
Citation
Les auteurs
Jean-Baptiste Igonetti
(jbigonetti@lieutenantconsultants.fr) - Doctorant en Sciences de GestionStéphane Chauvin
(stephane.chauvin@mydataball.com) - MyDataBall
Copyright
Déclaration d'intérêts
Financements
Aperçu
Contenu
Réunir compétence et performance : le savoir-agir
Identifier les compétences et les valoriser demeurent un exercice ardu au sein de l’entreprise. Si celle-ci se doit légalement de garantir l’employabilité de ses collaborateurs, la nature des compétences mobilisées repose sur des arbitrages à portée essentiellement stratégique, généralement assez éloignés des fiches de postes dont la teneur n’est par ailleurs pas toujours en rapport avec la nature de la mission exercée.
L’entreprise n’est pas cloisonnée, elle est un modèle ouvert sur le monde, elle se nourrit d’elle-même et alimente une mémoire expérientielle. Celle-ci apparaît difficilement quantifiable, mesurable, et pose la question de la transformation utile de l’expérience à la source de création de savoir dans le processus d’apprentissage. Ajoutons enfin que l’efficacité organisationnelle, comme mesure du couple compétence/performance, apparaît en filigranes dans le concept de rapport au savoir. L’apprentissage organisationnel possède un rôle plus que déterminant dans le processus d’élaboration d’une stratégie d’entreprise structurante. A tout le moins, une plus grande « rationalité subjective » permet à l’individu de manifester une intelligence pratique relative à l’objet transactionnel (par exemple la conquête de nouveaux marchés), donc une plus grande motivation, en fonction de laquelle se déploie l’inventivité du faire à l’œuvre, et donc sa créativité. Le capital intellectuel représente un ensemble de ressources endogènes (compétence, savoir-faire, etc.) et de ressources externalisables (marques, réputation, satisfaction des consommateurs, etc.) permettant de créer de la valeur pour l’ensemble des parties prenantes par la recherche d’avantages compétitifs (Lacroix et Zambon, 2002). Savall et Zardet (cité par Cappelletti, 2010) définissent l’investissement immatériel comme « un ensemble de mini actions individualisées ou collectives qui convergent vers la réalisation des objectifs stratégiques de l’entreprise ».
Pour mieux répondre au problème posé, il nous faut introduire la notion du « savoir-agir », considéré ici comme la faculté d’agir avec compétence. Au sens économique, c’est une capacité à obtenir un résultat. Ce résultat doit être éminemment tangible, observable et mesurable et ne peut-être décorrélé de la notion de performance organisationnelle. Rappelons que les comportements motivés conduisent à la performance et que les croyances et les valeurs ont un impact réel sur la motivation et la performance (Thill et Vallerand, 1993). Pour faire face à un événement, un salarié doit être en mesure de sélectionner et mobiliser des ressources mais aussi de savoir les analyser et les organiser, et construire ainsi une combinatoire de plusieurs ingrédients. L’appel à des capacités qui mobilisent des capacités cognitives, connaissances et aptitudes entrent ici dans le champ exploratoire du savoir-agir. De surcroît, coexistent dans le schéma organisationnel des entreprises, des us et coutumes à la périphérie des fiches de postes, qui mettent en jeu des salariés référents, encouragent à la polyvalence et à la poly-compétence, sans qu’il existe pour autant un référentiel officiel traduisant ces comportements motivés.
Sur un plan plus théorique, rappelons que selon Dodgson (1993), une organisation apprenante est une entreprise qui construit des structures et des stratégies afin d’accroître et de maximiser l’apprentissage organisationnel. Selon Huber (1991), un apprentissage est organisationnel dès lors que l’acquisition d’un savoir, même individuel, modifie le comportement de l’entité (Koening, 2006).
A l’heure actuelle, très peu d’outils de gestion permettent d’envisager de vraies stratégies à 360° qui tiennent compte des inférences nées de la mise en correspondance des éléments du savoir-agir. Il leur est très difficile de déceler les signaux faibles ou autres correspondances tacites entre ce qui est référent et ce qui est référé dans l’expérience organisationnelle. Enfin, ils ne peuvent dire avec exactitude où se situe la frontière entre le vécu informel du salarié et la performance relative en rapport avec ce savoir né de l’expérience. Il devient de plus en plus important d’intégrer de nouveaux outils de mesure au service des entreprises.
