Résumé
Les techniques de fraude ne cessent d'évoluer et obligent les dispositifs de lutte anti-fraude à s'adapter. Le recours à l'intelligence artificielle donne naissance à de nouvelles approches plus innovantes fondées sur des algorithmes et des technologies Big Data. Il existe de nombreux défis technologiques et scientifiques ; notamment, comment trouver les meilleurs modèles de classification en prenant en compte le problème de déséquilibre des classes (Imbalanced Classification). Dans cet article, nous testons les modèles de Machine Learning (ML) et de Deep Learning (DL) pour la détection de la fraude. Nous analysons particulièrement les approches de classification déséquilibrée.Citation : Hamitouche, T. (Mar 2023). L’Intelligence Artificielle au service de la lutte contre la fraude à la carte bancaire. Management et Datascience, 7(2). https://doi.org/10.36863/mds.a.23220. L'auteur : Copyright : © 2023 l'auteur. Publication sous licence Creative Commons CC BY-ND. Liens d'intérêts : Financement : Texte complet
Introduction
Afin de réagir au plus vite, les entreprises investissent de plus en plus dans des mécanismes permettant de détecter la fraude bancaire. Cette démarche doit être conforme à la règlementation, qui exige aujourd’hui aux établissements financiers d’aller au-delà de l’authentification, et ce, en étant proactif face à des événements suspicieux ou frauduleux. En effet, face à la complexité et à la diversité des attaques, les techniques de détection évoluent et s’orientent vers une exploitation plus poussée des données. C’est dans ce contexte qu’est née la détection de la fraude avec l’IA, plus précisément, des techniques de Machine Learning (ML) et de Deep Learning (DL).
Plusieurs problèmes liés à la fraude à la carte bancaire ont été décrits dans la littérature. Cependant, le problème de déséquilibre des classes est considéré comme l’un des défis les plus critiques. Il s’agit de situation dans laquelle les proportions des différentes classes dans un jeu de données ne sont pas strictement identiques. Ce problème reste, à notre connaissance, non résolu malgré les nombreuses propositions de solutions basées sur des algorithmes de ML. Il est donc nécessaire d’identifier les faiblesses des approches existantes qui doivent être résolues pour produire une solution efficace.
D’autre part, ces dernières années, les approches de DL ont gagné une attention particulière en raison de leurs résultats satisfaisants dans diverses applications, telles que le traitement du langage naturel et de la voix, la vision par ordinateur, etc. Néanmoins, seules quelques études ont examiné l’application des réseaux neuronaux profonds dans l’identification de la fraude. L’enjeu est donc d’appliquer des algorithmes de DL pour détecter la fraude et procéder à une analyse comparative avec les algorithmes de ML.
Objectifs
Ce travail est orienté selon cinq principaux objectifs :
- Comparer six modèles de ML présentés dans la littérature, pour la détection et la classification de la fraude.
- Sélectionner les trois modèles de ML les plus efficaces en fonction des mesures de performance et appliquer les approches de déséquilibre des classes.
- Comparer trois architectures d’un modèle de DL pour la détection et la classification de la fraude et appliquer une approche de déséquilibre des classes.
- Effectuer une analyse comparative entre les modèles de ML vs DL.
- Étudier la valeur ajoutée des approches de classification déséquilibrée par rapport aux méthodes de classification classiques.
Algorithmes de ML pour la classification
K-Nearest Neighbors (KNN)
KNN consiste à trouver les K points les plus proches de celui qu’on veut prédire. Une norme spécifique est utilisée pour mesurer la distance entre les points. La nouvelle observation est assignée à la classe avec la majorité des K points les plus proches (majority voting) (MAKKI et al., 2019). En général, la norme utilisée pour mesurer la distance entre deux observations p et q dans Rn est la distance euclidienne donnée par :
d(p,q) = √∑(pi – qi)²
Logistic Regression (LR)
LR est un type de modèle linéaire généralisé. En effet, la régression linéaire classique ne convient pas lorsque la variable à prédire est binaire (MAKKI et al., 2019). Soient α = (α0, α1,.α2.., αn ) le vecteur des coefficients, X = (1,X1,X2,… Xn) le vecteur représentant les variables indépendantes et ε l’erreur du modèle. Le modèle linéaire est défini comme suit :
Y = α0 + α1X1 + α2X2 + … + αnXn + ε
En régression logistique, une fonction de liaison logit g est introduite (logit link function) g(p)= Xα, p étant la probabilité que l’observation appartiennent à la classe fraude.
g(p) = ln (p/(1-p)) avec p = eXα/(1+eXα)
Support Vector Machine (SVM)
SVM est un outil de classification qui vise à trouver l’hyperplan qui sépare de façon optimale les données de deux classes (data points). Formellement, soient un vecteur d’apprentissage donné dans Rn avec i = 1, 2, .., l
n le nombre de variables exploratoires et l le nombre d’observations dans le training set. y ∈ Rl prenant les valeurs 1 et -1.
