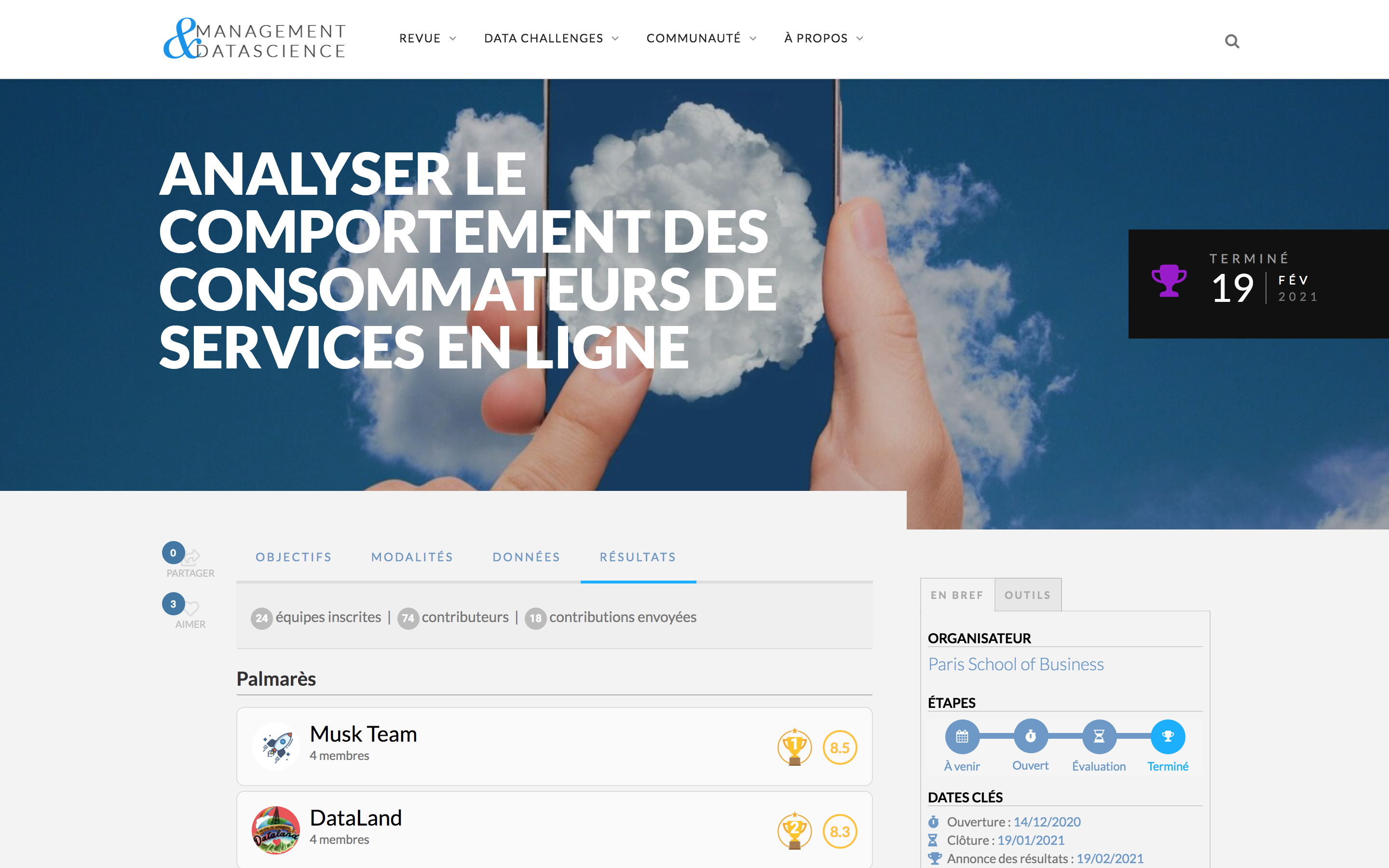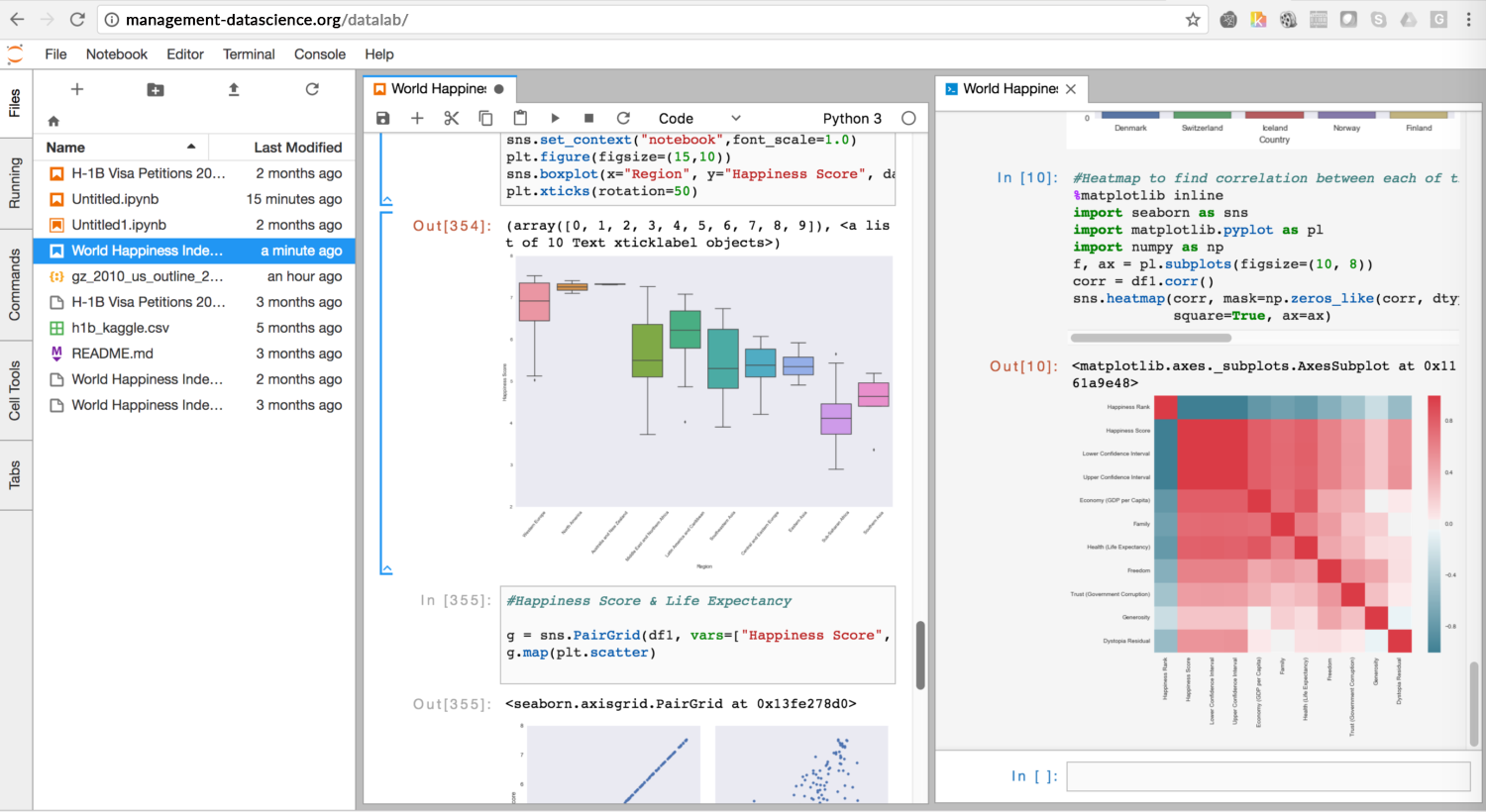

Explorez un espace de recherche ouvert et utile
La revue scientifique publie des connaissances pour comprendre la transformation numérique des entreprises et l’impact du big data sur le management.
Les articles abordent la recherche théorique, ses applications, la discussion sur les enjeux actuels ou des cas d’application en entreprise.