L’approche des auteurs : Cet article vise démontrer le caractère très subjectif du traitement des données humaines complexes à l’endroit des outils de gestion actuels. L’hypothèse retenue est confirmée par l’apport des outils de traitement de masses de données (ou Big Data) capables de collecter des données brutes, de les enrichir et de les nettoyer en vue de générer des données nettes, utiles et mesurables afin de mieux appréhender la composante humaine de la performance et de la compétence. Les résultats obtenus sont tangibles et se confrontent au cadre théorique selon lequel les actuels outils de gestion actuels restent peu efficients. La collecte des données a permis notamment de mesurer l’info-obésité. Un accroissement de combinaisons possibles des données est vertigineux lorsque l’entreprise multiplie les initiatives de mesurer son activité. Une solution technique issue d’algorithmes et de présentations des résultats est proposée comme une alternative.
Repenser la gestion des compétences dans l’entreprise
Les travaux de Bureau et Igalens (2008) dressent un état de l’art des principales missions de gestion prévisionnelle en Gestion des Relations Humaines (GRH) : il s’agit de la gestion anticipée des emplois et des compétences, de la gestion préventive, de la gestion anticipatrice, de la gestion anticipative, de la gestion prospective, de la gestion prévisionnelle de l’emploi et des compétences et la gestion prévisionnelle des ressources humaines.
Les nouveaux outils de gestion ne doivent pas uniquement analyser, mais adopter une démarche itérative, prédictive, orientée business analytics et intelligence. Pour Scouarnec (2002), il s’agit de l’anticipation, même imparfaite, des changements, des discontinuités, des éventualités. L’objectif n’est pas de décrire l’état futur le plus probable mais d’élaborer différents cheminements ou développements plausibles compte tenu des degrés de liberté des acteurs en jeu. Il arrive souvent que les salariés et les utilisateurs perçoivent le système d’information RH (SIRH) comme une déshumanisation des ressources humaines. En réalité, rien ne permet de garantir une permanence de l’efficacité transactionnelle d’un tel outil à destination de l’utilisateur final d’autant que le workflow suppose une bonne indexation des données à destination des utilisateurs finaux (les métiers notamment).
Plusieurs enjeux cruciaux se dégagent ici : un enjeu social et individuel, un enjeu économique et un enjeu organisationnel. A titre de comparaison, si un des enjeux de la conformité bancaire et financière est la bonne connaissance du client (le Know Your Customer), il apparait ici primordial de bien connaitre son collaborateur et introduire le concept de KYE : Know Your Employee. A cette échelle de réflexion, nous voyons bien que la plupart des outils de gestion qui n’intègrent pas, en temps réel, l’ensemble de ces grands enjeux, ne favorisent pas l’émergence d’une nouvelle pensée comme élément indispensable permettant de partir de l’expérience réelle de l’utilisateur et de favoriser la performance créative sans barrière.
La contrainte de l’info-obésité
Les outils de gestion des entreprises rassurent mais ne suffisent plus. Le nombre d’indicateurs produit est en forte croissance. La restitution des informations est de plus en plus complexe. Dans certaines entités, le rejet des tableaux de bord et de la mesure sont manifestes. Cette indigestion de la consommation d’information et de données est l’info-obésité proprement dite.
Ainsi, l’entreprise, confrontée à une croissance du nombre d’outils logiciel intégrant les données d’activité et l’ajout des mesures d’activités extérieures à l’entreprise, suppose que sa capacité à appréhender cette masse d’information grandisse. Or, si on regarde l’énergie déployée à l’intégration, la consolidation / réconciliation (éliminer les silos de données), la manipulation, l’extraction, l’analyse et la détection de diagnostics, il est probable que dans de nombreux cas, le retour sur investissement de la data soit faible voire négatif.
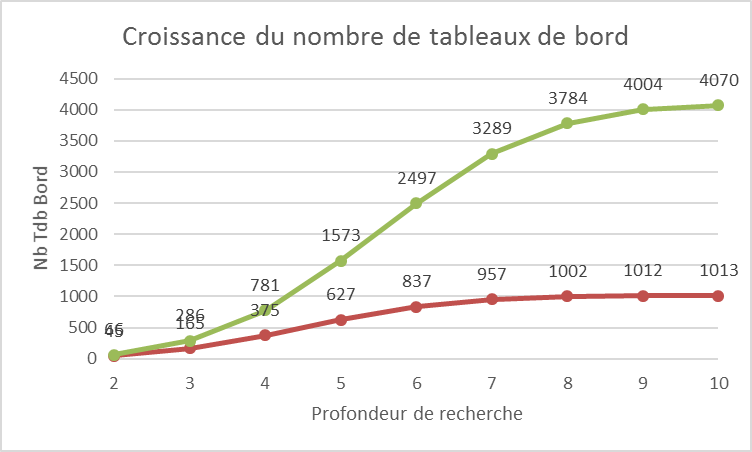
De nombreux cas apparaissent sur le marché où des institutions développent un nombre impressionnant de mesures faites. Par exemple, il n’est plus rare de voir plusieurs centaines d’indicateurs voire des milliers qui qualifient un client et son parcours dans l’enseigne. Alors, par simple calcul combinatoire, il en ressort que pour 10 axes d’analyse, 45 tableaux de bord sont possibles. Ils sont à consulter de manière hebdomadaire. L’énergie à dépenser pour lire, comprendre et appréhender un diagnostic croît exponentiellement avec le nombre de mesures faites dans les organisations.