La classification binaire est effectuée en résolvant le problème d’optimisation suivant :
minimiser ½||W||² + C ∑ ζi
tel que yi x (wT Φ(xi) + b) ≥ 1 – ζi avec ζi ≥ 0 et i = 1,, 2, …l
L’équation de l’hyperplan est définie comme suit wT Φ(xi) + b, où w est un vecteur de poids, Φ(xi) représente xi dans un espace de plus haute dimension. ζi sont ajoutés pour tenir compte de certaines erreurs ou mauvais calculs dans le cas où ces points ne seraient pas linéairement séparables. C’est un paramètre de coût > 0 associé à ces erreurs. La minimisation de ½||W||² revient à maximiser la distance entre les deux marges de l’hyperplan qui est égale à 2/||W||² afin de trouver l’hyperplan le plus optimal qui sépare les deux classes.
Naïve Bayes (NB)
NB utilise la règle de probabilité conditionnelle de Bayes pour la classification. Cette méthode consiste à trouver une classe à la nouvelle observation qui maximise sa probabilité étant donné les valeurs des variables. Notre objectif est de trouver la valeur de Y qui maximise P(Y / X1, X2, …, Xn) en utilisant le théorème de Bayes :
P(Y / X1, X2, …, Xn) = (P(X1, X2, …, Xn / Y)P(Y)) / P(X1, X2, …, Xn)
Maximiser P(Y / X1, X2, …, Xn) revient à maximiser maximiser P(X1, X2, …, Xn / Y). Ceci peut facilement être estimé à partir des données historiques, et ce, en supposant « naïvement » que les variables soient deux à deux indépendantes. Or, cette hypothèse n’est pas toujours satisfaite (MAKKI et al., 2019).
P(X1, X2, …, Xn / Y) = P(X1 /Y)P(X2 /Y)…P(Xn /Y)
Random Forest (RF)
RF est une méthode d’ensemble (ensemble method) qui utilise un arbre de décision (decision tree) comme estimateur de base. Dans RF, chaque estimateur de base est formé sur un échantillon différent (bootsrap sample) ayant la même taille que le training set. RF introduit une plus grande randomisation que le bagging (boostrap aggregation) lors de l’entrainement de chaque estimateur de base. Lorsque chaque arbre est formé, seules d caractéristiques peuvent être échantillonnées à chaque nœud sans remplacement (d < nombre total de caractéristiques). Les prédictions sont faites sur de nouvelles instances et collectées ensuite par le méta modèle RF. La prédiction finale est déterminée par la technique de vote (majority voting) pour les problèmes de classification.
Extreme Gradient Boosting (XGBoost)
XGBoost est un algorithme de boosting très populaire basé sur les arbres de décision (gradian boosted trees). Le boosting fait référence à une méthode d’ensemble (ensemble method) dans laquelle plusieurs modèles sont formés séquentiellement, chaque modèle apprend des erreurs de ses prédécesseurs. XGBoost s’optimise alors automatiquement pour produire les meilleures prédictions possibles.
Algorithmes de DL pour la classification
Artificial Neural Network (ANN)
ANN est une connexion de plusieurs neurones artificiels. Le réseau multicouche feed-forward est constitué de plusieurs couches : une couche d’entrée (input layer), une ou plusieurs couches cachées (hidden layers) et une couche de sortie (output layer). La première couche contient les nœuds d’entrée qui représentent les variables exploratoires. Ces entrées sont multipliées par un poids spécifique et transférés à chacun des nœuds de la couche cachée où elles sont additionnées avec un certain biais. Une fonction d’activation est ensuite appliquée à cette somme pour produire la sortie du neurone, qui sera transférée à la couche suivante. Enfin, la couche de sortie fournit la réponse de l’algorithme. Les poids utilisés sont d’abord fixés de manière aléatoire, puis, en utilisant le training set, ces poids sont ajustés pour minimiser l’erreur grâce à des algorithmes spécifiques comme la rétropropagation (backpropagation).