Trouvez des partenaires et échangez sur vos projets
La valeur de la communauté est dans la qualité de ses membres : compétiteurs, auteurs, formateurs… Que vous soyez simple membre, contributeur ou expert, vous trouverez les interlocuteurs pour répondre à vos besoins.
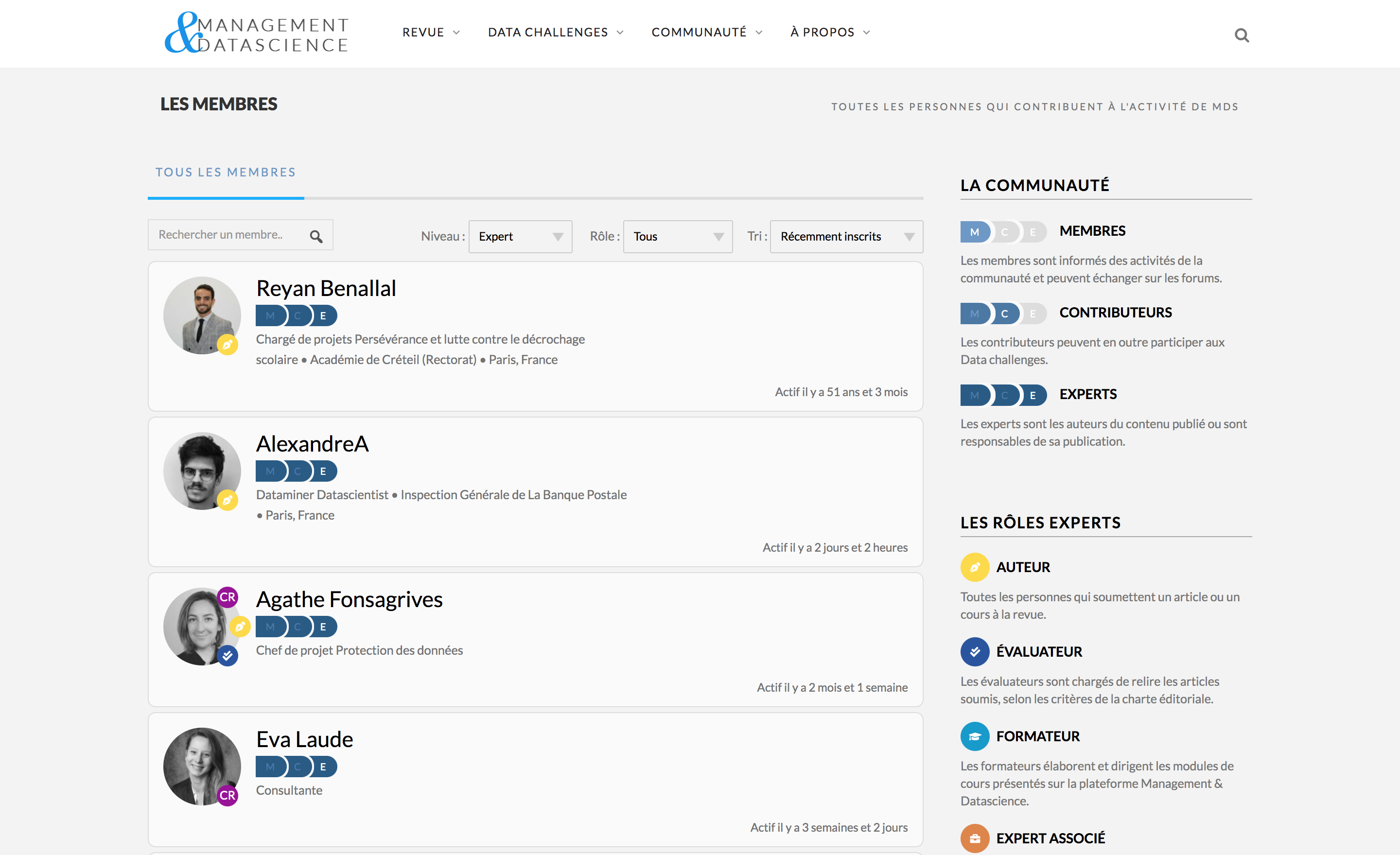
Vous pouvez identifier les membres, organisations ou équipes formées, avec leur activité.