Le tableau 1 montre le nombre de tableaux de bord à réaliser pour comprendre les événements si on veut être sûr de maîtriser son environnement et en détecter les connaissances utiles. En présence de 12 axes d’analyse dans sa connaissance client, 781 tableaux de bord de profondeur maximum de 4 sont nécessaires pour comprendre le phénomène.
Tableau 1 : Une mesure de l’info-obésité
Nombre de tableaux de bord en fonction de la profondeur de l’analyse (abscisses) en présence de 10 axes d’analyse (en rouge) et de 12 axes d’analyse (en vert). Cet accroissement de combinaisons possibles des données est vertigineux lorsque l’entreprise multiplie les initiatives de mesurer son activité.
Prenons l’exemple d’un cas RH traité. Il donnait un patrimoine de 17 variables qualifiant les collaborateurs et utilisées pour détecter les raisons de mal-être, d’agir sur la formation et la prévention de maladie longue. Ce problème nécessiterait la création de 109 276 croisements pour comprendre les éléments explicatifs de mal-être. Les solutions classiques de gestion ne résolvent pas cet aspect ultra combinatoire et font échouer les travaux des RH dans la recherche d’amélioration de la performance. Il s’agit d’utiliser de nouvelles solutions.
L’enjeu de pouvoir trier et organiser les flots de données selon une certaine justesse est primordiale. Il s’agit de définir la mécanique organisationnelle et des compétences autour de la capacité à intégrer les connaissances découvertes dans la donnée et de les restituer de manière efficace et de qualité pour la performance des collaborateurs et de l’entreprise tout en gérant l’aspect combinatoire ci-dessus illustré.
Les méthodes et les techniques de Knowledge Management innovantes sont à mettre à profit. Elle repose sur la capacité à partager des synthèses d’information, en lutte contre le trop plein d’information (Edvinsson et Sullivan, 1996). Cela induit aussi une ergonomie adaptée du système de traitement des données capable de traduire dans un langage simple et accessible par l’utilisateur, l’ensemble des éléments de réponse. Il apparaît in fine primordial de créer de nouveaux processus de prise de décision pour de nouveaux usages.
Trier l’information pour faire progresser les visions anticipatrices et prospectivistes dans l’entreprise
Dans le cadre de l’entreprise, il est notoire que le tsunami du Big Data perturbe les habitudes des processus de fabrication et de communication. Le dilemme est donc d’être capable d’ingurgiter de plus en plus d’information (le temps de travail en est même perturbé), de confronter les compétences des métiers dans la capacité à trier et organiser l’information. Les phénomènes actuels dans les entreprises sont que les documents qui restituent l’information sont d’une part très numériques (voire que chiffrés) et que l’appropriation de la donnée brute est complexe. Les générations partantes sont impactées, créant un malaise d’entreprise. Les générations arrivantes ne se gênent pas, pour aller vite, à faire des raccourcis de connaissance. Le coût de transformation de la donnée en connaissance, au sens économique du terme, est exorbitant : la chaine de production de la donnée est laborieuse, longue, nécessitant des moyens techniques et humains de plus en plus importants. A tous les niveaux, depuis sa gouvernance jusqu’aux tâches opérationnelles, l’entreprise s’en trouve mutée dans une gestion de la bonne connaissance.
Pour surpasser toutes ces difficultés, il est nécessaire 1) de créer des mesures (augmenter le patrimoine numérique mais également augmenter la difficulté à la gérer), 2) de réconcilier les données des outils de gestion (data lake, infocentre, datawarehouse), 3) de donner les moyens d’interroger dans les multiples dimensionnalités tout le patrimoine numérique. Ici, se concentrent les techniques cognitives, d’ergonomie et de data visualisation (Chauvin, 2012).
Le goût pour la mesure ne se dément pas : on mesure davantage pour mieux optimiser les compréhensions. Alors, pour libérer les énergies des collaborateurs, il est nécessaire de leur donner les moyens de mesurer, de rester agile à la création de nouvelles mesures.
