Résumé
Les techniques de détection de connaissances permettent d’améliorer la compréhension de phénomènes croisés. A destination des utilisateurs profanes des statistiques et de la data science, cet article présente une mécanique pour accélérer la détection de diagnostics pertinents pour les métiers, pour la prise de décision.Citation : Chauvin, S. (Sep 2019). Une technique de détection de connaissances par les règles. Management et Datascience, 3(3). https://management-datascience.org/articles/51/. L'auteur : Copyright : © 2019 l'auteur. Publication sous licence Creative Commons CC BY-ND. Liens d'intérêts : Financement : Texte complet
Cet article est issu du data challenge Management & Data Science sur le thème « Service client, innovation et mobilité » sponsorisé par BIP&GO (un des leaders européens du télépéage) en partenariat avec l’Adetem dans le cadre du programme Share Marketing.
Introduction
L’accès aux mesures en grande quantité permet d’avoir la possibilité de détecter des corrélations et des causalités insoupçonnées par les gens des métiers. Dès lors, apparaît le besoin de progresser dans la compréhension des phénomènes naturels et d’activité humaine pour déduire de nouvelles connaissances et savoir-faire. Nul doute que l’avènement du Big Data renforce la capacité de l’humanité à détecter de nouvelles connaissances, celles qui éloignent la décision risquée.
Les termes datamining et Knowledge Discovery sont liés. Ils apparaissent dans les années 1990 et veulent rassembler les techniques statistiques et mathématiques de recherche de modèles sous-jacents dans les données (pattern). Depuis les premières approches et construction d’algorithme adaptés à la détection de connaissances, les travaux des chercheurs et des ingénieurs dans le domaine de la datascience n’ont eu de cesse d’améliorer le processus qui va de la donnée vers la connaissance. Les améliorations vont vers l’accélération de la capacité à détecter des diagnostics dans les données, de permettre à des non-initiés à la data science d’interagir avec les données, d’améliorer la restitution des connaissances dégagées. Pour ce dernier, le résultat idéal d’une étude de DataMining devrait être fourni en langage naturel avec l’idée qu’un interlocuteur puisse répondre à tout, tout le temps (shatbots et autres avatars pour diagnostiquer et interpréter plus vite).
A partir d’une cartographie des données reproductibles dans de nombreux cas d’entreprise, l’approche présentée ici tente d’améliorer la performance des algorithmes de Knowledge Discovery et donne une solution à des non data scientists à la recherche de connaissances dans les données. Nous prenons ici, l’exemple d’une base de données sur les habitudes de personnes quant à leur consommation de produit pour la mobilité.
Cartographie de la nature des données et des besoins
On peut mesurer tous les jours le besoin croissant d’exploiter les masses de données dans tous les domaines. C’est ainsi que les métiers de toute entreprise peuvent être cartographiés sur quatre domaines, deux horizontaux (les flux d’activité et le stock d’activité), deux verticaux (la vision extérieure « marché » de la demande et les moyens à disposition pour répondre aux objectifs de l’offre de l’entreprise (ressource).
Le schéma ci-contre positionne les activités vitales à toute entreprise. Ce sont les métiers de BackOffice (production et procédures techniques par exemple de fours en métallurgie, la résistance des matériaux pour le ferroviaire, la sécurité opérationnelle des trains, qualité des produits, lean management, …), les métiers du commerce (réseau d’agences, activité des sites, réseaux sociaux, vendeurs en démarche, …), les métiers de la gestion des ressources (contrôleurs de gestion, financier, RH, immobilier, …) et les métiers de marché (prix, profils clients, satisfaction, concurrence, communication). Tous les métiers doivent détecter des événements concomitants pour mieux comprendre et agir sur leur choix et ainsi améliorer la performance des actions.
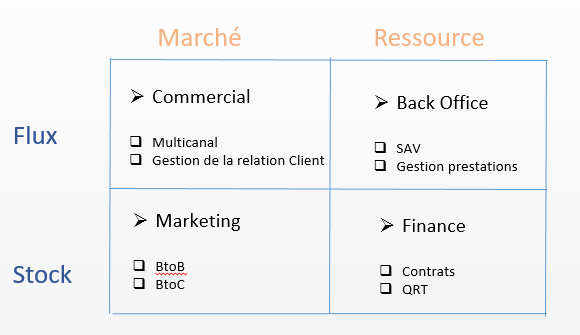
Selon le contexte, un projet d’exploitation des données demandera une capacité de gestion différente. Pour les activités se rapportant aux flux, le nombre de lignes est très imposant (quelques milliards) mais avec peu de profondeur (peu d’axes d’analyse). Les techniques statistiques d’optimisation se rapporteront plus à celles de l’informatique (échantillonnage et agrégation). A l’inverse, pour les activités se rapportant à la vision stock, le nombre de lignes diminue de manière importante (on parle de smart data, quelques millions) mais imposera une gestion de la complexité. On traite souvent sur ces métiers plus de 2000 indicateurs et axes d’analyse générant l’explosion combinatoire des croisements multidimensionnels des critères explicatifs : la data complexité[i]. Les techniques de calcul et de visualisation sont ici mises à rude épreuve.