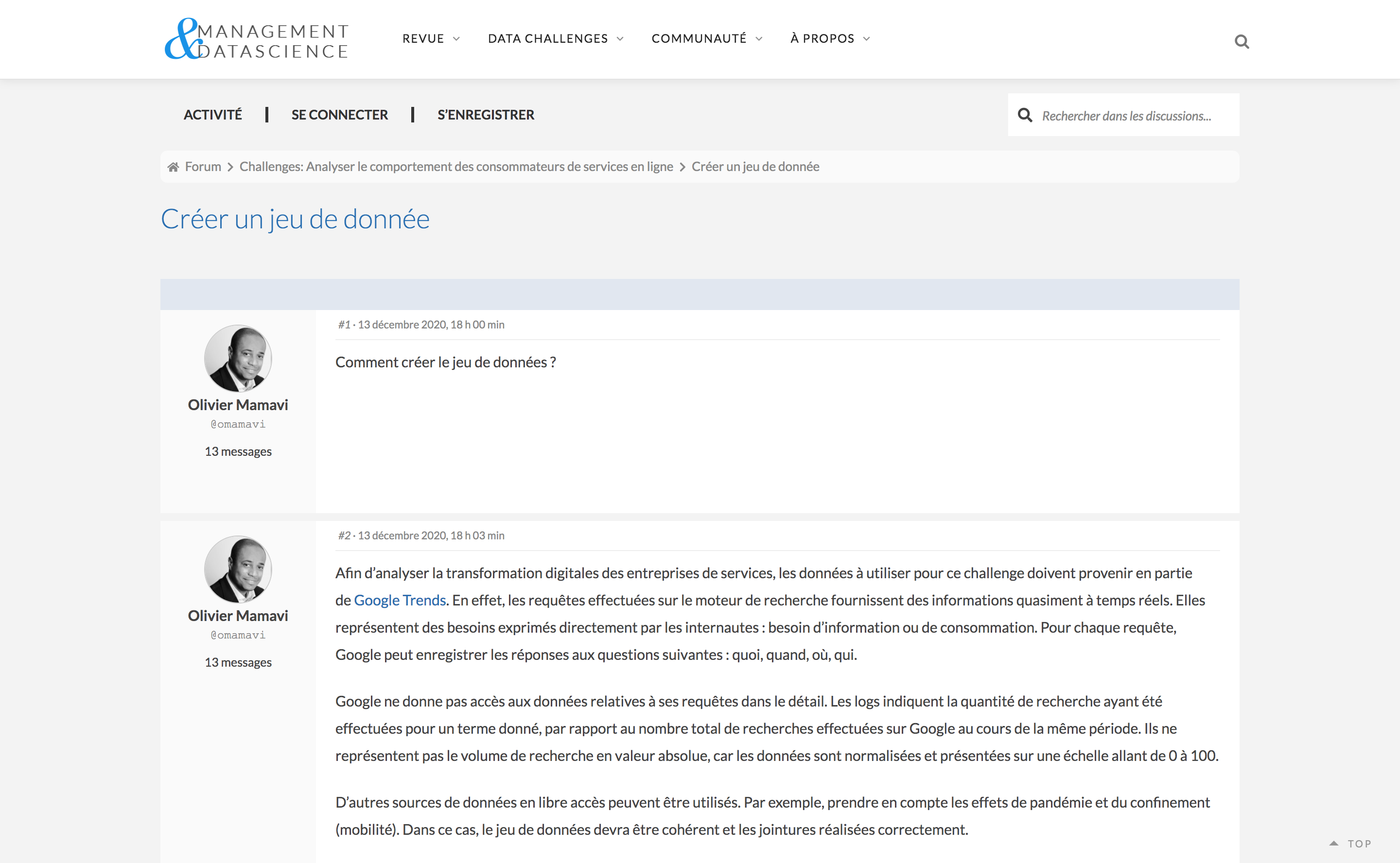
Utilisez les discussions pour poser vos questions, proposer un problème ou interpeller un expert.