de leur comportement de spécialiste ainsi qu’en gérant patiemment toutes leurs réactions défensives par rapport à ces informations. Pour Zliobaite et al. (2016) au contraire les acteurs techniques et terrains dépassent aujourd’hui le champ possibles des critiques et des remises en question. Dans l’esprit de Markus, il s’agissait probablement d’aménager un espace entre logique projet (incubateur, squad), support informatique auprès des utilisateurs (agilité, approche bout en bout) et mise en germe de nouvelles idées (incubateur). A l’opposé, aujourd’hui, nombre d’auteurs dans leurs travaux récents plaident pour un recentrage autour de la machine (Cao, 2017), l’hypothèse d’un data brain ou encore d’une human like machine s’impose (Cao, 2015).
En conclusion, les dispositifs tels la Data Squad présentée dans cet article, centrée sur l’accélération des projets portés par les métiers en leur apportant des solutions complètes et opérationnelles sont une réponse possible à la relation IT / métier. Ce dispositif est un facteur organisationnel d’agilité des données au sein d’un grand groupe entreprise. Parallèlement l’approche développée bout-en-bout permet de s’assurer de la pérennité des projets, en évitant le simple « technology push ».
Bibliographie
Azan W. & Sutter I. (2010), Knowledge Transfer in Post-Merger Integration (PMI) Management, Case Study of a Multinational Healthcare Company in Greece, KMRP, 8, p. 307-321.
Azan W., J.P. Bootz, O. Rolland (2017), Community of Practices, knowledge transfer and ERP project (ERPP) Knowledge Management Research & Practice, (15) 54, pp 1-19.
Azan W., Ivanaj S. and Rolland O. (2018), Modular path customization and knowledge transfer: Causal model learnings, Technological forecast and social change, à paraître
Barocas S. and Boyd D. (2017), Computing Ethics, Engaging the Ethics of Data Science in Practice, Seeking more common ground between data scientists and their critics, communication of the ACM, NOVEMBER 2017 | VOL. 60, 9., 23-25.
Cao L.B. (2010), In-depth behavior understanding and use: The behavior informatics approach. Information Science 180, 17 (Sept. 2010), 3067–3085.Cao L.B. (2014), Non-IIDness learning in behavioral and social data. The Computer Journal 57, 9, 1358–1370.
Cao L.B. (2017), Data Science: Challenges and Directions, Communication of the ACM, 60, 8 COMMUNICATIONS OF THE ACM, 59-68.Cao, L.B. (2015), Metasynthetic Computing and Engineering of Complex Systems. Springer-Verlag, London, U.K., 2015.
Cao, L.B. (2016), Data science: Nature and pitfalls. IEEE Intelligent Systems, 31, 5, 66–75. Cao, L.B., Yu, P.S., and Kumar, V. ( 2015), Nonoccurring behavior analytics: A new area. IEEE Intelligent Systems 30, 6, 4–11.
Diggle, P.J. (2015), Statistics: A data science for the 21st century. Journal of the Royal Statistical Society: Series A (Statistics in Society) 178, 4 (Oct. 2015), 793–813. Donoho, D. 50 Years of Data Science. Computer Science and Artificial Intelligence Laboratory, MIT, Cambridge, MA, 2015; http://courses.csail.mit. edu/18.337/2015/docs/50YearsDataScience.pdf
Lutz M., Boucher X. (2016), Data driven decision-making for IT capacity : beyond statistical analysis, Journal of Decision System, vol. 26, issue 1., pp. 1-24
Markus, L, Cornelis Tanis, Paul C. van Fenema (2000), Enterprise resource planning: multisite ERP implementations, Communications of the ACM, Vol. 43 No. 4, Pages 42-46.
Matsudaira, K. (2015), The science of managing data science. Commun. ACM 58, 6 , 44–47Prasanna Tambe (2014), Big Data Investment, Skills, and Firm Value, Vol. 60, iss. 6, Management science, p. 1452-1469
Reix R. (2011), Management des SI et organization, dirigé par M. Kalika, B. Fallery et F. Rowe Vuibert, Paris
Zablah, Alex R, Danny N Bellenger, Detmar W Straub, and Wesley J Johnston (2012), “Performance Implications of CRM Technology Use : A Multilevel Field Study of Business Customers and Their Providers in the Telecommunications Industry.” Information Systems Research 23(2): 418–35.
Žliobaite’, I. and Custers, B. (2016), Using sensitive personal data may be necessary for avoiding discrimination in data-driven decision models, Artificial Intelligence and Law 24, 2, 183–201
il ne peut pas avoir d'altmétriques.)