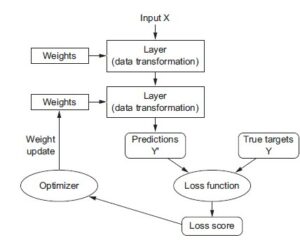
Figure 1 : Fonctionnement du réseau de neurones artificiel avec rétropropagation (COLLET, 2018)
Imbalanced classification
Random Oversampling (RO)
RO est utilisé pour équilibrer les classes en dupliquant les observations autant que nécessaire jusqu’à ce que l’équilibre entre les classes soit atteint. L’idée est de modifier le comportement du modèle de classification pour se concentrer sur la classe minoritaire (fraude) et la classe majoritaire (non-fraude) de manière égale (MAKKI et al., 2019).
One-Class Classification (OCC)
Cette approche n’utilise qu’une seule classe de données (généralement la classe minoritaire) et apprend ses caractéristiques (MAKKI et al., 2019). Dans notre cas, la classification a lieu dans la phase de test. Après avoir entraîné l’algorithme avec une seule classe, il devrait être capable de déterminer si une certaine transaction appartient à la classe minoritaire ou non.
Cost-Sensitive (CS)
L’idée de base derrière les modèles sensibles aux coûts (CS) est d’attribuer un poids plus élevé à la classe minoritaire. Cela revient à spécifier un coût plus élevé pour classer à tort un cas de fraude (MAKKI et al., 2019).
Méthodologie
Collecte des données
Nous avons utilisé le dataset « Credit Card [1]» accessible à des fins de recherche (492 fraudes sur 284 807 transactions).

Préparation des données
Avant de passer à la modélisation, nous avons exploité le dateset afin d’optimiser les capacités des modèles à prédire (types, valeurs aberrantes, valeurs Null, etc). Nous avons décrit les différentes variables pour avoir un ordre d’idée sur la distribution des valeurs.

Afin de travailler avec des variables sur la même échelle, nous les avons normalisées à l’aide d’un StandardScaler. La formule est : z = (x – u)/s (avec z la nouvelle variable, x l’ancienne, u la moyenne et s l’écart type).
Modélisation
Tous les modèles ML sélectionnés ont été implémentés, ensuite entrainés et testés sur le training set et le test set respectivement : KNN, LR, SVM, NB, RF et XGBoost.
Nous avons également implémenté un modèle de DL : ANN. Un type de réseau qui donne de bons résultats sur un tel problème est une simple pile de couches entièrement connectées (dense) avec des fonctions d’activation. Nous avons opté pour trois couches : une couche d’entrée (Dense(16*i, activation=’relu’)), une couche cachée (Dense(16*i, activation=’relu’)) et une couche de sortie (Dense(1, activation=’sigmoid’)) tel que i {1,2,4}. L’argument passé à chaque couche Dense(16*i) est le nombre de neurones ou unités cachées dans la couche (hidden units).
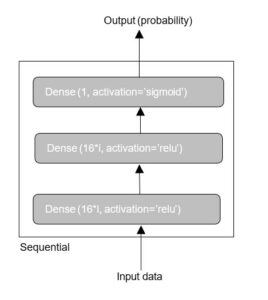
Les trois techniques de déséquilibre des classes ont été implémentées : RO, OCC et CS.
Trois mesures ont été sélectionnées : Accuracy, Recall et AUPRC (Area Under Precision Recall Curve).
Résultats
Evaluation des modèles ML
De tous ces algorithmes, l’algorithme KNN, SVM et RF sont les plus appropriés pour être utilisés dans l’évaluation des techniques de classification déséquilibrée. En effet, les deux raisons principales sont :
- KNN, SVM et RF ont produit des résultats équilibrés et plus satisfaisants dans les trois mesures (Accuracy, Recall et AUPRC).
- Ces trois algorithmes ne sont pas limités par des hypothèses mathématiques ou statistiques.

Evaluation des trois modèles ML avec les approches de classification déséquilibrée
- Accuracy de toutes les méthodes est supérieure à 99% avec des taux différents de Recall, sauf pour OCC SVM et Isolation Forest.
- Selon l’AUPRC, les méthodes originales (KNN, SVM et RF) sont plus performantes que celles utilisant des approches de classification déséquilibrée.
- Les résultats montrent, dans les approches de classification déséquilibrée, que si Recall augmente, Accuracy et AUPRC diminuent.
- L’approche OCC affecte sévèrement l’algorithme en termes d’Accuracy et Recall. Nous pensons que la raison de cette baisse de performance est le phénomène de overfitting des données.