L’exemple traité dans cet article contient le flux de plus de 10 millions de souscriptions à 6 services pour la mobilité. 5 457 millions de clients ont adhéré à au moins 1 service. Nous traiterons la partie stock du problème : détecter les offres croisées selon 44 caractéristiques qui ont une plus forte propension à être vendues.
De la donnée à la connaissance
Des données, il faut extraire de la connaissance[ii]. La connaissance est le fait de comprendre et d’appréhender des traits et les spécificités de l’environnement de l’étude. La mécanique de détection de corrélations, une première étape vers la connaissance, permet de circonscrire ce que les données révèlent d’important. Ainsi, les techniques d’arbres de décision [iii] dans la catégorie des statistiques descriptives et celles toutes particulières des forêts d’arbres (random forest), ouvrent la voie à la détection de connaissances par des règles (un pattern) à plusieurs dimensions. Le résultat de la découverte d’une règle est probante selon les 4 critères : vérifiée utile par les métiers, robuste au changement d’échantillons des données, pure en fonction du reste des données (la règle contraire – la contraposée – est fausse), profondeur hors sur-apprentissage (loi des grands nombres).
Ainsi, dans tous les croisements des données possibles (surtout dans le cas du stock, voir ci-dessus), il s’agit de détecter celle qui a une probabilité élevée de répondre favorablement aux 4 critères.
La modélisation par les probabilités de Kullback Leibler est appropriée au sujet. Ces probabilités sont telles que :
- P(Φ(x, y)) = exp(-N.H(P))
où P est la distribution empirique multidimensionnelle, H(P) est le taux d’information de la distribution P (Shannon Entropie[i]) et la fonction Φ estimée comme une distribution du chi-deux[ii] d’une règle détectée dans les données. Ainsi, afin d’améliorer la performance de la détection de connaissances dans les données, il s’agit de calculer les règles possibles et d’en extraire celles qui ont une probabilité élevée.
Les arbres calculés sont autant de règles qu’il y a des chemins dans le graphe. Pour chacune, la probabilité (1) est calculée. La technique utilisée consiste ainsi à donner aux experts métier les moyens de poser des questions sur les données (multidimensionnelles) et d’observer si la réponse est probante. Les connaissances intuitives et a priori des experts, accélèrent la détection de connaissances avec un fort ROI métier. L’ajout de critères imaginés par les métiers améliore la connaissance.
Ainsi, on passe des données à la connaissance, par l’action des sachants métiers sur leurs données et leur périmètre de décision.
Illustration
Dans le cadre de l’expérimentation sur la mobilité, on mesure le nombre de services par client. Le premier comptage montre dans le tableau ci-dessous, que 3 personnes ont souscrit à 1 seul service mais que plus de 528 mille personnes ont souscrit à 6 services. La question que l’on se pose est alors de reconnaître les personnes clones de ces dernières qui peuvent être sollicitées sur les autres services.
N° de service Idx 1 3 2 30072 3 974 4 16542 6 528438 7 109970 0 522733 En utilisant les techniques de random forest, et la technologie MyDataBall qui consulte les corrélations-causalités (détection des règles modus ponens et vérifiés comme modus tollens : vérification de la probabilité d’une causalité), les projets de calcul ont tenté de détecter les règles multidimensionnelles qui expliquent le nombre de services et le prix par clients.
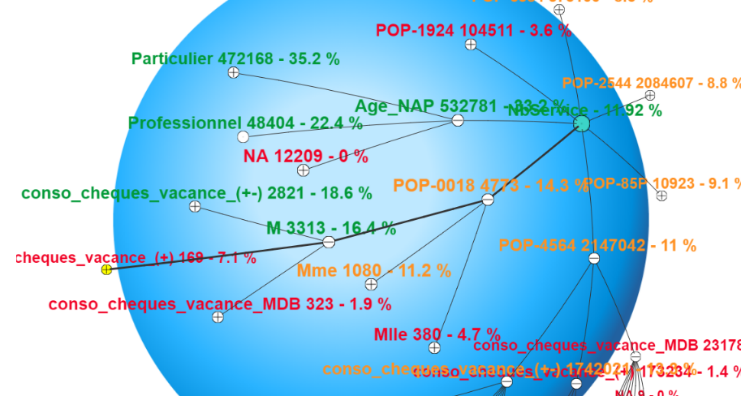
En utilisant ici la visualisation multidimensionnelle sphérique propre à MyDataBall et un jeu de couleur par seuil, immédiatement, les règles apparaissent selon leur pertinence.
L’âge, la typologie client (particulier ou professionnel), le genre et conso chèques vacances déterminent fortement la structure de la propension à souscrire à un nombre élevé de service (à droite, des règles vertes à forte probabilité de causalités).