L’approche de la data analytics, et notamment par les outils d’arborescence, comme leviers pour trier et organiser les informations selon un principe d’ « universalité » permet de répondre aux enjeux ci-dessus décrits. Le calcul industriel élimine l’aspect combinatoire mentionné plus haut. La visualisation de ces outils statistiques et mathématiques de calcul des informations a des vertus de partage de diagnostics et de connaissance. Les notions de copules mathématiques (conjonctions, disjonctions, moyennes) sont des outils techniques qui permettent à la pédagogie de créer un levier d’apprentissage fort et profond (aspects multidimensionnels de la connaissance chers au sociologue Edgar Morin).
Dans ce cadre-là, on peut envisager sereinement de permettre aux collaborateurs d’exploiter l’ensemble des données et d’en produire de nouvelles, de devenir des « data scientists » qui créent des systèmes de tris de l’information que tous ses collègues peuvent s’approprier. De cette manière, le partage de connaissance s’opère en empilant les recherches et les questions sur les données grâce aux personnes des métiers : suivi des intuitions jusqu’à la création de connaissance (i.e. détection de diagnostics à ROI : ce qui fait la différence et la valeur de l’entreprise par rapport au concurrent).
Le « Knowledge Management » adossé au « Knowledge Discovery » permet de capitaliser sur les connaissances intuitives des collaborateurs et de construire l’entreprise sur le partage des connaissances.
Dans une perspective de délivrance de la connaissance en réseau et de son optimalité, la question des outils de Big Data nous amène à aborder la question de l’interopérabilité entre le modèle qui délivre et l’apprenant qui reçoit et qui retraite l’information, donc de cette capacité inhérente à s’approprier et à retraiter l’information dans un collectif de travail qui s’autoalimente.
« L’intelligence collective rencontre deux limites naturelles : – le numérique : seul un nombre limité de personnes peut interagir efficacement, sans quoi on atteint vite un niveau trop élevé de complexité qui génère plus de « bruits » que de résultats effectifs, ce qui limite les capacités du groupe; – la dimension spatiale : les personnes doivent se trouver dans un environnement proche afin que leurs interfaces naturelles (sens organique) puissent échanger entre elle, afin que chacun puisse appréhender la globalité de ce qui se passe (holoptisme) et adapter son comportement en fonction ». (Noubel, 2004).
Aussi, peut-on formuler l’hypothèse que le Big Data, participant au tri des données, amène une réponse nouvelle et intéressante en termes d’efficacité organisationnelle. A tout le moins, il ouvre un champ des possibles de la sérendipité. Aussi, nous parait-il indispensable de répondre à la question de la complexité posée par l’utilisation d’un système de traitement de masses de données dans un environnement où l’instabilité créatrice (en termes de structuration de la pensée et du rapport au savoir) demeure comme une composante épistémologique de la réussite organisationnelle du projet entrepreneurial.
Le Big Data promeut une méthode en amont, permettant de catalyser plusieurs informations, bien au-delà des 10 variables que le cerveau humain est en mesure de traiter en même temps, et promet d’analyser par la suite les arbres décisionnels permettant de nourrir l’information utile à l’entreprise (Desarathy, 1994). En ce sens, il peut être un outil pertinent pour mesurer avec justesse les connexions (ou nœuds) existantes, structurantes et différenciantes au sein d’une communauté de travail. Mais il pose inéluctablement la question de la qualification des personnes et des capteurs humains à récupérer les données, se les approprier et à les indexer, mettant en exergue une sorte l’illettrisme technique et numérique. Mieux formaliser l’interprétation des besoins utilisateurs via le schéma analytique et prédictif du Big Data, c’est offrir une puissance de discernement qui contribue à une meilleure compréhension d’un système dans sa totalité, pour en comprendre les parties, et inversement, comprendre toutes les parties pour en saisir le fonctionnement du tout.
Partant du principe qu’un ensemble de données est une phrase, un énoncé, un prédicat, les outils de Big Data peuvent aussi apporter une analyse intéressante située au niveau pré-comportemental des individus : formuler des hypothèses tangibles quant aux processus de construction des groupes sociaux, amener à une réflexion en miroir de l’organisation apprenante – lui conférant un objectif déterminé et stable d’apprentissage consistant à étudier les valeurs et les cultures préexistantes pour bien mener les projets de l’entreprise au but espéré (Norman, 2002) – et produire de la performance. Les outils de Big Data pourraient ainsi apparaître comme des outils ergonomiques bien adaptés à ces entreprises innovantes, même si la perspective ergonomique dans son ensemble n’est pas « située » par nature, mais fournit néanmoins un terrain très adéquat pour tester les hypothèses de la cognition située (Grison, 2004).