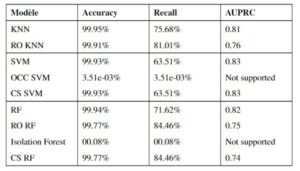
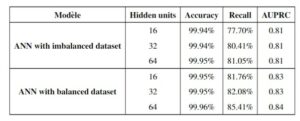
Evaluation du modèle de DL
- Dans le cas du modèle ANN appliqué sur un dataset déséquilibré, l’Accuracy de toutes les architectures est supérieure à 99% avec des taux différents de Recall et approximativement identiques pour AUPRC.
- D’autre part, dans le cas d’un dateset équilibré, les performances augmentent pour les trois métriques.
- Le modèle ANN produit de meilleurs résultats avec l’approche de classification déséquilibrée qui surpassent tous les modèles de ML testés précédemment
Conclusion
Dans cette étude expérimentale, nous avons découvert plusieurs lacunes des méthodes existantes. Nous avons constaté que les approches spécialement conçues pour s’attaquer au problème du déséquilibre ne sont pas suffisamment efficaces. Bien que ces approches améliorent Recall, cette amélioration conduit à une augmentation du nombre de fausses alarmes et donc une baisse de l’Accuracy et de l’AUPRC. D’un point de vue pratique, cela peut être coûteux pour l’institution financière de la même manière qu’un événement frauduleux. Même une détérioration minime de l’Accuracy cache un taux de classification erronée important de l’ensemble des observations. Le problème se résume comme suit : en utilisant des approches de classification déséquilibrée avec des algorithmes de ML, le nombre de fausses alarmes générées est supérieur au nombre de fraudes supplémentaires détectées. Là où les approches de classification déséquilibrée détériorent les performances des modèles de ML, ces performances augmentent pour le modèle de DL. Ce dernier résout le problème de déséquilibre de classes et produit de meilleurs résultats.
Les résultats de cette étude nous ont grandement motivés à explorer d’autres méthodes qui se concentrent sur la détection de fraude, avec un minimum de mauvaises classifications.
Bibliographie
- BANQUE DE FRANCE. (2022). Recensement de la fraude sur les moyens de paiement scripturaux. Banque de France Eurosystème.
- COLLET, F. (2018). DEEP LEARNING with PYTHON. MANNING SHELTER ISLAND.
- DESCAZEAUX, M., COUTURIER, M.& HIMDI, Y. E. (2017). Les nouvelles méthodes de lutte contre la fraude bancaire. Wavestone.
- DSTI. (2022). Le Machine Learning, c’est quoi ? Récupérée 2 août 2022, à partir de https://www.datasciencetech.institute/fr/lexicon/le-machine-learning-cest-quoi/
- HE, H. & GARCIA, E. A. (2009). Learning from imbalanced data. IEEE Transactions on knowledge and data engineering, 21(9), 1263-1284.
- KAMARUDDIN, S. & RAVI, V. (2016). Credit card fraud detection using big data analytics: use of PSOAANN based one-class classification. Proceedings of the international conference on informatics and analytics, 1-8.
- LE GIFRANCE, LE SERVICE PUBLIC DE LA DIFFUSION DU DROIT. (2012). Cour de cassation, civile, Chambre commerciale, 16 octobre 2012, 11-22.993, Publié au bulletin. Récupérée 24 juin 2022, à partir de https://www.legifrance.gouv.fr/juri/id/JURITEXT000026515316
- MAKKI, S., ASSAGHIR, Z., TAHER, Y., HAQUE, R., HACID, M.-S. & ZEINEDDINE, H. (2019). An experimental study with imbalanced classification approaches for credit card frauddetection. IEEE Access, 7, 93010-93022.
- GODOY HILARIO. (2021). Les fraudes bancaires en France – Faits et chiffres. Récupérée 24 Juin 2022, à partir de https://fr.statista.com/themes/3222/les-fraudes-bancaires-enfrance/#topicHeader wrapper
- PADMAJA, T. M., DHULIPALLA, N., BAPI, R. S. & KRISHNA, P. R. (2007). Unbalanced data classification using extreme outlier elimination and sampling techniques for fraud detection. 15th International Conference on Advanced Computing and Communications (ADCOM 2007), 511-516.44
- PHUA, C., ALAHAKOON, D. & LEE, V. (2004). Minority report in fraud detection: classification of skewed data. Acm sigkdd explorations newsletter, 6(1), 50-59.
- WEI,W., LI, J., CAO, L., OU, Y. & CHEN, J. (2013). Effective detection of sophisticated online banking fraud on extremely imbalanced data. World Wide Web, 16(4), 449-475.
Crédits
Évaluation globale
(Pas d'évaluation)(Il n'y a pas encore d'évaluation.)
(Il n'y a pas encore de commentaire.)
- Aucune ressource disponible.

27
Mar
2023