Les règles détectées à forte probabilité d’augmenter le nombre de services sont résumées ici :
Les mineurs garçons augmentent le nombre de services, les dames de plus de 45 ans, les demoiselles entre 45 et 65. A noter que les genres autres (professions supérieures) ont un très bon niveau d’achat.
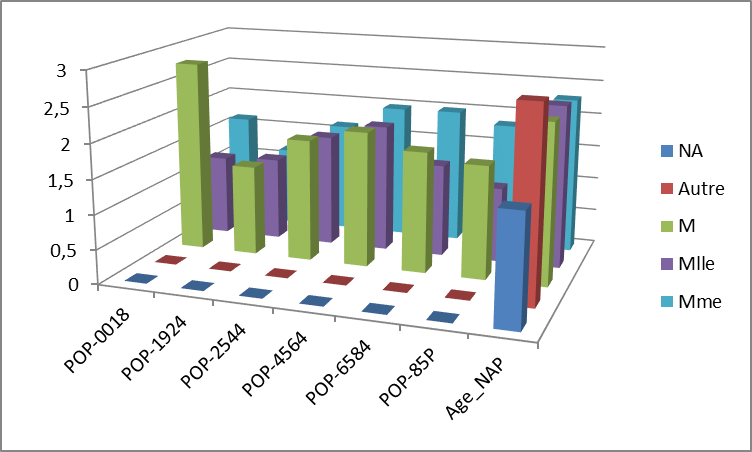
Ainsi, en multipliant des recherches de croisement possible sur les 44 variables possibles (1013 possibilités), des règles peuvent alimenter la réflexion des sachants métiers. Par exemples, ces 2 règles détectées à forte valeur décisionnelle pour l’indicateur :
Prix de opportunité >= 310€
(1)Pureté = 0.59, Pureté marginale = 0.22 : ( [NbBadges] = NbBadges_1 ) ET ( [FrequenceAbo] = Annuel ) ET ( [Compatible-Espagne] = Non ) (2)Pureté = 0.61, Pureté marginale = 0.21 : ( [NbBadges] = NbBadges_1 ) ET ( [ModeLivraison] = Livraison sous 48h ) ET ( [FrequenceAbo] = Annuel ) ET ( [Compatible-Espagne] = Non )
Le fait de la non présence de chèques vacances est un élément qui fait augmenter la consommation de services[1].
Conclusion
La détection de règles pour la prise de décision est l’objet du Knowledge Discovery. Primordiale pour améliorer et approfondir les connaissances, lorsqu’elles sont détectées par les métiers, elles en auront d’autant plus de valeur. L’approche et la solution MyDataBall présentée sur les données de BIP&GO est industrialisée et permet au fur et à mesure des retours d’activités, de prédire et prescrire des évolutions du parc des clients.
L’aspect pratique et simple d’une telle méthodologie permet d’accélérer la détection de connaissances. En outre, elle ouvre la porte aux nouveaux modes de consommation de données : dans un mode industrielle, le calcul à fréquence élevée des règles, simplifie la lecture des tableaux de bord à regarder pour la prise de décision. Ce ne sont plus les hommes qui vont lire les tableaux de bord, mais les bons tableaux de bord qui vont vers les bonnes personnes (vers le Knowledge Management).
Ainsi, le calcul des arborescences contribue à engranger des connaissances pilotées par les sachants métier et constituent un type de machines learning qui à tout moment peuvent être interrogées en temps réel.
De manière générale, le résultat idéal d’une étude devrait être celui d’une machine qui répondrait à une question. Cela est possible par la détection de règles qui peuvent être reproduites en langage naturelle. Ainsi, le sujet est d’améliorer la prise de décision par le calcul intensif et la validation des sachant métiers pour dérouler les actions pour les entreprises. Le sujet est alors de trouver les meilleures formes de restitution des règles détectées pour un usage facile et efficace.
[1] Ces résultats ont été obtenus alors que de nombreuses données ne sont pas renseignées. Un travail préalable pourrait améliorer les résultats en estimant les valeurs manquantes par des régressions de type logistique.
[i] Le Big Data pour valoriser les compétences, Jean-Baptiste Igonetti, Stéphane Chauvin, mai 2017, Revue management & datascience, https://management-datascience.org/2017/06/17/le-big-data-pour-valoriser-les-competences/
[i] L’incertitude en marketing, Stéphane Chauvin, Novembre 2006, Angers, revue RNTI.
[ii] J-F Bercher, G. Le Besnerais and G. Demoment, The Maximum Entropy on the Mean Method, Noise and Sensibility, 14th Coll. Maximum Entropy and Bayesian Methods, Cambridge University Press (Cambridge) 1994.
Évaluation globale
(Pas d'évaluation)(Il n'y a pas encore d'évaluation.)
(Il n'y a pas encore de commentaire.)
- Aucune ressource disponible.

15
Sep
2019
Une technique de détection de connaissances par les règles
Stéphane Chauvin
MCEInvité
CEO • MyDataBall