Conclusion
Dans cet article, les méthodes abordées visent à rendre agile la création de mesures (une nécessité pour mieux comprendre nos environnements de décision), à traiter les aspects chronophages et combinatoires de la détection de connaissances dans de multiples sources de données et d’information (notamment par l’approche de calcul d’arborescences et de visualisation) et à capitaliser sur les collaborateurs qui se poseront des questions individuellement. Il s’agit de consolider l’information dans un second temps entre des métiers : une nouvelle méthode de knowledge management par le Knowledge Discovery.
On s’efforce aussi à démontrer que le levier de la connaissance et du partage de la connaissance peut être la possibilité d’extraire et de capitaliser sur les événements par le numérique. Nous proposons une méthode et une technicité sur la base de combinaisons d’arborescences qui peut réduire voire éliminer les effets néfastes de la surconsommation de données et d’information par les approches de combinaisons et mises en relation des connaissances.
Nous notons le caractère particulier d’une communauté de pratiques innovantes qui se construit sur la base d’une autorégulation des compétences, où le partage de la connaissance ne repose pas sur des référentiels prédéterminés, où tous les acteurs participent à l’expérience de l’apprentissage organisationnel dans un savoir-agir mesuré et assumé.
Enfin, nous expliquons en quoi les outils de Big Data confèrent un objectif déterminé et stable d’apprentissage consistant à étudier les valeurs et les cultures préexistantes pour bien mener les projets de l’entreprise au but espéré, la mesure de l’immatériel semblant être le Graal. Au-delà des outils actuels des outils de gestion des ressources humaines ou des tableurs Excel qui représentent chacun un univers donné, les outils de gestion de demain devront rapidement permettre l’enrichissement de la donnée utile et agile à l’entreprise.
Bibliographie
- Bureau, S., & Igalens, J. (2008). La professionnalisation: une nouvelle approche de la GPEC (No. hal-00263296)
- Cappelletti, L. (2010). Vers un modèle socio-économique de mesure du capital humain?. Revue française de gestion, (8), 139-152.
- Chauvin, S. (2014). Data Visualisation. Colloque du Groupement de Recherche sur la Complexité.
- Chauvin S. et Molendi P. (2012). Des outils pour mieux piloter l’entreprise, revue Echanges, n° 298.
- Chauvin, S., & Molendi, P. (2002). Des outils pour mieux piloter l’entreprise, revue Echanges, 298.
- Chauvin, S. (1994). Decision Theory Evaluation For Fusion, Data Fusion Meeting CNRS.
- Dasarathy, B. V. (1994). Decision fusion (Vol. 1994). Los Alamitos, CA: IEEE Computer Society Press.
- Dodgson, M. (1993). Organizational learning: a review of some literatures. Organization studies, 14(3), 375-394.
- Edvinsson, L., & Sullivan, P. (1996). Developing a model for managing intellectual capital. European management journal, 14(4), 356-364.
- Gadille, M., & Machado, J. (2010). La formation dans les PME d’un pôle, rapports au savoir et division du travail. Éducation permanente, (182), 107-121.
- Grison, B. (2004). Des sciences sociales à l’anthropologie cognitive. Les généalogies de la cognition située. Activités, 1(1-2).
- Hinds, P. J., & Pfeffer, J. (2003). Why organizations don’t “know what they know”: Cognitive and motivational factors affecting the transfer of expertise. Sharing expertise: Beyond knowledge management, 3-26.
- Huber, G. P. (1991). Organizational learning: The contributing processes and the literatures. Organization science, 2(1), 88-115.
- Koenig, G. (2006). L’apprentissage organisationnel: repérage des lieux. Revue française de gestion, (1), 293-306.
- Lacroix, M., & Zambon, S. (2002). Capital intellectuel et création de valeur: une lecture conceptuelle des pratiques française et italienne. Comptabilité-Contrôle-Audit, 8(3), 61-83.
- Noubel, J. F. (2004). Intelligence collective, la révolution invisible. TheTransitioner, publié en novembre.
- Norman, D. (2002). Emotion & design: attractive things work better. interactions, 9(4), 36-42.
- Scouarnec, A. (2002). Vers la création d’un observatoire des métiers du marketing. Revue française de gestion, (140), 169-186.
- Thill, E., & Vallerand, R. J. (1993). Introduction à la psychologie de la motivation. [Laval, Québec]: Éditions Études vivantes.
il ne peut pas avoir d'altmétriques.)